


今天在MSDN查询优化建议中看到这样一条信息:SQL Server 会自动考虑索引交集并可以在同一查询中对 同一个表使用多个索引 (可能跟大家的理解有偏差)。 在解释之前我们先看一个例子: use AdventureWorks go select soh .* from sales . SalesOrderHeader AS
今天在MSDN查询优化建议中看到这样一条信息:SQL Server 会自动考虑索引交集并可以在同一查询中对同一个表使用多个索引(可能跟大家的理解有偏差)。
在解释之前我们先看一个例子:
useAdventureWorks
go
select soh.*
from sales.SalesOrderHeaderASsoh
WHERE soh.SalesPersonID= 276
and soh.OrderDatebetween'4/1/2002'and'7/1/2002'
查看执行计划:

虽然我们建立了SalesPersonID的非聚集索引,但是SQL Server并没有使用,因为OrderDate并没有包含在索引中。 相信这时候大部分的人会在索引上面加一列OrderDate.其实可以还可以有另外一种方法,不改变现在的索引,而新添加一个新索引。 这样SQL Server可以使用多个索引来完成本次查询,这个过程就是索引交集。
那么我们现在OrderDate上面创建一个索引:
CREATE NONCLUSTEREDINDEX[ix_orderdate]ON [Sales].[SalesOrderHeader]( [OrderDate]ASC)
增加索引后我们会看到下面的执行计划:

这次SQL Server使用了两个Non-clustered index seek,然后获得两个子集的索引交集,最后通过Keylookup获得所有输出字段.而通常我们认为一个对一个表的查询不会用到多个索引。其实SQLServer 优化引擎是可以使用到多个索引的优势。
上面的测试给我们一种启示,有的时候不一定要通过一个宽索引列(多个索引键值)提高性能,也可以通过多个窄索引键提升性能。另外如果你发现索引没有覆盖到所以的查询条件,但是你又不能直接改索引时,添加另外一个索引也可以满足你的要求。
而索引联接是索引交集的一个变种,如果查询能够从索引中直接获得所需要的数据,就会称为Index join(上面我们看到数据还是需要Key Lookup中获取,Index无法提供所有的数据).
更多信息可以参考:
http://msdn.microsoft.com/zh-cn/library/ms188722(v=sql.105).aspx
http://msdn.microsoft.com/zh-cn/library/aa226170(v=sql.70).aspx

