


神馬是「解釋器模式」?
先翻開《GOF》看看Definition:
給定一個語言,定義它的文法的一種表示,並定義一個解釋器,這個解釋器使用該表示來解釋語言中的句子。
在開篇之前還是要科普幾個概念:
抽象語法樹:
解釋器模式並未解釋如何建立抽象語法樹。它不涉及語法分析。抽象語法樹可用一個表格驅動的語法分析程式來完成,也可用手寫的(通常為遞歸下降法)語法分析程式創建,或直接client提供。
解析器:
指的是把描述客戶端呼叫要求的表達式,經過解析,形成一個抽象語法樹的程式。
解釋器:
指的是解釋抽象語法樹,並執行每個節點對應的功能的程式。
要使用解釋器模式,一個重要的前提就是要定義一套文法規則,也稱為文法。不管這套文法的規則是簡單還是複雜,必須要有這些規則,因為解釋器模式就是按照這些規則來進行解析並執行對應的功能的。
先來看看解釋器模式的結構圖和說明:

AbstractExpression:定義解釋器的接口,約定解釋器的解釋操作。
TerminalExpression:終結符解釋器,用來實現語法規則中和終結符相關的操作,不再包含其他的解釋器,如果用組合模式來構建抽象語法樹的話,就相當於組合模式中的葉子對象,可以有多種終結符解釋器。
NonterminalExpression:非終結符解釋器,用來實現語法規則中非終結符相關的操作,通常一個解釋器對應一個語法規則,可以包含其他的解釋器,如果用組合模式來建構抽象語法樹的話,就相當於組合模式中的組合物件。可以有多種非終結符解釋器。
Context:上下文,通常包含各個解釋器所需的資料或是公共的功能。
Client:客戶端,指的是使用解釋器的客戶端,通常在這裡將按照語言的語法做的表達式轉換成為使用解釋器對象描述的抽象語法樹,然後調用解釋操作。
下面我們透過一個xml範例來理解解釋器模式:
首先要為表達式設計簡單的文法,為了通用,用root表示根元素,abc等來代表元素,一個簡單的xml如下:
d1
約定表達式的文法如下:
1.取得單一元素的值:從根元素開始,一直到想要取得取值的元素,元素中間用「/」分隔,根元素前不加“/”。例如,表達式「root/a/b/c」就表示取得根元素下,a元素下,b元素下,c元素的值。
2.取得單一元素的屬性的值:當然是多個,要取得值的屬性一定是表達式的最後一個元素的屬性,在最後一個元素後面加上「.」然後再加上屬性的名稱。例如,表達式「root/a/b/c.name」就表示取得根元素下,a元素下,b元素下,c元素的name屬性的值。
3.取得相同元素名稱的值,當然還有多個,要取得值的元素一定是表達式的最後一個元素,在最後一個元素後面加上「$」。例如,表達式「root/a/b/d$」就表示取得根元素下,a元素下,b元素下的多個d元素的值的集合。
4.取得相同元素名稱的屬性的值,當然也是多個:要取得屬性值的元素一定是表達式的最後一個元素,在最後一個元素後面加上"$"。例如,表達式「root/a/b/d$.id$」就表示取得根元素下,a元素下,b元素下的多個d元素的id屬性的值的集合。
上面的xml,對應的抽象語法樹,可能的結構如圖:
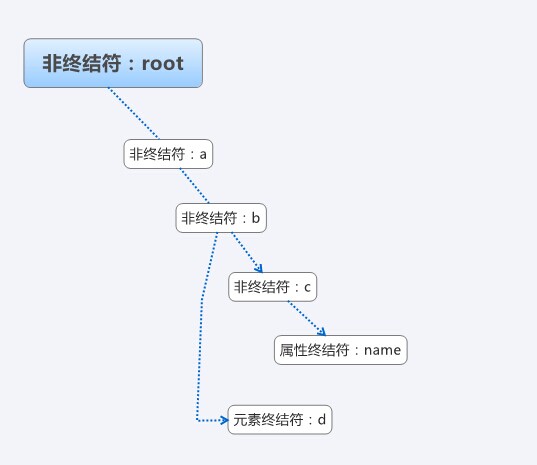
下面我們來看看具體的程式碼:
1.定義上下文:
/**
* 上下文,用來包含解釋器所需的一些全域資訊
* @param {String} filePathName [需要讀取的xml的路徑和名字]
*/
/**
* 各個Expression公共使用的方法
* 依照父元素與目前元素的名稱取得目前元素
* @param [目前元素名稱] * @return {Element|null} [已找到的目前元素]
*/
*/ // 上一個被處理元素
this.preEle = null;
// xml的Document物件
Context.prototype = {
// 重新初始化上下文
reInit: function () {
getNowEle: function (pEle, eleName) {
var tempNodeList = pEle.childNodes;
for (var i = 0, len = tempNodeList.length; i if (nowEle. nodeName === eleName)
return null;
},
getPreEle: function () {
Ele: function (preEle) {
},
getDocument: function () {
return this.document;
return this.document;
return this.document;
在上下文中使用了一個工具物件XmlUtil來取得xmlDom,下面我使用的是DOM3的DOMPaser,某些瀏覽器可能不支持,請使用搞基瀏覽器:
複製程式碼
程式碼如下:
// 工具物件
// 解析xml,取得對應的Document物件
var XmlUtil = {
var parser = new DOMParser() ;
var xmldom = parser.parseFromString('
return xmldom;
}
};
以下是解釋器的程式碼:
/**
* 元素作为非终结符对应的解释器,解释并执行中间元素
* @param {String} eleName [元素的名称]
*/
