



MySQL把表的数据词典信息以.frm文件的形式存在数据库目录里,所有MySQL存储引擎都是这样的。但是每个InnoDB表在表空间内的InnoDB内部数据词典里也有它自己的条目。当MySQL移除表或数据库,它不得不删除.frm文件和InnoDB数据词典内的相应条目。这就是为什么你
MySQL把表的数据词典信息以.frm文件的形式存在数据库目录里,所有MySQL存储引擎都是这样的。但是每个InnoDB表在表空间内的InnoDB内部数据词典里也有它自己的条目。当MySQL移除表或数据库,它不得不删除.frm文件和InnoDB数据词典内的相应条目。这就是为什么你不能在数据库之间简单地移动.frm文件来移动InnoDB表。
1. 聚集索引和第二索引
每个InnoDB有一个叫聚集索引(clustered index)的特殊索引,行的数据被存于其中。
- 如果你的表定义了主键,主键的索引就是聚集索引。
- 如果你的表没有主键,MySQL就选择第一个不可为空的唯一索引(UNIQUE)作为主键,并且InnoDB把它作为聚集索引。
- 如果你的表没有主键,也没有合适的唯一索引,InnoDB内部会在一个包含RowID的合成列上生成一个隐藏的聚集索引,其中是用InnoDB在分配给RowID来排序的。RowID是一个6字节的域,它在新行被插入的时候单调增加。因此被RowID排序的行是物理地按照插入顺序排的。
通过聚集索引访问行速度很快,因为行数据与索引扫描头部在同一数据页上。如果表是巨大的,当对于那些索引与数据放在不同数据页上的方案,聚集索引构架通常更节约磁盘I/O。(比如,MyISAM用一个文件存放数据,另外一个文件存放索引)。
在InnoDB中,非聚集索引里的记录(也称为辅助索引或第二索引)包含对应行的主键值。InnoDB用这个主键值从聚集索引中搜索行。注意,如果主键比较长,第二索引就会使用更多空间,因此最好使用一个比较短的主键。
2. 索引的物理结构
所有InnoDB的索引是B树索引,这种索引记录被存储在树的叶子页上。一个索引页的默认大小是16KB。当新记录被插入,InnoDB会为将来索引记录的插入和更新留下十六分之一的页空间。
如果索引记录以连续的顺序被插入(升序或者降序),结果索引页大约是15/16满。如果记录被以随机的顺序被插入,页面是从1/2到 15/16满。如果索引页的填充因子降到低于1/2,InnoDB会收缩索引树来释放页。
3. 插入缓冲
在数据库应用中,主键是一个唯一的识别符,并且新行被以主键的升序来插入,这是个常见的情况。因此,聚集索引的插入不需要磁盘的随机读。
另一方面,第二索引通常是非唯一的,第二索引的插入顺序也相对随机。这可能会导致大量的随机磁盘I/O操作,而没有一个被用在InnoDB中的专用机制。
如果一个索引记录应该被插入到一个非唯一第二索引,InnoDB检查第二索引页是否在缓冲池中。如果是,InnoDB直接插入到索引页。如果索引页没有在缓冲池中被发现,InnoDB插入记录到一个专门的插入缓冲结构。插入缓冲被保持得如此小以至于它完全适合在缓冲池,并且可以非常快地做插入。
插入缓冲周期性地被合并到数据库中第二索引树里。把数个插入合并到索引树的同一页,节省磁盘I/O操作,经常地这是有可能的。据测量,插入缓冲可以提高到表的插入速度达15倍。
在插入事务被提交之后,插入缓冲合并可能连续发生。实际上,服务器关闭和重启之后,这会连续发生。
