


Hadoop中连接(join)操作很常见,Hadoop“连接”的概念本身,和SQL的“连接”是一致的。SQL的连接,在维基百科中已经说得非常清楚。比如dataset A是关于用户个人信息的,key是用户id,value是用户姓名等等个人信息;dataset B是关于用户交易记录的,key是用

Hadoop中连接(join)操作很常见,Hadoop“连接”的概念本身,和SQL的“连接”是一致的。SQL的连接,在维基百科中已经说得非常清楚。比如dataset A是关于用户个人信息的,key是用户id,value是用户姓名等等个人信息;dataset B是关于用户交易记录的,key是用户id,value是用户的交易历史等信息。我们当然可以对这两者以共同键用户id为基准来连接两边的数据。
首先,在一切开始之前,先确定真的需要使用Hadoop的连接操作吗?
如果要把两个数据集合放到一起操作,Hadoop还提供了Side Data Distribution(data sharing)的方式,这种方式对于小数据量的情况下效率要高得多,说白了就是把某些数据缓存到本地,例如在本地内存中,直接操作执行,具体包括两种子方式:
- 使用Job Configuration传递;
- 使用Distributed Cache。
当数据量比较大时,是不适合采用Side Data Distribution的,这时候就需要考虑Join了。
Map-side Join
Map-side Join会将数据从不同的dataset中取出,连接起来并放到相应的某个Mapper中处理,因此key相同的数据肯定会在同一个Mapper里面一起得到处理的。如果Mapper前dataset中的数据是无序的,那么对于dataset A的任意一个key,要到其它的dataset中寻找该key对应的数据,造成的复杂度是n的x次方,x等于dataset的个数。因此要求dataset是有序的,这样每个对于任何一个Mapper来说,每一个dataset都只需要遍历一次就可以取到所有需要的数据。Map-side Join对dataset的限制很多,进入不仅仅是有序,不同的dataset中数据的partition方式也要一致,其实最终目的就是保证同样key的数据同时进入一个Mapper。

Reduce-side Join
Reduce-side Join原理上要简单得多,它也不能保证相同key但分散在不同dataset中的数据能够进入同一个Mapper,整个数据集合的排序在Mapper之后的shuffle过程中完成。相对于Map-side Join,它不需要每个Mapper都去读取所有的dataset,这是好处,但也有坏处,即这样一来Mapper之后需要排序的数据集合会非常大,因此shuffle阶段的效率要低于Map-side Join。如果希望在shuffle之后,进入Reducer的时候,value列表是有序的,那么就需要使用Hadoop的Secondary Sort(移步此文)。

不管使用Map-side Join还是Reduce-side Join,都要求进行Join的数据满足某一抽象,这个抽象类型即为进入Mapper或者Reducer的input key的类型。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接《四火的唠叨》

