



Kafka是一个消息系统,由LinkedIn贡献给Apache基金会,称为Apache的一个顶级项目。Kafka最初用作LinkedIn的活动流(activity stream)和运营数据处理管道(pipeline)的基
Kafka是一个消息系统,由LinkedIn贡献给Apache基金会,称为Apache的一个顶级项目。Kafka最初用作LinkedIn的活动流(activity stream)和运营数据处理管道(pipeline)的基础。它具有可扩展、吞吐量大和可持久化等特征,以及非常好的分区、复制和容错特征。
Kafka的关键设计决策
1). Kafka在设计之时为就将持久化消息作为通常的使用情况进行了考虑。
2). Kafka主要的设计约束是吞吐量,而不是功能。
3). Kafka有关哪些数据已经被使用了的状态信息保存为数据使用者(consumer)的一部分,而不是保存在服务器之上。
4). Kafka是一种显式的分布式系统。它假设,数据生产者(producer)、代理(brokers)和数据使用者(consumer)分散于多台机器之上。
而相比而言,传统的消息队列不能很好的支持(如超长的未处理数据、不能有效持久化)。对于数据的可用性,Kafka提供了两个保证:
(1). 生产者发送到Topic的分区上消息将会按照它们发送的顺序,而消费者收到的消息也是此顺序
(2). 如果一个Topic配置了复制因子( replication facto)为N, 那么可以允许N-1服务器当掉而不丢失任何已经增加的消息
Kafka中几个关键术语
Topic:Kafka将消息种子(Feed)分门别类, 每一类的消息称之为话题(Topic).
Producer:发布消息的对象称之为话题生产者(Kafka topic producer)
Consumer:订阅消息并处理发布的消息的种子的对象称之为话题消费者(consumers)
Broker:已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker). 消费者可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息。
Kafka中的Topic

