



花了整整一个下午(6个多小时),整理总结,也算是对这方面有一个深度的了解。日后可以回头多看看。 我们都安装完Hadoop之后,按照一些案例先要跑一个WourdCount程序,来测试Hadoop安装是否成功。在终端中用命令创建一个文件夹,简单的向两个文件中各写入一
花了整整一个下午(6个多小时),整理总结,也算是对这方面有一个深度的了解。日后可以回头多看看。
我们都安装完Hadoop之后,按照一些案例先要跑一个WourdCount程序,来测试Hadoop安装是否成功。在终端中用命令创建一个文件夹,简单的向两个文件中各写入一段话,然后运行Hadoop,WourdCount自带WourdCount程序指令,就可以输出写入的那句话各个不同单词的个数。但是这不是这篇博客主要讲的内容,主要是想通过一个简单的Wordcount程序,来认识Hadoop的内部机制。并通过此来深入了解MapReduce的详细过程。在Thinking in BigDate(八)大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解中我们已经很大概梳理一下,Hadoop内部集群架构,并对MapReduce也有初步的了解,这里我们以WourdCount程序来深入的探讨MapReduce的过程。
利用命令行,测试WourdCount程序:
WourdCount程序就是统计文本中字母的个数
1、创建Wordcount示例文件
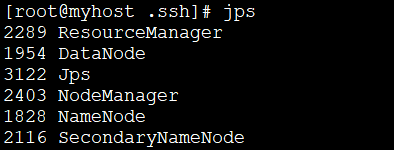
zhangzhen@ubuntu:~/software$ mkdir input zhangzhen@ubuntu:~/software$ cd input/ zhangzhen@ubuntu:~/software/input$ echo "I am zhangzhen">test1.txt zhangzhen@ubuntu:~/software/input$ echo "You are not zhangzhen">test2.txt zhangzhen@ubuntu:~/software/input$ cd ../hadoop-1.2.1/ zhangzhen@ubuntu:~/software/hadoop-1.2.1$ cd bin zhangzhen@ubuntu:~/software/hadoop-1.2.1/bin$ ls hadoop slaves.sh start-mapred.sh stop-mapred.sh hadoop-config.sh start-all.sh stop-all.sh task-controller hadoop-daemon.sh start-balancer.sh stop-balancer.sh hadoop-daemons.sh start-dfs.sh stop-dfs.sh rcc start-jobhistoryserver.sh stop-jobhistoryserver.sh zhangzhen@ubuntu:~/software/hadoop-1.2.1/bin$ jps(确定Hadoop已经起来了) 7101 SecondaryNameNode 7193 JobTracker 7397 TaskTracker 9573 Jps 6871 DataNode 6667 NameNode zhangzhen@ubuntu:~/software/hadoop-1.2.1/bin$ cd .. zhangzhen@ubuntu:~/software/hadoop-1.2.1$ ls bin data hadoop-minicluster-1.2.1.jar libexec share build.xml docs hadoop-test-1.2.1.jar LICENSE.txt src c++ hadoop-ant-1.2.1.jar hadoop-tools-1.2.1.jar logs webapps CHANGES.txt hadoop-client-1.2.1.jar ivy NOTICE.txt conf hadoop-core-1.2.1.jar ivy.xml README.txt contrib hadoop-examples-1.2.1.jar lib sbin zhangzhen@ubuntu:~/software/hadoop-1.2.1$ bin/hadoop dfs -put ../input in //把文件上传的hdfa中的in目录中,其实这个说法有误 zhangzhen@ubuntu:~/software/hadoop-1.2.1$ bin/hadoop dfs -ls .in/* ls: Cannot access .in/*: No such file or directory. zhangzhen@ubuntu:~/software/hadoop-1.2.1$ bin/hadoop dfs -ls ./in/* -rw-r--r-- 1 zhangzhen supergroup 15 2014-03-22 10:45 /user/zhangzhen/in/test1.txt -rw-r--r-- 1 zhangzhen supergroup 22 2014-03-22 10:45 /user/zhangzhen/in/test2.txt
注意:Hadoop中是没有当前目录这个概念的。所以上传到hdfs中的文件,我们是不能通过cd命令、ls命令,查看目录中的文件。这里我们通过就是上面和下面命令查看hdfs中文件的方法。
在每个版本中,hadoop-examples-1.2.1.jar的位置不一样,在Hadoop1.2.1版本中,我们hadoop-examples-1.2.1.jar文件是在Hadoop目录中的,这里我们需要把这个hadoop-examples-1.2.1.jar拷贝到/bin 目录中。
执行:利用hadoop-examples-1.2.1.jar执行bin目录下in目录中的文件,并把结果写入到 put 的文件夹。
zhangzhen@ubuntu:~/software$ bin/hadoop jar hadoop-examples-1.2.1.jar wordcount in put
查看输出的结果:
zhangzhen@ubuntu:~/software/hadoop-1.2.1$ bin/hadoop dfs -ls Found 2 items drwxr-xr-x - zhangzhen supergroup 0 2014-03-22 10:45 /user/zhangzhen/in drwxr-xr-x - zhangzhen supergroup 0 2014-03-22 10:56 /user/zhangzhen/put zhangzhen@ubuntu:~/software/hadoop-1.2.1$ bin/hadoop dfs -ls ./put Found 3 items -rw-r--r-- 1 zhangzhen supergroup 0 2014-03-22 10:56 /user/zhangzhen/put/_SUCCESS drwxr-xr-x - zhangzhen supergroup 0 2014-03-22 10:56 /user/zhangzhen/put/_logs 目录 -rw-r--r-- 1 zhangzhen supergroup 39 2014-03-22 10:56 /user/zhangzhen/put/part-r-00000 这是文件 zhangzhen@ubuntu:~/software/hadoop-1.2.1/hadoop dfs -cat ./put/* I 1 You 1 am 1 are 1 not 1 zhangzhen 2 cat: File does not exist: /user/zhangzhen/put/_logs zhangzhen@ubuntu:~/software/hadoop-1.2.1$
