


聊一聊Python与网络爬虫。
1、爬虫的定义
爬虫:自动抓取互联网数据的程序。
2、爬虫的主要框架
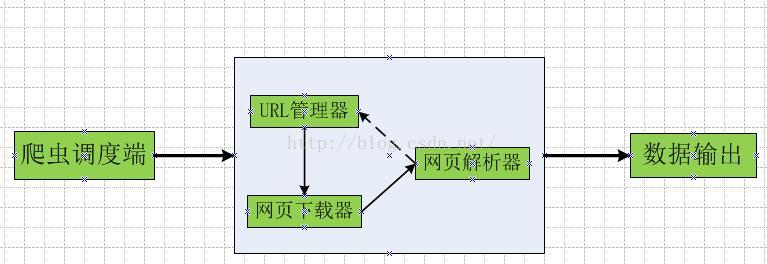
爬虫程序的主要框架如上图所示,爬虫调度端通过URL管理器获取待爬取的URL链接,若URL管理器中存在待爬取的URL链接,爬虫调度器调用网页下载器下载相应网页,然后调用网页解析器解析该网页,并将该网页中新的URL添加到URL管理器中,将有价值的数据输出。
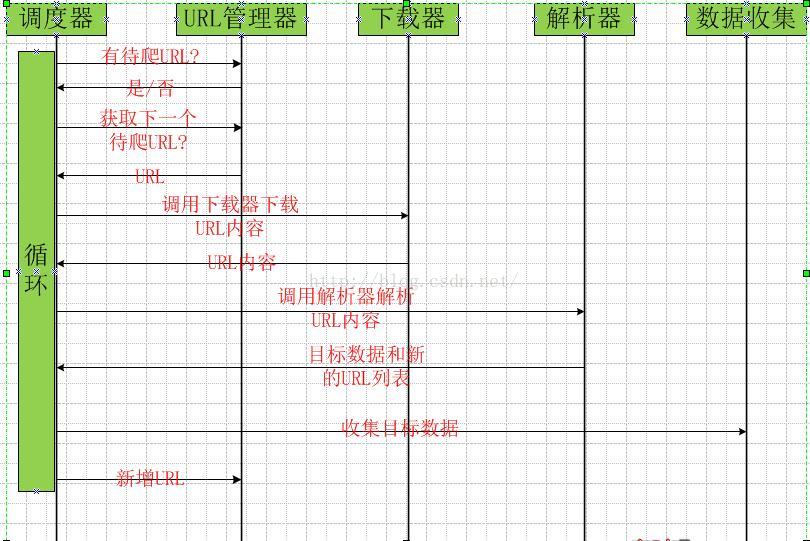
3、爬虫的时序图
4、URL管理器
URL管理器管理待抓取的URL集合和已抓取的URL集合,防止重复抓取与循环抓取。URL管理器的主要职能如下图所示:

URL管理器在实现方式上,Python中主要采用内存(set)、和关系数据库(MySQL)。对于小型程序,一般在内存中实现,Python内置的set()类型能够自动判断元素是否重复。对于大一点的程序,一般使用数据库来实现。
5、网页下载器
Python中的网页下载器主要使用urllib库,这是python自带的模块。对于2.x版本中的urllib2库,在python3.x中集成到urllib中,在其request等子模块中。urllib中的urlopen函数用于打开url,并获取url数据。urlopen函数的参数可以是url链接,也可以使request对象,对于简单的网页,直接使用url字符串做参数就已足够,但对于复杂的网页,设有防爬虫机制的网页,再使用urlopen函数时,需要添加http header。对于带有登录机制的网页,需要设置cookie。
6、网页解析器
网页解析器从网页下载器下载到的url数据中提取有价值的数据和新的url。对于数据的提取,可以使用正则表达式和BeautifulSoup等方法。正则表达式使用基于字符串的模糊匹配,对于特点比较鲜明的目标数据具有较好的作用,但通用性不高。BeautifulSoup是第三方模块,用于结构化解析url内容。将下载到的网页内容解析为DOM树,下图为使用BeautifulSoup打印抓取到的百度百科中某网页的输出的一部分。

关于BeautifulSoup的具体使用,在以后的文章中再写。下面的代码使用python抓取百度百科中英雄联盟词条中的其他与英雄联盟相关的词条,并将这些词条保存在新建的excel中。上代码:
from bs4 import BeautifulSoup
import re
import xlrd
<span style="font-size:18px;">import xlwt
from urllib.request import urlopen
excelFile=xlwt.Workbook()
sheet=excelFile.add_sheet('league of legend')
## 百度百科:英雄联盟##
html=urlopen("http://baike.baidu.com/subview/3049782/11262116.htm")
bsObj=BeautifulSoup(html.read(),"html.parser")
#print(bsObj.prettify())
row=0
for node in bsObj.find("div",{"class":"main-content"}).findAll("div",{"class":"para"}):
links=node.findAll("a",href=re.compile("^(/view/)[0-9]+\.htm$"))
for link in links:
if 'href' in link.attrs:
print(link.attrs['href'],link.get_text())
sheet.write(row,0,link.attrs['href'])
sheet.write(row,1,link.get_text())
row=row+1
excelFile.save('E:\Project\Python\lol.xls')</span>
输出的部分截图如下:

excel部分的截图如下:

以上就是本文的全部内容,希望对大家学习Python网络爬虫有所帮助。

 Python是否列表動態陣列或引擎蓋下的鏈接列表?May 07, 2025 am 12:16 AM
Python是否列表動態陣列或引擎蓋下的鏈接列表?May 07, 2025 am 12:16 AMpythonlistsareimplementedasdynamicarrays,notlinkedlists.1)他們areStoredIncoNtiguulMemoryBlocks,mayrequireRealLealLocationWhenAppendingItems,EmpactingPerformance.2)LinkesedlistSwoldOfferefeRefeRefeRefeRefficeInsertions/DeletionsButslowerIndexeDexedAccess,Lestpypytypypytypypytypy
 如何從python列表中刪除元素?May 07, 2025 am 12:15 AM
如何從python列表中刪除元素?May 07, 2025 am 12:15 AMpythonoffersFourmainMethodStoreMoveElement Fromalist:1)刪除(值)emovesthefirstoccurrenceofavalue,2)pop(index)emovesanderturnsanelementataSpecifiedIndex,3)delstatementremoveselemsbybybyselementbybyindexorslicebybyindexorslice,and 4)
 試圖運行腳本時,應該檢查是否會遇到'權限拒絕”錯誤?May 07, 2025 am 12:12 AM
試圖運行腳本時,應該檢查是否會遇到'權限拒絕”錯誤?May 07, 2025 am 12:12 AMtoresolvea“ dermissionded”錯誤Whenrunningascript,跟隨台詞:1)CheckAndAdjustTheScript'Spermissions ofchmod xmyscript.shtomakeitexecutable.2)nesureThEseRethEserethescriptistriptocriptibationalocatiforecationAdirectorywherewhereyOuhaveWritePerMissionsyOuhaveWritePermissionsyYouHaveWritePermissions,susteSyAsyOURHomeRecretectory。
 與Python的圖像處理中如何使用陣列?May 07, 2025 am 12:04 AM
與Python的圖像處理中如何使用陣列?May 07, 2025 am 12:04 AMArraysarecrucialinPythonimageprocessingastheyenableefficientmanipulationandanalysisofimagedata.1)ImagesareconvertedtoNumPyarrays,withgrayscaleimagesas2Darraysandcolorimagesas3Darrays.2)Arraysallowforvectorizedoperations,enablingfastadjustmentslikebri
 對於哪些類型的操作,陣列比列表要快得多?May 07, 2025 am 12:01 AM
對於哪些類型的操作,陣列比列表要快得多?May 07, 2025 am 12:01 AMArraySaresificatificallyfasterthanlistsForoperationsBenefiting fromDirectMemoryAcccccccCesandFixed-Sizestructures.1)conscessingElements:arraysprovideconstant-timeaccessduetocontoconcotigunmorystorage.2)iteration:araysleveragececacelocality.3)
 說明列表和數組之間元素操作的性能差異。May 06, 2025 am 12:15 AM
說明列表和數組之間元素操作的性能差異。May 06, 2025 am 12:15 AMArraySareBetterForlement-WiseOperationsDuetofasterAccessCessCessCessCessCessCessCessAndOptimizedImplementations.1)ArrayshaveContiguucuulmemoryfordirectAccesscess.2)列出sareflexible butslible butslowerduetynemicizing.3)
 如何有效地對整個Numpy陣列進行數學操作?May 06, 2025 am 12:15 AM
如何有效地對整個Numpy陣列進行數學操作?May 06, 2025 am 12:15 AM在NumPy中进行整个数组的数学运算可以通过向量化操作高效实现。1)使用简单运算符如加法(arr 2)可对数组进行运算。2)NumPy使用C语言底层库,提升了运算速度。3)可以进行乘法、除法、指数等复杂运算。4)需注意广播操作,确保数组形状兼容。5)使用NumPy函数如np.sum()能显著提高性能。
 您如何將元素插入python數組中?May 06, 2025 am 12:14 AM
您如何將元素插入python數組中?May 06, 2025 am 12:14 AM在Python中,向列表插入元素有兩種主要方法:1)使用insert(index,value)方法,可以在指定索引處插入元素,但在大列表開頭插入效率低;2)使用append(value)方法,在列表末尾添加元素,效率高。對於大列表,建議使用append()或考慮使用deque或NumPy數組來優化性能。


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

SublimeText3 Linux新版
SublimeText3 Linux最新版

Dreamweaver Mac版
視覺化網頁開發工具

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