Topic是发布的消息的类别或者种子Feed名。对于每一个Topic, Kafka集群维护这一个分区的log,就像下图中的示例:Kafka集群
每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。分区中的消息都被分配了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。
Kafka集群保持所有的消息,直到它们过期,无论消息是否被消费了。
实际上消费者所持有的仅有的元数据就是这个偏移量,也就是消费者在这个log中的位置。 这个偏移量由消费者控制:正常情况当消费者消费消息的时候,偏移量也线性的的增加。但是实际偏移量由消费者控制,消费者可以将偏移量重置为更老的一个偏移量,重新读取消息。
可以看到这种设计对消费者来说操作自如, 一个消费者的操作不会影响其它消费者对此log的处理。
再说说分区。Kafka中采用分区的设计有几个目的。
一、可以处理更多的消息,不受单台服务器的限制。Topic拥有多个分区意味着它可以进行扩展,并处理更多的数据。
二、分区可以作为并行处理的单元。
Topic的分区Log被分布到集群中的多个服务器上。每个服务器处理它持有的分区。 根据配置每个分区还可以复制到其它服务器作为备份容错。
每个分区有一个leader,零或多个replica。Leader处理此分区的所有的读写请求而replica被动的复制数据。如果leader当机,其它的一个replica会被推举为新的leader。
一台服务器可能同时是一个分区的leader,另一个分区的replica。 这样可以平衡负载,避免所有的请求都只让一台或者某几台服务器处理。
关于复制原理,参考下面官档翻译:
Kafka 的集群复制设计
Kafka的集群部署
Kafka中主要有三种模式,
单机broker模式
单机多broker模式(伪分布式)
多机多broker模式(集群)
和hadoop一样,前两种多用于开发测试。第三种才是实际生产中可用的部署模式,下面介绍一下三节点kafka集群的部署流程
软件的安装直接解压缩即可:
tar xzvf kafka_2.10-0.8.1.1.tgz mkdir /var/kafka && mkdir /var/zookeeper
关键参数的解释,可以参考http://debugo.com/kafka-params/
vim kafka_2.10-0.8.1.1/config/server.properties
#在默认的配置上,我只修改了3个地方。三个主机debugo01,debugo02,debugo03分别对应id为1,2,3 broker.id=3 log.dirs=/var/kafka zookeeper.connect=debugo01:2181,debugo02:2181,debugo03:2181 配置zookeeper,修改DataDir并加入集群参数 vim kafka_2.10-0.8.1.1/config/zookeeper.properties initLimit=5 syncLimit=2 server.1=debugo01:2888:3888 server.2=debugo02:2888:3888 server.3=debugo03:2888:3888 dataDir=/var/zookeeper #分别将1,2,3写入三个主机的myid文件 echo "1" >> /var/zookeeper/myid
在debugo01,debugo02,debugo03上分别启动zookeeper和kafka Server
bin/zookeeper-server-start.sh config/zookeeper.properties # 启动kafka Server bin/kafka-server-start.sh config/server.properties
这时可以在log中找到,新的broker已经将数据注册到znode中。
#####debugo01#####
[2014-12-07 20:54:20,506] INFO Awaiting socket connections on debugo01:9092. (kafka.network.Acceptor)
[2014-12-07 20:54:20,521] INFO [Socket Server on Broker 1], Started (kafka.network.SocketServer)
[2014-12-07 20:54:20,649] INFO Will not load MX4J, mx4j-tools.jar is not in the classpath (kafka.utils.Mx4jLoader$)
[2014-12-07 20:54:20,725] INFO 1 successfully elected as leader (kafka.server.ZookeeperLeaderElector)
[2014-12-07 20:54:20,876] INFO Registered broker 1 at path /brokers/ids/1 with address debugo01:9092. (kafka.utils.ZkUtils$)
[2014-12-07 20:54:20,907] INFO [Kafka Server 1], started (kafka.server.KafkaServer)
[2014-12-07 20:54:20,993] INFO New leader is 1 (kafka.server.ZookeeperLeaderElector$LeaderChangeListener)
#####debugo02#####
[2014-12-07 20:54:35,896] INFO Awaiting socket connections on 0.0.0.0:9092. (kafka.network.Acceptor)
[2014-12-07 20:54:35,913] INFO [Socket Server on Broker 2], Started (kafka.network.SocketServer)
[2014-12-07 20:54:36,073] INFO Will not load MX4J, mx4j-tools.jar is not in the classpath (kafka.utils.Mx4jLoader$)
[2014-12-07 20:54:36,179] INFO conflict in /controller data: {"version":1,"brokerid":2,"timestamp":"1417956876081"} stored data: {"version":1,"brokerid":1,"timestamp":"1417956860689"} (kafka.utils.ZkUtils$)
[2014-12-07 20:54:36,398] INFO Registered broker 2 at path /brokers/ids/2 with address debugo02:9092. (kafka.utils.ZkUtils$)
[2014-12-07 20:54:36,420] INFO [Kafka Server 2], started (kafka.server.KafkaServer)
#####debugo03#####
[2014-12-07 20:54:43,535] INFO Awaiting socket connections on 0.0.0.0:9092. (kafka.network.Acceptor)