当许多第二索引必须被更新,并且许多行已被插入之时,插入缓冲合并可能需要数个小时。在这期间内,磁盘I/O将会增加,这样会导致磁盘约束查询明显缓慢。另一个明显的后台I/O操作是净化(purge)线程。
4. 自适应的哈希索引
如果一个表几乎完全缓存在主内存中,在其上执行查询最快的方法就是使用哈希索引。InnoDB有一个自动机制,它监视对为一个表定义的索引的索引搜索。如果InnoDB注意到查询会从建立一个哈希索引中获益,它会自动地这么做。
注意,哈希索引总是基于表上已存在的B树索引来建立。根据InnoDB对B树索引观察的搜索方式,InnoDB会在为该B树定义的任何长度的键的一个前缀上建立哈希索引。 哈希索引可以是部分的:它不要求整个B树索引被缓存在缓冲池。InnoDB根据需要对被经常访问的索引的那些页面建立哈希索引。
在某种意义上,InnoDB通过自适应的哈希索引机制来调整自己,使其更加贴近主内存数据库的架构。
5. 物理行结构
InnoDB表的物理行结构取决于表创建时指定的行格式。在MySQL 5.1中,InnoDB默认使用紧凑(COMPACT)格式,但为了保留与旧版本MySQL的兼容性,冗余(REDUNDANT)格式也可用。查看InnoDB表的行格式,可使用SHOW TABLE STATUS命令。
紧凑的行格式大约可减少20%的存储空间,但某些操作会增加CPU使用量。如果是一个典型的受限于高速缓存命中率和磁盘速度的工作负荷,使用紧凑格式可能会更快。如果是一种少见工作负荷情况,由于有限的CPU速度,紧凑格式可能会比较慢。
使用冗余行格式的InnoDB表行具有以下特点:
- InnoDB中每个索引记录包含一个6字节的头。这个头被用来将连续的记录连接在一起,并且也用在row-level锁定中。
- 聚集索引里的记录包含所有的用户定义列。此外,还有6个字节的事务ID和一个7个字节的回滚指针。
- 如果一个表没有定义主键,每个聚集索引记录还包含一个6字节的RowID。
- 每个第二索引记录包含聚集索引键定义的所有主键列。
- 一个记录也包含一个指向该记录每个列的指针,如果在一个记录中列的总长度小于128字节,该指针是一个字节;否则就是2字节。这些指针的阵列被称为记录目录。这些指针指向的区域被称为记录的数据部分。
- 在内部,InnoDB以固定长度格式存储固定长度的字符列,比如CHAR(10)。InnoDB不截断VARCHAR列的尾随空格。
- 一个SQL的NULL值在记录目录里占1到2字节。例如,在一个可变长度列,如果存的是SQL的NULL值,则在记录数据部分占零字节。在一个固定长度列,记录的数据部分占该列的固定长度。为NULL值保留固定空间的动机是之后该列从NULL值到非NULL值的更新可以就地完成,且不会导致索引页的碎片。
使用紧凑行格式的InnoDB表行具有以下特点:
- InnoDB中每个索引记录包含一个5字节的头,在此之前是一个可变长度头。这个头被用来将连续的记录连接在一起,并且也用在row-level锁定中。
- 在记录头的可变长度部分包含一个用来标识NULL列的位向量。如果索引中可为NULL的列的数量为N,则该位向量占用(N+7)/8个字节。NULL列完全不占用这个位向量以外的空间。在头的可变长度部分也包含可变长列的长度。每个长度需要一个或两个字节,这取决于该列的最大长度。如果索引中的所有列都是NOT NULL的并且是固定长度的,记录头就没有可变长度部分。