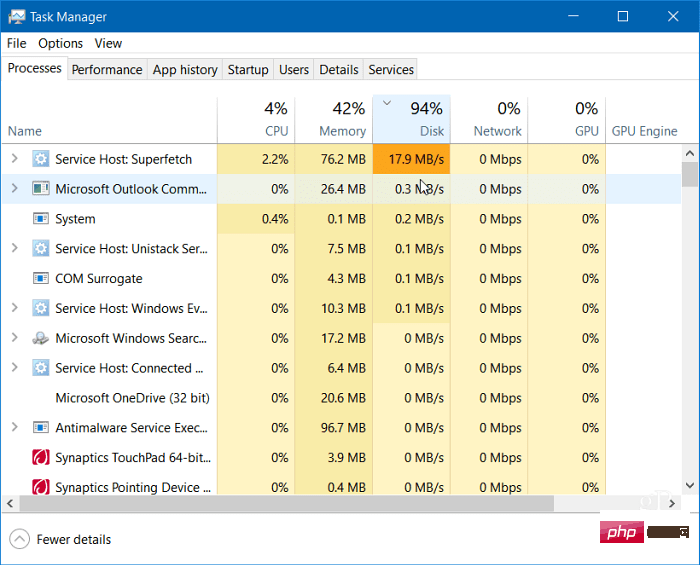 如何在 Windows 11 上修复 100% 的磁盘使用率Apr 20, 2023 pm 12:58 PM
如何在 Windows 11 上修复 100% 的磁盘使用率Apr 20, 2023 pm 12:58 PM如何在Window11上修复100%的磁盘使用率查找导致100%磁盘使用的有问题的应用程序或服务的直接方法是使用任务管理器。要打开任务管理器,请右键单击开始菜单并选择任务管理器。单击磁盘列标题,查看占用最多资源的内容。从那里开始,您将很好地了解从哪里开始。但是,问题可能比仅仅关闭应用程序或禁用服务更严重。继续阅读以查找问题的更多潜在原因以及如何解决这些问题。禁用SuperfetchSuperfetch功能(在Windows11中也称为SysMain)有助于通过访问预取文件来减少启动时
 SQL中的identity属性是什么意思?Feb 19, 2024 am 11:24 AM
SQL中的identity属性是什么意思?Feb 19, 2024 am 11:24 AMSQL中的Identity是什么,需要具体代码示例在SQL中,Identity是一种用于生成自增数字的特殊数据类型,它常用于唯一标识表中的每一行数据。Identity列通常与主键列配合使用,可以确保每条记录都有一个独一无二的标识符。本文将详细介绍Identity的使用方式以及一些实际的代码示例。Identity的基本使用方式在创建表时,可以使用Identit
 如何在 Windows 11 中隐藏文件和文件夹并从搜索中移除?Apr 26, 2023 pm 11:07 PM
如何在 Windows 11 中隐藏文件和文件夹并从搜索中移除?Apr 26, 2023 pm 11:07 PM<h2>如何在Windows11上从搜索中隐藏文件和文件夹</h2><p>我们首先要看的是自定义Windows搜索文件的位置。通过跳过这些特定位置,您应该可以更快地看到结果,同时还可以隐藏您想要保护的任何文件。</p><p>如果要从Windows11上的搜索中排除文件和文件夹,请使用以下步骤:</p><ol&
 SpringBoot怎么监听redis Key变化事件May 26, 2023 pm 01:55 PM
SpringBoot怎么监听redis Key变化事件May 26, 2023 pm 01:55 PM一、功能概览键空间通知使得客户端可以通过订阅频道或模式,来接收那些以某种方式改动了Rediskey变化的事件。所有修改key键的命令。所有接收到LPUSHkeyvalue[value…]命令的键。db数据库中所有已过期的键。事件通过Redis的订阅与发布功能(pub/sub)来进行分发,因此所有支持订阅与发布功能的客户端都可以在无须做任何修改的情况下,直接使用键空间通知功能。因为Redis目前的订阅与发布功能采取的是发送即忘(fireandforget)策略,所以如果你的程
 以下是6种修复Windows 11搜索栏不可用的方法。May 08, 2023 pm 10:25 PM
以下是6种修复Windows 11搜索栏不可用的方法。May 08, 2023 pm 10:25 PM如果您的搜索栏在Windows11中不起作用,有几种快速方法可以立即启动并运行!任何微软操作系统有时都可能遇到故障,最新的操作系统不能免除该规则。此外,正如Reddit上的用户u/zebra_head1所指出的那样,同样的错误出现在Windows11的22H2Build22621.1413上。用户抱怨切换任务栏搜索框的选项随机消失。因此,您必须为任何情况做好准备。为什么我无法在计算机上的搜索栏中键入内容?无法在计算机上键入可归因于不同的因素和过程。以下是您应该注意的一些事项:Ctfmon.
 华为 Mate 60 系列最佳入手时机,新增 AI 消除 + 影像升级,更可享秋日礼遇活动Aug 29, 2024 pm 03:33 PM
华为 Mate 60 系列最佳入手时机,新增 AI 消除 + 影像升级,更可享秋日礼遇活动Aug 29, 2024 pm 03:33 PM自去年华为Mate60系列开售以来,我个人就一直将Mate60Pro作为主力机使用。在将近一年的时间里,华为Mate60Pro经过多次OTA升级,综合体验有了显著提升,给人一种常用常新的感觉。比如近期,华为Mate60系列就再度迎来了影像功能的重磅升级。首先是新增AI消除功能,可以智能消除路人、杂物并对空白部分进行自动补充;其次是主摄色准、长焦清晰度均有明显升级。考虑到现在是开学季,华为Mate60系列还推出了秋日礼遇活动:购机可享至高800元优惠,入手价低至4999元。常用常新的产品力加上超值
 Unpatchable Yubico two-factor authentication key vulnerability breaks the security of most Yubikey 5, Security Key, and YubiHSM 2FA devicesSep 04, 2024 pm 06:32 PM
Unpatchable Yubico two-factor authentication key vulnerability breaks the security of most Yubikey 5, Security Key, and YubiHSM 2FA devicesSep 04, 2024 pm 06:32 PMAn unpatchable Yubico two-factor authentication key vulnerability has broken the security of most Yubikey 5, Security Key, and YubiHSM 2FA devices. The Feitian A22 JavaCard and other devices using Infineon SLB96xx series TPMs are also vulnerable.All
 redis批量删除key值的问题怎么解决May 31, 2023 am 08:59 AM
redis批量删除key值的问题怎么解决May 31, 2023 am 08:59 AM遇到的问题:在开发过程中,会遇到要批量删除某种规则的key,例如login_logID(ID为变量),现在需要删除"login_log*"这一类的数据,但是redis本身只有批量查询一类key值的命令keys,但是没有批量删除某一个类的命令。解决办法:先查询,在删除,使用xargs传参(xargs可以将管道或标准输入(stdin)数据转换成命令行参数),先执行查询语句,在将查询出来的key值,当初del的参数去删除。redis-cliKEYSkey*(查找条件)|xargsr


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

PhpStorm Mac 版本
最新(2018.2.1 )專業的PHP整合開發工具

Atom編輯器mac版下載
最受歡迎的的開源編輯器

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

禪工作室 13.0.1
強大的PHP整合開發環境

