


linux下通过mysqldump备份mysql数据库成sql文件阶段1:傻瓜式全备份mysqldump-hip地址-uusername-ppassword-A~/name.sql此种情况将整个数据库(结构和数据)导出备
linux下通过mysqldump备份mysql数据库成sql文件
阶段1:傻瓜式全备份
mysqldump -h ip地址 -uusername -ppassword -A >~/name.sql
此种情况将整个数据库(结构和数据)导出备份成一个sql文件
-----------------------------------------------------------------------------------------------------------------------------------------------
阶段2:适当的调整参数达到不同的备份效果
我们先help一下
mysqldump --help
由于help输出过多就不一一列举出来了
通过远程连接备份
-h 需要备份服务器的地址
-u 允许远程连接的账号
-p允许远程连接账号的密码
-A 全备份
常用参数的说明
-A, --all-databases 备份所有数据库
--add-drop-database 在每个create database 语句之前增加一个drop database。
--add-drop-table 在每个create table 语句之前增加一个drop table。
--add-locks 在每个表导出之前增加LOCK TABLES并且之后UNLOCK TABLE。(为了使得更快地插入到MySQL)
--default-character-set=name 设置导出数据的字符集
--opt 同--quick --add-drop-table --add-locks --extended-insert --lock-tables。应该给你为读入一个MySQL服务器的尽可能最快的导出。
-e, --extended-insert 使用全新多行INSERT语法。(给出更紧缩并且更快的插入语句)。生成的文件insert语句中回事批量的,提高导入时的速度
--hex-blob 使用十六进制格式导出二进制字符串字段。如果有二进制数据就必须使用本选项。影响到的字段类型有 BINARY、VARBINARY、BLOB。
--quick,-q 该选项在导出大表时很有用,它强制 mysqldump 从服务器查询取得记录直接输出而不是取得所有记录后将它们缓存到内存中
-t, --no-create-info 只导出数据
-d, --no-data 只导出结构
----------------------------------------------------------------------------------------------------------------------------------------------
阶段3:备份制定定数据库和制定数据库的某个表
mysqldump -h ip地址 -uusername -ppassword databasename >~/name.sql
mysqldump -h ip地址 -uusername -ppassword databasename tablename >~/name.sql
----------------------------------------------------------------------------------------------------------------------------------------------
阶段4.1:
通过读取文本来分库备份数据库成不同的sql文件
例如我们分别有数据库db1 db2 db3 db4 db5。。。。。。db100当我们每个库数据量都不小的时候需要按数据库分别备份,
我们也不可能100个库分别写成100个备份的脚本运行,这样我们就需要结合shell脚本中的循环语句来操作
cat filename.txt |while read i
do
备份脚本,例如:mysqldump -h ip地址 -uusername -ppassword $i >~/name.sql
done
其中filename.txt中保存数据库的库名,每行一个。
通过这样的做法再结合linux的crond服务我们就可以自动备份了
阶段4.2
如果需要分库分表备份那该这么办呢
这时候做法和分库的时候一样,分别按每个库生成相应表的表明文件一行一个分别命名为db1.txt db2.txt db3.txt db4.txt db5.txt。。。。。。。db100.txt
通过两次循环分别进行分库分表的备份
cat filename.txt |while read i
do
mkdir $i
cat $i.txt|while read a
do
备份脚本,例如:mysqldump -h ip地址 -uusername -ppassword $i $a >$i/$a.sql
done
done
当然我们有时候需要记录下备份的时间
fn=$(date +"%Y-%m-%d_%H:%M")
cat filename.txt |while read i
do
mkdir $i
cat $i.txt|while read a
do
备份脚本,美国空间,例如:mysqldump -h ip地址 -uusername -ppassword $i $a >$i/$a$fn.sql
done
done
--------------------------------------------------------------------------------------------------------------------------------------------------
阶段5:
经过第4阶段之后我们的备份更加细致,那部分的数据出问题我们就恢复那部分的(虽然颗粒度还是有些粗)
但是我们是不是觉得第4阶段的备份还是很复杂,例如我们存库名和表明的文件就是一个庞大的工程,美国服务器,新建库我们得在库文件中添加一行
新建表我们得到某个库下面的表的文件中添加一条,这样既繁琐又容易出错,而且容易忘记,维护起来很麻烦。
现在我们有个办法可以让他自动列出库和库下的表
mysql -e
执行
mysql -e "show databases"
得到如下结果
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
但是这样的结果我们没法用,所需要去掉外围的条条框框的东西
mysql -e "show databases"|sed '1d'
information_schema
mysql
performance_schema
test
for db in `mysql -e "show databases"|sed '1d'`
do
备份脚本,例如:mysqldump -h ip地址 -uusername -ppassword $db >name.sql
done
参照这个我们同样可以分库分表备份
mysql databasename -e "show tables"|sed '1d'
fn=$(date +"%Y-%m-%d_%H:%M")
for db in `mysql -e "show databases"|sed '1d'`
do
mkdir $db
for tables in `mysql $db -e "show tables"|sed '1d'`
do
备份脚本,例如:mysqldump -h ip地址 -uusername -ppassword $db $tables >$db/$tables$fn.sql
done
done
暂且完毕,请多指正,美国服务器,如有其它更好方式请留言,一起进步
本文出自 “天马行空” 博客,请务必保留此出处