- 对于每一个非空的可变长字段,记录头用一个或两个字节保存列长度。两个字节只用在列的一部分数据外部存储在溢出页上或者列最大长度超过255个字节并且实际长度超过127字节的情况下。对于外部存储的列,这两个字节长度表示内部存储部分的长度加上20字节的外部存储指针。例如内部存储部分是768字节,这个长度就是768+20。20字节长的指针存储了列的真实长度。
- 记录头后紧跟着的是非空列的数据内容。
- 聚集索引里的记录包含所有的用户定义列。此外,还有6个字节的事务ID和一个7个字节的回滚指针。
- 如果一个表没有定义主键,每个聚集索引记录还包含一个6字节的RowID。
- 每个第二索引记录也包含为聚集索引键定义的所有主键列。如果任何主键字段是可变长的,则每一个第二索引的记录头必须有一个可变长部分来记录这些可变长列的长度,即使第二索引是建立在固定长的列上。
- 在内部,InnoDB以固定长度格式存储固定长度、固定宽度的字符列,如CHAR(10)。InnoDB不截断VARCHAR列的尾随空格。
- 在内部,InnoDB会将UTF-8的CHAR(N)的列存储在N字节里,并截断尾随空格。(如果冗余行格式,这样的列会占据3 ×N字节。 )在许多情况下,保留最低限度的空间N可以保持列在更新时不会造成索引碎片。

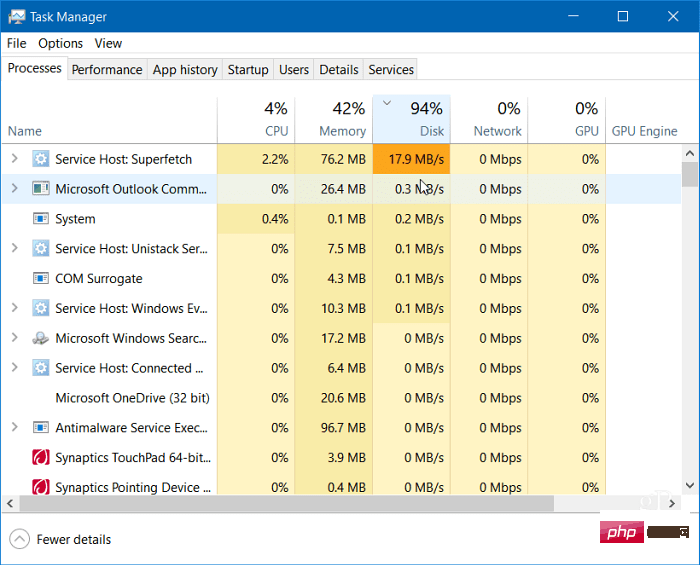 如何在 Windows 11 上修复 100% 的磁盘使用率Apr 20, 2023 pm 12:58 PM
如何在 Windows 11 上修复 100% 的磁盘使用率Apr 20, 2023 pm 12:58 PM如何在Window11上修复100%的磁盘使用率查找导致100%磁盘使用的有问题的应用程序或服务的直接方法是使用任务管理器。要打开任务管理器,请右键单击开始菜单并选择任务管理器。单击磁盘列标题,查看占用最多资源的内容。从那里开始,您将很好地了解从哪里开始。但是,问题可能比仅仅关闭应用程序或禁用服务更严重。继续阅读以查找问题的更多潜在原因以及如何解决这些问题。禁用SuperfetchSuperfetch功能(在Windows11中也称为SysMain)有助于通过访问预取文件来减少启动时
 如何在 Windows 11 中隐藏文件和文件夹并从搜索中移除?Apr 26, 2023 pm 11:07 PM
如何在 Windows 11 中隐藏文件和文件夹并从搜索中移除?Apr 26, 2023 pm 11:07 PM<h2>如何在Windows11上从搜索中隐藏文件和文件夹</h2><p>我们首先要看的是自定义Windows搜索文件的位置。通过跳过这些特定位置,您应该可以更快地看到结果,同时还可以隐藏您想要保护的任何文件。</p><p>如果要从Windows11上的搜索中排除文件和文件夹,请使用以下步骤:</p><ol&
 以下是6种修复Windows 11搜索栏不可用的方法。May 08, 2023 pm 10:25 PM
以下是6种修复Windows 11搜索栏不可用的方法。May 08, 2023 pm 10:25 PM如果您的搜索栏在Windows11中不起作用,有几种快速方法可以立即启动并运行!任何微软操作系统有时都可能遇到故障,最新的操作系统不能免除该规则。此外,正如Reddit上的用户u/zebra_head1所指出的那样,同样的错误出现在Windows11的22H2Build22621.1413上。用户抱怨切换任务栏搜索框的选项随机消失。因此,您必须为任何情况做好准备。为什么我无法在计算机上的搜索栏中键入内容?无法在计算机上键入可归因于不同的因素和过程。以下是您应该注意的一些事项:Ctfmon.