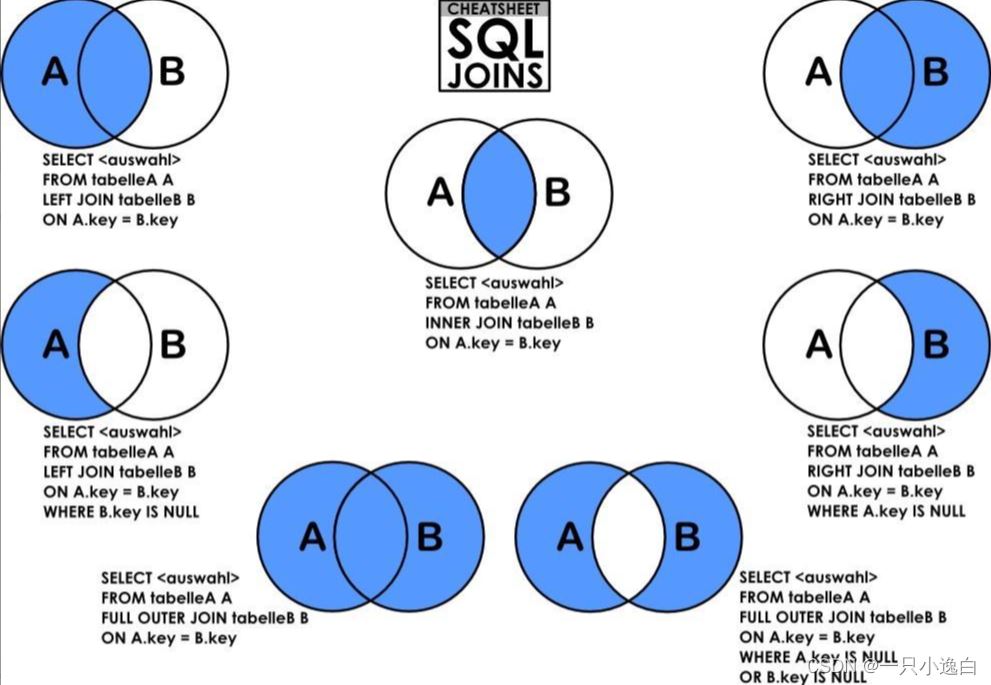 MySql中如何使用JOINJun 04, 2023 am 08:02 AM
MySql中如何使用JOINJun 04, 2023 am 08:02 AMJOIN的含义就如英文单词“join”一样,连接两张表,大致分为内连接,外连接,右连接,左连接,自然连接。先创建两个表,下面用于示例CREATETABLEt_blog(idINTPRIMARYKEYAUTO_INCREMENT,titleVARCHAR(50),typeIdINT);SELECT*FROMt_blog;+----+-------+--------+|id|title|typeId|+----+-------+--------+|1|aaa|1||2|bbb|2||3|ccc|3|
 Java错误:Hadoop错误,如何处理和避免Jun 24, 2023 pm 01:06 PM
Java错误:Hadoop错误,如何处理和避免Jun 24, 2023 pm 01:06 PMJava错误:Hadoop错误,如何处理和避免当使用Hadoop处理大数据时,常常会遇到一些Java异常错误,这些错误可能会影响任务的执行,导致数据处理失败。本文将介绍一些常见的Hadoop错误,并提供处理和避免这些错误的方法。Java.lang.OutOfMemoryErrorOutOfMemoryError是Java虚拟机内存不足的错误。当Hadoop任
 MySQL Join使用原理是什么May 26, 2023 am 10:07 AM
MySQL Join使用原理是什么May 26, 2023 am 10:07 AMJoin的类型leftjoin,以左表为驱动表,以左表作为结果集基础,连接右表的数据补齐到结果集中rightjoin,以右表为驱动表,以右表作为结果集基础,连接左表的数据补齐到结果集中innerjoin,结果集取两个表的交集fulljoin,结果集取两个表的并集mysql没有fulljoin,union取代union与unionall的区别为,union会去重crossjoin笛卡尔积如果不使用where条件则结果集为两个关联表行的乘积与,的区别为,crossjoin建立结果集时会根据on条件过
 在Beego中使用Hadoop和HBase进行大数据存储和查询Jun 22, 2023 am 10:21 AM
在Beego中使用Hadoop和HBase进行大数据存储和查询Jun 22, 2023 am 10:21 AM随着大数据时代的到来,数据处理和存储变得越来越重要,如何高效地管理和分析大量的数据也成为企业面临的挑战。Hadoop和HBase作为Apache基金会的两个项目,为大数据存储和分析提供了一种解决方案。本文将介绍如何在Beego中使用Hadoop和HBase进行大数据存储和查询。一、Hadoop和HBase简介Hadoop是一个开源的分布式存储和计算系统,它可
 如何使用PHP和Hadoop进行大数据处理Jun 19, 2023 pm 02:24 PM
如何使用PHP和Hadoop进行大数据处理Jun 19, 2023 pm 02:24 PM随着数据量的不断增大,传统的数据处理方式已经无法处理大数据时代带来的挑战。Hadoop是开源的分布式计算框架,它通过分布式存储和处理大量的数据,解决了单节点服务器在大数据处理中带来的性能瓶颈问题。PHP是一种脚本语言,广泛应用于Web开发,而且具有快速开发、易于维护等优点。本文将介绍如何使用PHP和Hadoop进行大数据处理。什么是HadoopHadoop是
 mysql的join查询和多次查询方法是什么Jun 02, 2023 pm 04:29 PM
mysql的join查询和多次查询方法是什么Jun 02, 2023 pm 04:29 PMjoin查询和多次查询比较MySQL多表关联查询效率高点还是多次单表查询效率高?在数据量不够大的时候,用join没有问题,但是一般都会拉到service层上去做第一:单机数据库计算资源很贵,数据库同时要服务写和读,都需要消耗CPU,为了能让数据库的吞吐变得更高,而业务又不在乎那几百微妙到毫秒级的延时差距,业务会把更多计算放到service层做,毕竟计算资源很好水平扩展,数据库很难啊,所以大多数业务会把纯计算操作放到service层做,而将数据库当成一种带事务能力的kv系统来使用,这是一种重业务,
 探索Java在大数据领域的应用:Hadoop、Spark、Kafka等技术栈的了解Dec 26, 2023 pm 02:57 PM
探索Java在大数据领域的应用:Hadoop、Spark、Kafka等技术栈的了解Dec 26, 2023 pm 02:57 PMJava大数据技术栈:了解Java在大数据领域的应用,如Hadoop、Spark、Kafka等随着数据量不断增加,大数据技术成为了当今互联网时代的热门话题。在大数据领域,我们常常听到Hadoop、Spark、Kafka等技术的名字。这些技术起到了至关重要的作用,而Java作为一门广泛应用的编程语言,也在大数据领域发挥着巨大的作用。本文将重点介绍Java在大
 MySQL中JOIN怎么用Jun 03, 2023 am 09:30 AM
MySQL中JOIN怎么用Jun 03, 2023 am 09:30 AM简介A的独有+AB的公有B的独有+AB的公有AB的公有A的独有B的独有A的独有+B的独有+AB的公有A的独有+B的独有练习建表部门表DROPTABLEIFEXISTS`dept`;CREATETABLE`dept`(`dept_id`int(11)NOTNULLAUTO_INCREMENT,`dept_name`varchar(30)DEFAULTNULL,`dept_number`int(11)DEFAULTNULL,PRIMARYKEY(`dept_id`))ENGINE=InnoDBAUT


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

VSCode Windows 64位元 下載
微軟推出的免費、功能強大的一款IDE編輯器

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

記事本++7.3.1
好用且免費的程式碼編輯器

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