上面的结果,就基本可以证明Hadoop搭建是没有问题的。执行hadoop-examples-1.2.1.jar程序,其实是把java程序编译打成一个jar文件,然后直接运行,就可以得到结果。其实这也是以后我们运行java程序的一个方法。把程序编译打包上传,然后运行。还有另一种方面,eclipse连接Hadoop,可以联机测试。两种方法各有优点,不再详述。
运行的程序,我们可以在Hadoop的安装目录中找到源文件,WourdCount.java源代码。
zhangzhen@ubuntu:~/software/hadoop-1.2.1/src/examples/org/apache/hadoop/examples$ pwd /home/zhangzhen/software/hadoop-1.2.1/src/examples/org/apache/hadoop/examples zhangzhen@ubuntu:~/software/hadoop-1.2.1/src/examples/org/apache/hadoop/examples$
下面是把源代码拷到eclipse程序中,利用此代码(并未修改)测试一下实际的数据并得到结果。(注释是对上以一行的解释)
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Wordcount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
//规定map中用到的数据类型,这里的Text相当于jdk中的String IntWritable相当于jdk的int类型,
//这样做的原因主要是为了hadoop的数据序化而做的。
private final static IntWritable one = new IntWritable(1);
//声时一个IntWritable变量,作计数用,每出现一个key,给其一个value=1的值
private Text word = new Text();//用来暂存map输出中的key值,Text类型的
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
//这就是map函数,它是和Mapper抽象类中的相对应的,此处的Object key,Text value的类型和上边的Object,
//Text是相对应的,而且最好一样,不然的话,多数情况运行时会报错。
StringTokenizer itr = new StringTokenizer(value.toString());
//Hadoop读入的value是以行为单位的,其key为该行所对应的行号,因为我们要计算每个单词的数目,
//默认以空格作为间隔,故用StringTokenizer辅助做字符串的拆分,也可以用string.split("")来作。
while (itr.hasMoreTokens()) { //遍历一下每行字符串中的单词
word.set(itr.nextToken()); //出现一个单词就给它设成一个key并将其值设为1
context.write(word, one); //输出设成的key/value值
//上面就是map打散的过程
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
//reduce的静态类,这里和Map中的作用是一样的,设定输入/输出的值的类型
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
//由于map的打散,这里会得到如,{key,values}={"hello",{1,1,....}},这样的集合
sum += val.get();
//这里需要逐一将它们的value取出来予以相加,取得总的出现次数,即为汇和
}
result.set(sum); //将values的和取得,并设成result对应的值
context.write(key, result);
//此时的key即为map打散之后输出的key,没有变化,变化的时result,以前得到的是一个数字的集合,
//已经给算出和了,并做为key/value输出。
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); //取得系统的参数
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
//判断一下命令行输入路径/输出路径是否齐全,即是否为两个参数
System.err.println("Usage: wordcount <in> <out>");
System.exit(2); //若非两个参数,即退出
}
Job job = new Job(conf, "word count");
//此程序的执行,在hadoop看来是一个Job,故进行初始化job操作
job.setJarByClass(Wordcount.class);
//可以认为成,此程序要执行MyWordCount.class这个字节码文件
job.setMapperClass(TokenizerMapper.class);
//在这个job中,我用TokenizerMapper这个类的map函数
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
//在这个job中,我用IntSumReducer这个类的reduce函数
job.setOutputKeyClass(Text.class);
//在reduce的输出时,key的输出类型为Text
job.setOutputValueClass(IntWritable.class);
//在reduce的输出时,value的输出类型为IntWritable
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
//初始化要计算word的文件的路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
//初始化要计算word的文件的之后的结果的输出路径
System.exit(job.waitForCompletion(true) ? 0 : 1);
//提交job到hadoop上去执行了,意思是指如果这个job真正的执行完了则主函数退出了,若没有真正的执行完就退出了。
}
//参考:http://hi.baidu.com/erliang20088/item/ce550f2f088ff1ce0e37f930
}
WourdCount程序中隐藏的秘密
1、具体流程:
1)文件拆分成splits,由于测试用的文件较小,所以每个文件为一个split,并将文件按行分割形成