function ElementExpression(eleName) {
this.eles = [];
this.eleName = eleName;
}
ElementExpression.prototype = {
addEle: function (eleName) {
this.eles.push(eleName);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i if (ele === this.eles[i])
this.eles.splice(i--, 1);
}
return true;
},
interpret: function (context) {
// 先取出上下文中的当前元素作为父级元素
// 查找到当前元素名称所对应的xml元素,并设置回到上下文中
var pEle = context.getPreEle();
if (!pEle) {
// 说明现在获取的是根元素
context.setPreEle(context.getDocument().documentElement);
} else {
// 根据父级元素和要查找的元素的名称来获取当前的元素
var nowEle = context.getNowEle(pEle, this.eleName);
// 把当前获取的元素放到上下文中
context.setPreEle(nowEle);
}
var ss;
// 循环调用子元素的interpret方法
for (var i = 0, len = this.eles.length; i ss = this.eles[i].interpret(context);
}
// 返回最后一个解释器的解释结果,一般最后一个解释器就是终结符解释器了
return ss;
}
};
/**
* 元素作为终结符对应的解释器
* @param {String} name [元素的名称]
*/
function ElementTerminalExpression(name) {
this.eleName = name;
}
ElementTerminalExpression.prototype = {
interpret: function (context) {
var ele = null;
if (!pEle) {
ele = context.getDocument().documentElement;
} else {
context.setPreEle(ele);
}
// 取得元素的值
* 屬性作為終結符對應的解釋器
* @param {String} propName [屬性的名稱]
*/ function PropertyTerminalExpression(propName) {
PropertyTerminalExpression.prototype = {
interpret: function (context) {
return context.getPreEle().getAttribute(this.propName);
}
};
先來看看如何使用解釋器取得單一元素的值:
// 想要取得多個d元素的值,也就是以下表達式的值:「root/a/b/c」
// 首先要建構解釋器的抽象語法樹
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
('c');
// 組合
root.addEle(aEle); aEle.addEle(bEle);
Ele.addEle(cEle);
Ele.addEle(cEle);
console.log('c的值是 = ' root.interpret(c));
輸出: c的值是 = 12345
void function () {
var c = new Context();
.name”
// 這個時候c不是終結了,需要把c修改成ElementExpression
var root = new ElementExpression('root');
🎜> var bEle = new ElementExpression('b');
🎜>
// 組合
root.addEle(aEle); aEle.addEle(b> 🎜> cEle.addEle(prop);
console.log('c的屬性name值是 = ' root.interpret(c));
// 若要使用同一個上下文,連續解析,需要重新初始化上下文物件
//,且要連續的再取得一次屬性name 例如/ 重新解析,只要是在使用同一個上下文,就需要重新初始化上下文物件
console.log('重新取得c的屬性name值是= ' root.prec ));
}();
输出: c的属性name值是 = testC 重新获取c的属性name值是 = testC
讲解:
1.解释器模式功能:
解释器模式使用解释器对象来表示和处理相应的语法规则,一般一个解释器处理一条语法规则。理论上来说,只要能用解释器对象把符合语法的表达式表示出来,而且能够构成抽象的语法树,就可以使用解释器模式来处理。
2.语法规则和解释器
语法规则和解释器之间是有对应关系的,一般一个解释器处理一条语法规则,但是反过来并不成立,一条语法规则是可以有多种解释和处理的,也就是一条语法规则可以对应多个解释器。
3.上下文的公用性