[2014-12-07 20:54:43,549] INFO [Socket Server on Broker 3], Started (kafka.network.SocketServer)
[2014-12-07 20:54:43,728] INFO Will not load MX4J, mx4j-tools.jar is not in the classpath (kafka.utils.Mx4jLoader$)
[2014-12-07 20:54:43,783] INFO conflict in /controller data: {"version":1,"brokerid":3,"timestamp":"1417956883737"} stored data: {"version":1,"brokerid":1,"timestamp":"1417956860689"} (kafka.utils.ZkUtils$)
[2014-12-07 20:54:43,999] INFO Registered broker 3 at path /brokers/ids/3 with address debugo03:9092. (kafka.utils.ZkUtils$)
[2014-12-07 20:54:44,018] INFO [Kafka Server 3], started (kafka.server.KafkaServer)
Topic的分区和复制
1. 创建debugo01,这个topic分区数为3,复制为1(不复制)。该topic跨越全部broker。下面管理命令在任意kafka节点上执行即可
bin/kafka-topics.sh --create --zookeeper debugo01,debugo02,debugo03 --replication-factor 1 --partitions 3 --topic debugo01 Created topic "debugo01".
2. 创建debugo02,这个topic分区数为1,复制为3(每个主机都有一份)。该topic跨越全部broker。下面管理命令在任意kafka节点上执行即可
bin/kafka-topics.sh --create --zookeeper debugo01,debugo02,debugo03 --replication-factor 3 --partitions 1 --topic debugo02
3. 列出topic信息
[root@debugo01 kafka_2.10-0.8.1.1]# bin/kafka-topics.sh --list --zookeeper localhost:2181 debugo01 debugo02
4. 列出topic描述信息
[root@debugo01 kafka_2.10-0.8.1.1]# bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic debugo01 Topic:debugo01 PartitionCount:3 ReplicationFactor:1 Configs: Topic: debugo01 Partition: 0 Leader: 1 Replicas: 1 Isr: 1 Topic: debugo01 Partition: 1 Leader: 2 Replicas: 2 Isr: 2 Topic: debugo01 Partition: 2 Leader: 3 Replicas: 3 Isr: 3
5. 检查log目录,对于topic debugo01,debugo01为0号分区,debugo02为1号分区。而topic debugo02则复制了3份,都为0号分区
[root@debugo01 kafka]# ll total 24 drwxr-xr-x 2 root root 4096 Dec 7 21:15 debugo01-0 drwxr-xr-x 2 root root 4096 Dec 7 21:16 debugo02-0 [root@debugo02 kafka]# ll total 24 drwxr-xr-x 2 root root 4096 Dec 7 21:15 debugo01-1 drwxr-xr-x 2 root root 4096 Dec 7 21:16 debugo02-0 #而每个分区下面都生成了index和log文件 [root@debugo01 debugo01-0]# ls 00000000000000000000.index 00000000000000000000.log
6. 下面topic debugo03,replication-factor为2,partition为3.那么broker id为1的debugo01会如下面describe所示,保存0号分区和1号分区。
而0号分区的repica leader为broker id = 3,包含3和1两个replicas。
bin/kafka-topics.sh --create --zookeeper debugo01,debugo02,debugo03 --replication-factor 2 --partitions 3 --topic debugo03 Created topic "debugo03". bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic debugo03 [root@debugo01 kafka_2.10-0.8.1.1]# bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic debugo03 Topic:debugo03 PartitionCount:3 ReplicationFactor:2 Configs: Topic: debugo03 Partition: 0 Leader: 3 Replicas: 3,1 Isr: 3,1 Topic: debugo03 Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2 Topic: debugo03 Partition: 2 Leader: 2 Replicas: 2,3 Isr: 2,3 [root@debugo01 kafka_2.10-0.8.1.1]# ll /var/kafka/debugo03* /var/kafka/debugo03-0: total 0 -rw-r--r-- 1 root root 10485760 Dec 7 21:34 00000000000000000000.index -rw-r--r-- 1 root root 0 Dec 7 21:34 00000000000000000000.log /var/kafka/debugo03-1: total 0 -rw-r--r-- 1 root root 10485760 Dec 7 21:34 00000000000000000000.index -rw-r--r-- 1 root root 0 Dec 7 21:34 00000000000000000000.log
消息的产生和消费
两个终端分别打开producer和consumer进行测试
<terminal> bin/kafka-console-producer.sh --broker-list debugo01:9092 --topic debugo03 hello kafka hello debugo <terminal> bin/kafka-console-consumer.sh --zookeeper debugo01:2181 --from-beginning --topic debugo03 hello kafka hello debugo</terminal></terminal>