2)将分割好的

3)得到map方法输出的

2、Map Task的整体流程:
可以概括为5个步骤:
1)Read:Map Task通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。
2)Map:该阶段主要将解析出的key/value交给用户编写的map()函数处理,并产生一系列的key/value。
3)Collect:在用户编写的map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输入结果。在该函数内部,它会将生成的key/value分片(通过Partitioner),并写入一个环形内存缓冲区中。
4)Spill:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并,压缩等操作。
5)Combine:当所有数据处理完成后,Map Task对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
3、Reduce的整体流程:
可以概括为5个步骤:
1)Shuffle:也称Copy阶段。Reduce Task从各个Map Task上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阀值,则写到磁盘上,否则直接放到内存中。
2)Merge:在远程拷贝的同时,Reduce Task启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或者磁盘上文件过多。
3)Sort:按照MapReduce语义,用户编写的reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一 起,Hadoop采用了基于排序的策略。由于各个Map Task已经实现了对自己的处理结果进行了局部排序,因此,Reduce Task只需对所有数据进行一次归并排序即可。
4)Reduce:在该阶段中,Reduce Task将每组数据依次交给用户编写的reduce()函数处理。
5)Write:reduce()函数将计算结果写到HDFS。
通过一些博客对WourdCount的介绍示例,总结Map、Reduce的整个过程。加上Thinking in BigDate(八)大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解所将的内容,大致把整个文件数据处理的过程梳理一遍。但是还有很多细节没有讲明。如:Spill、Combine、Shuffle的过程,Shuffle整个MapReduce的核心。接下来,我们更深入了解MapReduce的过程,更深入的了解,便于我们在以后在操作Hadoop集群的过程中,有利于系统调优,甚至修改Hadoop源代码。
Copyright?BUAA