上下文在解释器模式中起着非常重要的作用。由于上下文会被传递到所有的解释器中。因此可以在上下文中存储和访问解释器的状态,比如,前面的解释器可以存储一些数据在上下文中,后面的解释器就可以获取这些值。
另外还可以通过上下文传递一些在解释器外部,但是解释器需要的数据,也可以是一些全局的,公共的数据。
上下文还有一个功能,就是可以提供所有解释器对象的公共功能,类似于对象组合,而不是使用继承来获取公共功能,在每个解释器对象中都可以调用
4.谁来构建抽象语法树
在前面的示例中,是自己在客户端手工构建抽象语法树,是很麻烦的,但是在解释器模式中,并没有涉及这部分功能,只是负责对构建好的抽象语法树进行解释处理。后面会介绍可以提供解析器来实现把表达式转换成为抽象语法树。
还有一个问题,就是一条语法规则是可以对应多个解释器对象的,也就是说同一个元素,是可以转换成多个解释器对象的,这也就意味着同样一个表达式,是可以构成不用的抽象语法树的,这也造成构建抽象语法树变得很困难,而且工作量非常大。
5.谁负责解释操作
只要定义好了抽象语法树,肯定是解释器来负责解释执行。虽然有不同的语法规则,但是解释器不负责选择究竟用哪个解释器对象来解释执行语法规则,选择解释器的功能在构建抽象语法树的时候就完成了。
6.解释器模式的调用顺序
1)创建上下文对象
2)创建多个解释器对象,组合抽象语法树
3)调用解释器对象的解释操作
3.1)通过上下文来存储和访问解释器的状态。
对于非终结符解释器对象,递归调用它所包含的子解释器对象。
解释器模式的本质:*分离实现,解释执行*
解释器模使用一个解释器对象处理一个语法规则的方式,把复杂的功能分离开;然后选择需要被执行的功能,并把这些功能组合成为需要被解释执行的抽象语法树;再按照抽象语法树来解释执行,实现相应的功能。
从表面上看,解释器模式关注的是我们平时不太用到的自定义语法的处理;但从实质上看,解释器模式的思想然后是分离,封装,简化,和很多模式是一样的。
比如,可以使用解释器模式模拟状态模式的功能。如果把解释器模式要处理的语法简化到只有一个状态标记,把解释器看成是对状态的处理对象,对同一个表示状态的语法,可以有很多不用的解释器,也就是有很多不同的处理状态的对象,然后再创建抽象语法树的时候,简化成根据状态的标记来创建相应的解释器,不用再构建树了。
同理,解释器模式可以模拟实现策略模式的功能,装饰器模式的功能等,尤其是模拟装饰器模式的功能,构建抽象语法树的过程,自然就对应成为组合装饰器的过程。
解释器模式执行速度通常不快(大多数时候非常慢),而且错误调试比较困难(附注:虽然调试比较困难,但事实上它降低了错误的发生可能性),但它的优势是显而易见的,它能有效控制模块之间接口的复杂性,对于那种执行频率不高但代码频率足够高,且多样性很强的功能,解释器是非常适合的模式。此外解释器还有一个不太为人所注意的优势,就是它可以方便地跨语言和跨平台。
解释器模式的优缺点:
优点:
1.易于实现语法
在解释器模式中,一条语法规则用一个解释器对象来解释执行。对于解释器的实现来讲,功能就变得比较简单,只需要考虑这一条语法规则的实现就可以了,其他的都不用管。 2.易于扩展新的语法
正是由於採用一個解釋器物件負責一條語法規則的方式,使得擴展新的語法非常容易。擴展了新的語法,只需要創建相應的解釋器對象,在創建抽象語法樹的時候使用這個新的解釋器對象就可以了。
缺點:
不適合複雜的語法
如果語法特別複雜,建構解釋器模式所需的抽象語法樹的工作是非常艱鉅的,再加上有可能會需要建構多個抽象語法樹。所以解釋器模式不太適合複雜的語法。使用語法分析程式或編譯器產生器可能會更好一些。
何時使用?
當有一個語言需要解釋執行,並且可以將該語言中的句子表示為一個抽象語法樹的時候,可以考慮使用解釋器模式。
在使用解釋器模式的時候,還有兩個特點需要考慮,一個是語法相對應該比較簡單,太負責的語法不適合使用解釋器模式玲玲一個是效率要求不是很高,對效率要求很高的,不適合使用。
前面介紹瞭如何取得單一元素的值和單一元素屬性的值,下面來看看如何取得多個元素的值,還有多個元素中相擁名稱的值,還有前面的測試都是人工組合好的抽象語法樹,我們也順便實作以下簡單的解析器,把符合前面定義的語法的表達式,轉換成為前面實作的解釋器的抽象語法樹: 我就直接把程式碼貼出來了:
// 读取多个元素或属性的值
(function () {
/**
* 上下文,用来包含解释器需要的一些全局信息
* @param {String} filePathName [需要读取的xml的路径和名字]
*/
function Context(filePathName) {
// 上一个被处理的多个元素
this.preEles = [];
// xml的Document对象
this.document = XmlUtil.getRoot(filePathName);
}
Context.prototype = {
// 重新初始化上下文
reInit: function () {
this.preEles = [];
},
/**
* 各个Expression公共使用的方法
* 根据父元素和当前元素的名称来获取当前元素
* @param {Element} pEle [父元素]
* @param {String} eleName [当前元素名称]
* @return {Element|null} [找到的当前元素]
*/