下面使用perf命令来测试几个topic的性能,需要先下载kafka-perf_2.10-0.8.1.1.jar,并拷贝到kafka/libs下面。
50W条消息,每条1000字节,batch大小1000,topic为debugo01,4个线程(message size设置太大需要调整相关参数,否则容易OOM)。只用了13秒完成,kafka在多分区支持下吞吐量是非常给力的。
bin/kafka-producer-perf-test.sh --messages 500000 --message-size 1000 --batch-size 1000 --topics debugo01 --threads 4 --broker-list debugo01:9092,debugo02:9092,debugo03:9092 start.time, end.time, compression, message.size, batch.size, total.data.sent.in.MB, MB.sec, total.data.sent.in.nMsg, nMsg.sec 2014-12-07 22:07:56:038, 2014-12-07 22:08:09:413, 0, 1000, 1000, 476.84, 35.6514, 500000, 37383.1776
同样的参数测试debugo02, 由于但分区加复制(replicas-factor=3),用时39秒。所以,适当加大partition数量和broker相关线程数量会极大的提高性能。
bin/kafka-producer-perf-test.sh --messages 500000 --message-size 1000 --batch-size 1000 --topics debugo02 --threads 4 --broker-list debugo01:9092,debugo02:9092,debugo03:9092 start.time, end.time, compression, message.size, batch.size, total.data.sent.in.MB, MB.sec, total.data.sent.in.nMsg, nMsg.sec 2014-12-07 22:13:28:840, 2014-12-07 22:14:07:819, 0, 1000, 1000, 476.84, 12.2332, 500000, 12827.4199
同样的参数测试debugo03,用时30秒。
bin/kafka-producer-perf-test.sh --messages 500000 --message-size 1000 --batch-size 1000 --topics debugo03 --threads 4 --broker-list debugo01:9092,debugo02:9092,debugo03:9092 start.time, end.time, compression, message.size, batch.size, total.data.sent.in.MB, MB.sec, total.data.sent.in.nMsg, nMsg.sec 2014-12-07 22:16:04:895, 2014-12-07 22:16:34:715, 0, 1000, 1000, 476.84, 15.9905, 500000, 16767.2703
同理,测试comsumer的性能。
bin/kafka-consumer-perf-test.sh --zookeeper debugo01,debugo02,debugo03 --messages 500000 --topic debugo01 --threads 3 start.time, end.time, fetch.size, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec 2014-12-07 22:19:04:527, 2014-12-07 22:19:17:184, 1048576, 476.8372, 62.2747, 500000, 65299.7257 bin/kafka-consumer-perf-test.sh --zookeeper debugo01,debugo02,debugo03 --messages 500000 --topic debugo02 --threads 3 start.time, end.time, fetch.size, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec [2014-12-07 22:19:59,938] WARN [perf-consumer-78853_debugo01-1417961999315-4a5941ef], No broker partitions consumed by consumer thread perf-consumer-78853_debugo01-1417961999315-4a5941ef-1 for topic debugo02 (kafka.consumer.ZookeeperConsumerConnector) [2014-12-07 22:19:59,938] WARN [perf-consumer-78853_debugo01-1417961999315-4a5941ef], No broker partitions consumed by consumer thread perf-consumer-78853_debugo01-1417961999315-4a5941ef-2 for topic debugo02 (kafka.consumer.ZookeeperConsumerConnector) 2014-12-07 22:20:01:008, 2014-12-07 22:20:08:971, 1048576, 476.8372, 160.9305, 500000, 168747.8907 bin/kafka-consumer-perf-test.sh --zookeeper debugo01,debugo02,debugo03 --messages 500000 --topic debugo03 --threads 3 start.time, end.time, fetch.size, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec ?2014-12-07 22:21:27:421, 2014-12-07 22:21:39:918, 1048576, 476.8372, 63.6037, 500002, 66693.6108
^^
参考
http://blog.csdn.net/smallnest/article/details/38491483
http://www.350351.com/jiagoucunchu/xiaoxixitong/46720.html
http://kafka.apache.org/documentation.html
http://backend.blog.163.com/blog/static/202294126201431723734212/
http://www.inter12.org/archives/842
原文地址:Kafka原理和集群测试, 感谢原作者分享。