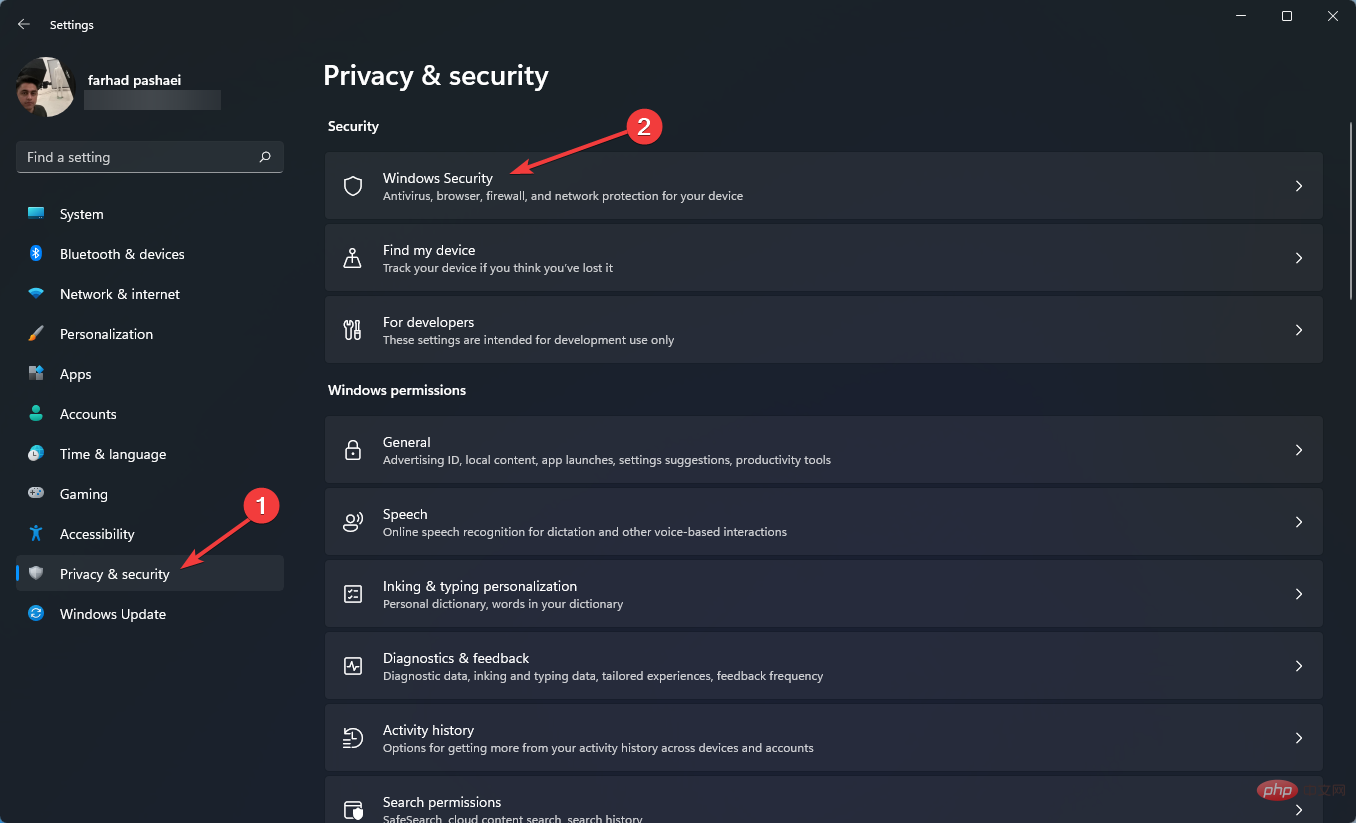 这就是修复 Windows 11 的 WSL 错误的方法May 03, 2023 pm 07:19 PM
这就是修复 Windows 11 的 WSL 错误的方法May 03, 2023 pm 07:19 PMWindows11中的WSL错误可能由于多种原因而发生。确切的消息是WslRegisterDistributionFailed并带有不同的错误代码。适用于Linux的Windows子系统(WSL)是一项允许开发人员和典型用户在其Windows计算机上安装和使用Linux的功能。尽管此功能对开发人员非常有价值,但它有时会导致难以修复的令人难以置信的复杂情况。幸运的是,这些错误并非不可克服。在这篇文章中,我们将讨论所有可能的原因和解决方案。Windows11中最常见的W
 如何在 Windows 10 或 11 WSL 上安装 Oracle Linux – 子系统Apr 14, 2023 pm 10:07 PM
如何在 Windows 10 或 11 WSL 上安装 Oracle Linux – 子系统Apr 14, 2023 pm 10:07 PM在Windows10上安装OracleLinux8或7.5的步骤|11WSL1.启用WSL–Windows子系统Linux我们需要拥有的第一件事是WSL,如果尚未启用它,请启用它。转到搜索框并输入–打开或关闭Windows功能。在选项出现时,单击以打开相同。在打开的窗口中,向下滚动并选择为Linux的Windows子系统提供的框。然后单击确定按钮。之后重新启动系统以应用更改。2.在Windows11或10上下载OracleLinx8或
 在 Windows 上运行 shell 脚本文件的不同方法Apr 13, 2023 am 11:58 AM
在 Windows 上运行 shell 脚本文件的不同方法Apr 13, 2023 am 11:58 AM适用于 Linux 的 Windows 子系统第一种选择是使用适用于 Linux 或 WSL 的 Windows 子系统,这是一个兼容层,用于在 Windows 系统上本地运行 Linux 二进制可执行文件。它适用于大多数场景,允许您在 Windows 11/10 中运行 shell 脚本。WSL 不会自动可用,因此您必须通过 Windows 设备的开发人员设置启用它。您可以通过转到设置 > 更新和安全 > 对于开发人员来完成。切换到开发人员模式并通过选择是确认提示。接下来,查找 W
 想在 Windows 11 上安装 AlmaLinux?这是怎么做的Apr 30, 2023 pm 08:13 PM
想在 Windows 11 上安装 AlmaLinux?这是怎么做的Apr 30, 2023 pm 08:13 PM在MicrosoftStore中,现在有一个版本的AlmaLinux与适用于Linux的Windows子系统兼容。这为用户提供了一系列令人印象深刻的新选项,因此我们将向您展示如何在Windows11上安装AlmaLinux。它于2021年3月发布,提供了第一个稳定的生产版本,此后该非营利基金会增加了许多新成员。最近的AMD是上个月加入的,时间是2022年3月。借助适用于Linux的Windows子系统,在Windows和Linux世界中工作的开