getNowEles: function (pEle, eleName) {
var elements = [];
var tempNodeList = pEle.childNodes;
var nowEle;
for (var i = 0, len = tempNodeList.length; i if ((nowEle = tempNodeList[i]).nodeType === 1) {
if (nowEle.nodeName === eleName) {
elements.push(nowEle);
}
}
}
return elements;
},
getPreEles: function () {
return this.preEles;
},
setPreEles: function (nowEles) {
this.preEles = nowEles;
},
getDocument: function () {
return this.document;
}
};
// 工具对象
// 解析xml,获取相应的Document对象
var XmlUtil = {
getRoot: function (filePathName) {
var parser = new DOMParser();
var xmldom = parser.parseFromString('
return xmldom;
}
};
/**
* 元素作为非终结符对应的解释器,解释并执行中间元素
* @param {String} eleName [元素的名称]
*/
function ElementExpression(eleName) {
this.eles = [];
this.eleName = eleName;
}
ElementExpression.prototype = {
addEle: function (eleName) {
this.eles.push(eleName);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i if (ele === this.eles[i]) {
this.eles.splice(i--, 1);
}
}
return true;
},
interpret: function (context) {
// 先取出上下文中的当前元素作为父级元素
// 查找到当前元素名称所对应的xml元素,并设置回到上下文中
var pEles = context.getPreEles();
var ele = null;
var nowEles = [];
if (!pEles.length) {
// 说明现在获取的是根元素
ele = context.getDocument().documentElement;
pEles.push(ele);
context.setPreEles(pEles);
} else {
var tempEle;
for (var i = 0, len = pEles.length; i tempEle = pEles[i];
nowEles = nowEles.concat(context.getNowEles(tempEle, this.eleName));
// 找到一个就停止
if (nowEles.length) break;
}
context.setPreEles([nowEles[0]]);
}
var ss;
// 循环调用子元素的interpret方法
for (var i = 0, len = this.eles.length; i ss = this.eles[i].interpret(context);
}
return ss;
}
};
/**
* 元素作为终结符对应的解释器
* @param {String} name [元素的名称]
*/
function ElementTerminalExpression(name) {
this.eleName = name;
}
ElementTerminalExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var ele = null;
if (!pEles.length) {
ele = context.getDocument().documentElement;
} else {
ele = context.getNowEles(pEles[0], this.eleName)[0];
}
// 获取元素的值
return ele.firstChild.nodeValue;
}
};
/**
* 属性作为终结符对应的解释器
* @param {String} propName [属性的名称]
*/
function PropertyTerminalExpression(propName) {
this.propName = propName;
}
PropertyTerminalExpression.prototype = {
interpret: function (context) {
// 直接获取最后的元素属性的值
return context.getPreEles()[0].getAttribute(this.propName);
}
};
/**
* 多个属性作为终结符对应的解释器