 Java错误:Hadoop错误,如何处理和避免Jun 24, 2023 pm 01:06 PM
Java错误:Hadoop错误,如何处理和避免Jun 24, 2023 pm 01:06 PMJava错误:Hadoop错误,如何处理和避免当使用Hadoop处理大数据时,常常会遇到一些Java异常错误,这些错误可能会影响任务的执行,导致数据处理失败。本文将介绍一些常见的Hadoop错误,并提供处理和避免这些错误的方法。Java.lang.OutOfMemoryErrorOutOfMemoryError是Java虚拟机内存不足的错误。当Hadoop任
 从零开始学Spring CloudJun 22, 2023 am 08:11 AM
从零开始学Spring CloudJun 22, 2023 am 08:11 AM作为一名Java开发者,学习和使用Spring框架已经是一项必不可少的技能。而随着云计算和微服务的盛行,学习和使用SpringCloud成为了另一个必须要掌握的技能。SpringCloud是一个基于SpringBoot的用于快速构建分布式系统的开发工具集。它为开发者提供了一系列的组件,包括服务注册与发现、配置中心、负载均衡和断路器等,使得开发者在构建微
 在Beego中使用Hadoop和HBase进行大数据存储和查询Jun 22, 2023 am 10:21 AM
在Beego中使用Hadoop和HBase进行大数据存储和查询Jun 22, 2023 am 10:21 AM随着大数据时代的到来,数据处理和存储变得越来越重要,如何高效地管理和分析大量的数据也成为企业面临的挑战。Hadoop和HBase作为Apache基金会的两个项目,为大数据存储和分析提供了一种解决方案。本文将介绍如何在Beego中使用Hadoop和HBase进行大数据存储和查询。一、Hadoop和HBase简介Hadoop是一个开源的分布式存储和计算系统,它可
 如何使用PHP和Hadoop进行大数据处理Jun 19, 2023 pm 02:24 PM
如何使用PHP和Hadoop进行大数据处理Jun 19, 2023 pm 02:24 PM随着数据量的不断增大,传统的数据处理方式已经无法处理大数据时代带来的挑战。Hadoop是开源的分布式计算框架,它通过分布式存储和处理大量的数据,解决了单节点服务器在大数据处理中带来的性能瓶颈问题。PHP是一种脚本语言,广泛应用于Web开发,而且具有快速开发、易于维护等优点。本文将介绍如何使用PHP和Hadoop进行大数据处理。什么是HadoopHadoop是
 探索Java在大数据领域的应用:Hadoop、Spark、Kafka等技术栈的了解Dec 26, 2023 pm 02:57 PM
探索Java在大数据领域的应用:Hadoop、Spark、Kafka等技术栈的了解Dec 26, 2023 pm 02:57 PMJava大数据技术栈:了解Java在大数据领域的应用,如Hadoop、Spark、Kafka等随着数据量不断增加,大数据技术成为了当今互联网时代的热门话题。在大数据领域,我们常常听到Hadoop、Spark、Kafka等技术的名字。这些技术起到了至关重要的作用,而Java作为一门广泛应用的编程语言,也在大数据领域发挥着巨大的作用。本文将重点介绍Java在大
 轻松学会win7怎么还原系统Jul 09, 2023 pm 07:25 PM
轻松学会win7怎么还原系统Jul 09, 2023 pm 07:25 PMwin7系统自带有备份还原系统的功能,如果之前有给win7系统备份的话,当电脑出现系统故障的时候,我们可以尝试通过win7还原系统修复。那么win7怎么还原系统呢?下面小编就教下大家如何还原win7系统。具体的步骤如下:1、开机在进入Windows系统启动画面之前按下F8键,然后出现系统启动菜单,选择安全模式登陆即可进入。2、进入安全模式之后,点击“开始”→“所有程序”→“附件”→“系统工具”→“系统还原”。3、最后只要选择最近手动设置过的还原点以及其他自动的还原点都可以,但是最好下一步之前点击
 学习PHP中的PHPUNIT框架Jun 22, 2023 am 09:48 AM
学习PHP中的PHPUNIT框架Jun 22, 2023 am 09:48 AM随着Web应用程序的需求越来越高,PHP技术在开发领域中变得越来越重要。在PHP开发方面,测试是一个必要的步骤,它可以帮助开发者确保他们创建的代码在各种情况下都可靠和实用。在PHP中,一个流行的测试框架是PHPUnit。PHPUnit是一个基于Junit的测试框架,其目的是创建高质量、可维护和可重复的代码。下面是一些学习使用PHPUnit框架的基础知识和步骤
 linux下安装Hadoop的方法是什么May 18, 2023 pm 08:19 PM
linux下安装Hadoop的方法是什么May 18, 2023 pm 08:19 PM一:安装JDK1.执行以下命令,下载JDK1.8安装包。wget--no-check-certificatehttps://repo.huaweicloud.com/java/jdk/8u151-b12/jdk-8u151-linux-x64.tar.gz2.执行以下命令,解压下载的JDK1.8安装包。tar-zxvfjdk-8u151-linux-x64.tar.gz3.移动并重命名JDK包。mvjdk1.8.0_151//usr/java84.配置Java环境变量。echo'


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

SublimeText3漢化版
中文版,非常好用

WebStorm Mac版
好用的JavaScript開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

SublimeText3 Linux新版
SublimeText3 Linux最新版