 linux中acpi是什么意思Jun 01, 2023 pm 04:03 PM
linux中acpi是什么意思Jun 01, 2023 pm 04:03 PMlinux中acpi是“Advanced Configuration and Power Interface”的缩写,意思是高级配置与电源管理接口,这是微软、英特尔和东芝共同开发的一种工业标准。ACPI是提供操作系统与应用程序管理所有电源管理接口,包括了各种软件和硬件方面的规范。
 Linux系统中的服务优化指南Jun 18, 2023 pm 02:32 PM
Linux系统中的服务优化指南Jun 18, 2023 pm 02:32 PM随着Linux操作系统在企业中的广泛应用,对其服务的优化需求越来越高。本文将介绍Linux系统中常见的服务优化指南,以帮助企业更好地运维和管理Linux系统。禁止不必要的服务Linux系统中预装了许多服务程序,其中一些可能不会被企业所使用。禁止不必要的服务可以降低系统资源的消耗,并减少系统的安全漏洞。例如,企业如果不需要用到FTP服务,可以通过禁用FTP服务
 Linux系统中的软件包管理指南Jun 18, 2023 pm 12:55 PM
Linux系统中的软件包管理指南Jun 18, 2023 pm 12:55 PM作为开源操作系统的代表,Linux系统在软件包管理方面表现出众,多种包管理工具也让用户有更多的选择。本文将为大家介绍Linux系统中的软件包管理指南,帮助用户更好地管理自己的软件包。常用软件包管理工具Linux系统中常用的软件包管理工具有dpkg,rpm,pacman,yum等。dpkgdpkg是DebianLinux系统中常用的包管理工具,它负责安
 Linux系统中的日志文件管理指南Jun 18, 2023 am 10:44 AM
Linux系统中的日志文件管理指南Jun 18, 2023 am 10:44 AM在Linux系统中,日志文件是非常重要的,它记录了系统各种事件的发生情况,是系统管理员进行故障排查和监控的必备资源。而对于日志文件的管理也是非常重要的,只有正确的管理方式才能有效地利用日志文件,从而保障系统的安全和正常运行。本文就为大家介绍一些Linux系统下的日志文件管理指南,包括日志文件的基本概念、日志文件的类型、日志文件的管理以及常用的日志查看工具等内


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

Dreamweaver CS6
視覺化網頁開發工具

禪工作室 13.0.1
強大的PHP整合開發環境

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

Atom編輯器mac版下載
最受歡迎的的開源編輯器