* @param {String} propName [属性的名称]
*/
function PropertysTerminalExpression(propName) {
this.propName = propName;
}
PropertysTerminalExpression.prototype = {
interpret: function (context) {
var eles = context.getPreEles();
var ss = [];
for (var i = 0, len = eles.length; i ss.push(eles[i].getAttribute(this.propName));
}
return ss;
}
};
/**
* 以多个元素作为终结符的解释处理对象
* @param {[type]} name [description]
*/
function ElementsTerminalExpression(name) {
this.eleName = name;
}
ElementsTerminalExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var nowEles = [];
for (var i = 0, len = pEles.length; i nowEles = nowEles.concat(context.getNowEles(pEles[i], this.eleName));
}
var ss = [];
for (i = 0, len = nowEles.length; i ss.push(nowEles[i].firstChild.nodeValue);
}
return ss;
}
};
/**
* 多个元素作为非终结符的解释处理对象
*/
function ElementsExpression(name) {
this.eleName = name;
this.eles = [];
}
ElementsExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var nowEles = [];
for (var i = 0, len = pEles.length; i nowEles = nowEles.concat(context.getNowEles(pEles[i], this.eleName));
}
context.setPreEles(nowEles);
var ss;
for (i = 0, len = this.eles.length; i ss = this.eles[i].interpret(context);
}
return ss;
},
addEle: function (ele) {
this.eles.push(ele);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i if (ele === this.eles[i]) {
this.eles.splice(i--, 1);
}
}
return true;
}
};
void function () {
// "root/a/b/d$"
var c = new Context('Interpreter.xml');
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b');
var dEle = new ElementsTerminalExpression('d');
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(dEle);
var ss = root.interpret(c);
for (var i = 0, len = ss.length; i console.log('d的值是 = ' + ss[i]);
}
}();
void function () {
// a/b/d$.id$
var c = new Context('Interpreter.xml');
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b');
var dEle = new ElementsExpression('d');
var prop = new PropertysTerminalExpression('id');
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(dEle);
dEle.addEle(prop);
var ss = root.interpret(c);
for (var i = 0, len = ss.length; i console.log('d的属性id的值是 = ' + ss[i]);
}
}();
// 解析器
/**
* 解析器的实现思路
* 1.把客户端传递来的表达式进行分解,分解成为一个一个的元素,并用一个对应的解析模型来封装这个元素的一些信息。
* 2.根据每个元素的信息,转化成相对应的解析器对象。
* 3.按照先后顺序,把这些解析器对象组合起来,就得到抽象语法树了。
*
* 为什么不把1和2合并,直接分解出一个元素就转换成相应的解析器对象?