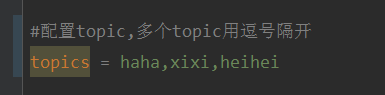 springboot+kafka中@KafkaListener动态指定多个topic怎么实现May 20, 2023 pm 08:58 PM
springboot+kafka中@KafkaListener动态指定多个topic怎么实现May 20, 2023 pm 08:58 PM说明本项目为springboot+kafak的整合项目,故其用了springboot中对kafak的消费注解@KafkaListener首先,application.properties中配置用逗号隔开的多个topic。方法:利用Spring的SpEl表达式,将topics配置为:@KafkaListener(topics=“#{’${topics}’.split(’,’)}”)运行程序,console打印的效果如下
 如何使用PHP和Kafka实现实时股票分析Jun 28, 2023 am 10:04 AM
如何使用PHP和Kafka实现实时股票分析Jun 28, 2023 am 10:04 AM随着互联网和科技的发展,数字化投资已成为人们越来越关注的话题。很多投资者不断探索和研究投资策略,希望能够获得更高的投资回报率。股票交易中,实时的股票分析对决策非常重要,其中使用Kafka实时消息队列和PHP技术实现更是一种高效且实用的手段。一、Kafka介绍Kafka是由LinkedIn公司开发的一个高吞吐量的分布式发布、订阅消息系统。Kafka的主要特点是
 SpringBoot怎么集成Kafka配置工具类May 12, 2023 pm 09:58 PM
SpringBoot怎么集成Kafka配置工具类May 12, 2023 pm 09:58 PMspring-kafka是基于java版的kafkaclient与spring的集成,提供了KafkaTemplate,封装了各种方法,方便操作,它封装了apache的kafka-client,不需要再导入client依赖org.springframework.kafkaspring-kafkaYML配置kafka:#bootstrap-servers:server1:9092,server2:9093#kafka开发地址,#生产者配置producer:#Kafka提供的序列化和反序列化类key
 kafka可视化工具对比分析:如何选择最合适的工具?Jan 05, 2024 pm 12:15 PM
kafka可视化工具对比分析:如何选择最合适的工具?Jan 05, 2024 pm 12:15 PM如何选择合适的Kafka可视化工具?五款工具对比分析引言:Kafka是一种高性能、高吞吐量的分布式消息队列系统,被广泛应用于大数据领域。随着Kafka的流行,越来越多的企业和开发者需要一个可视化工具来方便地监控和管理Kafka集群。本文将介绍五款常用的Kafka可视化工具,并对比它们的特点和功能,帮助读者选择适合自己需求的工具。一、KafkaManager
 go-zero与Kafka+Avro的实践:构建高性能的交互式数据处理系统Jun 23, 2023 am 09:04 AM
go-zero与Kafka+Avro的实践:构建高性能的交互式数据处理系统Jun 23, 2023 am 09:04 AM近年来,随着大数据的兴起和活跃的开源社区,越来越多的企业开始寻找高性能的交互式数据处理系统来满足日益增长的数据需求。在这场技术升级的浪潮中,go-zero和Kafka+Avro被越来越多的企业所关注和采用。go-zero是一款基于Golang语言开发的微服务框架,具有高性能、易用、易扩展、易维护等特点,旨在帮助企业快速构建高效的微服务应用系统。它的快速成长得
 从面试角度一文学完 KafkaAug 24, 2023 pm 03:22 PM
从面试角度一文学完 KafkaAug 24, 2023 pm 03:22 PMKafka 是一个优秀的分布式消息中间件,许多系统中都会使用到 Kafka 来做消息通信。对分布式消息系统的了解和使用几乎成为一个后台开发人员必备的技能。
 springboot项目配置多个kafka的示例代码May 14, 2023 pm 12:28 PM
springboot项目配置多个kafka的示例代码May 14, 2023 pm 12:28 PM1.spring-kafkaorg.springframework.kafkaspring-kafka1.3.5.RELEASE2.配置文件相关信息kafka.bootstrap-servers=localhost:9092kafka.consumer.group.id=20230321#可以并发消费的线程数(通常与partition数量一致)kafka.consumer.concurrency=10kafka.consumer.enable.auto.commit=falsekafka.boo
 Swoole与Kafka的整合:构建高性能MQ系统Jun 13, 2023 pm 08:32 PM
Swoole与Kafka的整合:构建高性能MQ系统Jun 13, 2023 pm 08:32 PM随着互联网和移动设备的不断发展,消息队列成为了现代互联网架构中不可或缺的一部分。消息队列(MQ)可以在不同的应用程序之间传递消息,实现分布式系统中的解耦和异步处理,从而提高整个系统的可伸缩性和性能。在消息队列中,Kafka是一个非常流行和强大的开源消息中间件,而Swoole是一个基于PHP的异步和协程网络编程框架,可以极大地提高PHP应用程序的性能和并发能力


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

禪工作室 13.0.1
強大的PHP整合開發環境

Atom編輯器mac版下載
最受歡迎的的開源編輯器

ZendStudio 13.5.1 Mac
強大的PHP整合開發環境

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

Dreamweaver Mac版
視覺化網頁開發工具