 MySQL如何从二进制内容看InnoDB行格式Jun 03, 2023 am 09:55 AM
MySQL如何从二进制内容看InnoDB行格式Jun 03, 2023 am 09:55 AMInnoDB是一个将表中的数据存储到磁盘上的存储引擎,所以即使关机后重启我们的数据还是存在的。而真正处理数据的过程是发生在内存中的,所以需要把磁盘中的数据加载到内存中,如果是处理写入或修改请求的话,还需要把内存中的内容刷新到磁盘上。而我们知道读写磁盘的速度非常慢,和内存读写差了几个数量级,所以当我们想从表中获取某些记录时,InnoDB存储引擎需要一条一条的把记录从磁盘上读出来么?InnoDB采取的方式是:将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位,InnoDB中页的大小一般为16
 mysql innodb是什么Apr 14, 2023 am 10:19 AM
mysql innodb是什么Apr 14, 2023 am 10:19 AMInnoDB是MySQL的数据库引擎之一,现为MySQL的默认存储引擎,为MySQL AB发布binary的标准之一;InnoDB采用双轨制授权,一个是GPL授权,另一个是专有软件授权。InnoDB是事务型数据库的首选引擎,支持事务安全表(ACID);InnoDB支持行级锁,行级锁可以最大程度的支持并发,行级锁是由存储引擎层实现的。
 Windows 11 Outlook 搜索不工作:6 个修复方法Apr 22, 2023 pm 09:46 PM
Windows 11 Outlook 搜索不工作:6 个修复方法Apr 22, 2023 pm 09:46 PM在Outlook中运行搜索和索引疑难解答您可以开始的更直接的修复之一是运行搜索和索引疑难解答。要在Windows11上运行疑难解答,请执行以下操作:单击开始按钮或按Windows键并从菜单中选择设置。当设置打开时,选择系统>疑难解答>其他疑难解答。在右侧向下滚动,找到SearchandIndexing,然后单击Run按钮。选择Outlook搜索不返回结果并继续屏幕上的说明。当您运行它时,疑难解答程序将自动识别并修复问题。运行疑难解答后,打开Outlook并查看搜索是否正常。如
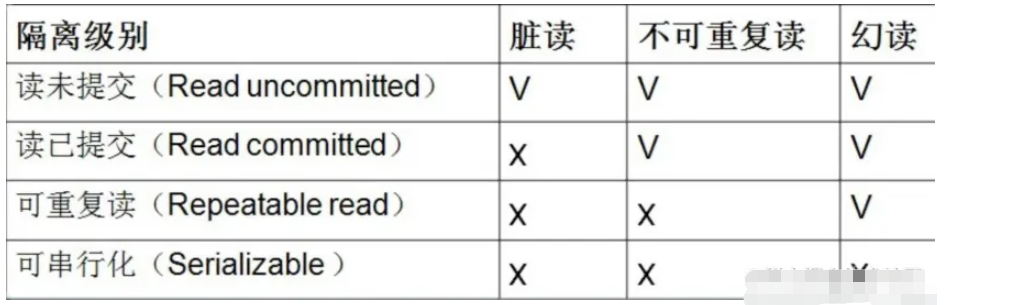 Mysql中的innoDB怎么解决幻读May 27, 2023 pm 03:34 PM
Mysql中的innoDB怎么解决幻读May 27, 2023 pm 03:34 PM1.Mysql的事务隔离级别这四种隔离级别,当存在多个事务并发冲突的时候,可能会出现脏读,不可重复读,幻读的一些问题,而innoDB在可重复读隔离级别模式下解决了幻读的一个问题,2.什么是幻读幻读是指在同一个事务中,前后两次查询相同范围的时候得到的结果不一致如图,第一个事务里面,我们执行一个范围查询,这个时候满足条件的数据只有一条,而在第二个事务里面,它插入一行数据并且进行了提交,接着第一个事务再去查询的时候,得到的结果比第一次查询的结果多出来一条数据,注意第一个事务的第一次和第二次查询,都在同
 mysql innodb异常怎么处理Apr 17, 2023 pm 09:01 PM
mysql innodb异常怎么处理Apr 17, 2023 pm 09:01 PM一、回退重新装mysql为避免再从其他地方导入这个数据的麻烦,先对当前库的数据库文件做了个备份(/var/lib/mysql/位置)。接下来将Perconaserver5.7包进行了卸载,重新安装原先老的5.1.71的包,启动mysql服务,提示Unknown/unsupportedtabletype:innodb,无法正常启动。11050912:04:27InnoDB:Initializingbufferpool,size=384.0M11050912:04:27InnoDB:Complete


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

Dreamweaver Mac版
視覺化網頁開發工具