* 1.功能分离,不要让一个方法的功能过于复杂。
* 2.为了今后的修改和扩展,现在语法简单,所以转换成解析器对象需要考虑的东西少,直接转换也不难,但要是语法复杂了,直接转换就很杂乱了。
*/
/**
* 用来封装每一个解析出来的元素对应的属性
*/
function ParserModel() {
// 是否单个值
this.singleValue;
// 是否属性,不是属性就是元素
this.propertyValue;
// 是否终结符
this.end;
}
ParserModel.prototype = {
isEnd: function () {
return this.end;
},
setEnd: function (end) {
this.end = end;
},
isSingleValue: function () {
return this.singleValue;
},
setSingleValue: function (oneValue) {
this.singleValue = oneValue;
},
isPropertyValue: function () {
return this.propertyValue;
},
setPropertyValue: function (propertyValue) {
this.propertyValue = propertyValue;
}
};
var Parser = function () {
var BACKLASH = '/';
var DOT = '.';
var DOLLAR = '$';
// 按照分解的先后记录需要解析的元素的名称
var listEle = null;
// 开始实现第一步-------------------------------------
/**
* 传入一个字符串表达式,通过解析,组合成为一个抽象语法树
* @param {String} expr [描述要取值的字符串表达式]
* @return {Object} [对应的抽象语法树]
*/
function parseMapPath(expr) {
// 先按照“/”分割字符串
var tokenizer = expr.split(BACKLASH);
// 用来存放分解出来的值的表
var mapPath = {};
var onePath, eleName, propName;
var dotIndex = -1;
for (var i = 0, len = tokenizer.length; i onePath = tokenizer[i];
if (tokenizer[i + 1]) {
// 还有下一个值,说明这不是最后一个元素
// 按照现在的语法,属性必然在最后,因此也不是属性
setParsePath(false, onePath, false, mapPath);
} else {
// 说明到最后了
dotIndex = onePath.indexOf(DOT);
if (dotIndex >= 0) {
// 说明是要获取属性的值,那就按照“.”来分割
// 前面的就是元素名称,后面的是属性的名字
eleName = onePath.substring(0, dotIndex);
propName = onePath.substring(dotIndex + 1);
// 设置属性前面的那个元素,自然不是最后一个,也不是属性
setParsePath(false, eleName, false, mapPath);
// 设置属性,按照现在的语法定义,属性只能是最后一个
setParsePath(true, propName, true, mapPath);
} else {
// 说明是取元素的值,而且是最后一个元素的值
setParsePath(true, onePath, false, mapPath);
}
break;
}
}
return mapPath;
}
setend (Ende);
// Wenn es ein "$" -Symbol gibt, bedeutet es, dass es sich nicht um einen Wert
/ / entfernen "$"
ele = ele.replace (Dollar, ' ');
mapPath[ele] = pm;
listEle.push(ele);
}
// Beginnen Sie mit der Implementierung des zweiten Schritts ---------------------------------------

 從網站到應用程序:JavaScript的不同應用Apr 22, 2025 am 12:02 AM
從網站到應用程序:JavaScript的不同應用Apr 22, 2025 am 12:02 AMJavaScript在網站、移動應用、桌面應用和服務器端編程中均有廣泛應用。 1)在網站開發中,JavaScript與HTML、CSS一起操作DOM,實現動態效果,並支持如jQuery、React等框架。 2)通過ReactNative和Ionic,JavaScript用於開發跨平台移動應用。 3)Electron框架使JavaScript能構建桌面應用。 4)Node.js讓JavaScript在服務器端運行,支持高並發請求。
 Python vs. JavaScript:比較用例和應用程序Apr 21, 2025 am 12:01 AM
Python vs. JavaScript:比較用例和應用程序Apr 21, 2025 am 12:01 AMPython更適合數據科學和自動化,JavaScript更適合前端和全棧開發。 1.Python在數據科學和機器學習中表現出色,使用NumPy、Pandas等庫進行數據處理和建模。 2.Python在自動化和腳本編寫方面簡潔高效。 3.JavaScript在前端開發中不可或缺,用於構建動態網頁和單頁面應用。 4.JavaScript通過Node.js在後端開發中發揮作用,支持全棧開發。
 C/C在JavaScript口譯員和編譯器中的作用Apr 20, 2025 am 12:01 AM
C/C在JavaScript口譯員和編譯器中的作用Apr 20, 2025 am 12:01 AMC和C 在JavaScript引擎中扮演了至关重要的角色,主要用于实现解释器和JIT编译器。1)C 用于解析JavaScript源码并生成抽象语法树。2)C 负责生成和执行字节码。3)C 实现JIT编译器,在运行时优化和编译热点代码,显著提高JavaScript的执行效率。
 JavaScript在行動中:現實世界中的示例和項目Apr 19, 2025 am 12:13 AM
JavaScript在行動中:現實世界中的示例和項目Apr 19, 2025 am 12:13 AMJavaScript在現實世界中的應用包括前端和後端開發。 1)通過構建TODO列表應用展示前端應用,涉及DOM操作和事件處理。 2)通過Node.js和Express構建RESTfulAPI展示後端應用。
 JavaScript和Web:核心功能和用例Apr 18, 2025 am 12:19 AM
JavaScript和Web:核心功能和用例Apr 18, 2025 am 12:19 AMJavaScript在Web開發中的主要用途包括客戶端交互、表單驗證和異步通信。 1)通過DOM操作實現動態內容更新和用戶交互;2)在用戶提交數據前進行客戶端驗證,提高用戶體驗;3)通過AJAX技術實現與服務器的無刷新通信。
 了解JavaScript引擎:實施詳細信息Apr 17, 2025 am 12:05 AM
了解JavaScript引擎:實施詳細信息Apr 17, 2025 am 12:05 AM理解JavaScript引擎內部工作原理對開發者重要,因為它能幫助編寫更高效的代碼並理解性能瓶頸和優化策略。 1)引擎的工作流程包括解析、編譯和執行三個階段;2)執行過程中,引擎會進行動態優化,如內聯緩存和隱藏類;3)最佳實踐包括避免全局變量、優化循環、使用const和let,以及避免過度使用閉包。
 Python vs. JavaScript:學習曲線和易用性Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性Apr 16, 2025 am 12:12 AMPython更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 Python vs. JavaScript:社區,圖書館和資源Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:社區,圖書館和資源Apr 15, 2025 am 12:16 AMPython和JavaScript在社區、庫和資源方面的對比各有優劣。 1)Python社區友好,適合初學者,但前端開發資源不如JavaScript豐富。 2)Python在數據科學和機器學習庫方面強大,JavaScript則在前端開發庫和框架上更勝一籌。 3)兩者的學習資源都豐富,但Python適合從官方文檔開始,JavaScript則以MDNWebDocs為佳。選擇應基於項目需求和個人興趣。


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

ZendStudio 13.5.1 Mac
強大的PHP整合開發環境

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

SublimeText3漢化版
中文版,非常好用

記事本++7.3.1
好用且免費的程式碼編輯器

