


SQL Server Statistics and Cost Estimation 统计信息(Statistics)会干扰查询优化器(Query Optimizer)生成最优的执行计划。它存储的是表列或者索引列的数值分布统计,也称为柱状统计Histogram。统计信息的过期或者不充分,都能导致优化器评估成本模型(Cost-
SQL Server Statistics and Cost Estimation
统计信息(Statistics)会干扰查询优化器(Query Optimizer)生成最优的执行计划。它存储的是表列或者索引列的数值分布统计,也称为柱状统计Histogram。统计信息的过期或者不充分,都能导致优化器评估成本模型(Cost-Based Estimation)失效。所以我们就要时刻监控统计信息的有效性,采取适当的技术手段来保证它的时效性。
先从概念说起,我们看下SQL SERVER是如何启动Statistics这个特性的。如果没有启动我们就要手工启动:
<code class=" hljs cs"><span class="hljs-keyword">select</span> name,is_auto_create_stats_incremental_on,is_auto_update_stats_on,is_auto_update_stats_async_on ,is_auto_create_stats_on <span class="hljs-keyword">from</span> sys.databases <span class="hljs-keyword">where</span> name = <span class="hljs-string">'lenistest4'</span></code>
上面的查询就能判断特定的数据库是不是启动了自动更新统计信息的特性。那么如果统计信息经常自动更新,加上又是数据量极大,频率又非常快的话,就会使查询优化器经常被自动更新给拖累,也就是经常等待自动更新的完成而不能很快给查询做出即时的执行计划,这个时候就有2种方法可以选了:一是设置一个维护窗口,让服务器在这一个窗口内更新统计信息,而自动更新统计信息这个开关就可以关闭了;二是开启is_auto_upadte_stats_async_on,这个选项是可以让统计信息的更新在晚点的时刻进行更新,而不是在更新完数据后,马上就更新。这里“晚点”的时刻概念是指,query optimizer并不会理会当前的statistics是不是最新的,而是直接按照当前的统计信息来判断最优的执行计划,而由另一根后台线程在当前的优化器在编译的时候,去更新统计信息。
如何启动异步更新统计信息 is_auto_update_stats_async_on呢?在开启之前,Auto_update_statistics也需要同时启动。
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">alter</span> <span class="hljs-keyword">database</span> lenistest4 <span class="hljs-keyword">set</span> auto_update_statistics <span class="hljs-keyword">on</span> <span class="hljs-keyword">alter</span> <span class="hljs-keyword">database</span> lenistest4 <span class="hljs-keyword">set</span> auto_update_statistics_async <span class="hljs-keyword">on</span></span></code>
is_auto_create_stats_incremental_on 这个选项,是为了更新partition信息而设置的。如果设置为off,则整个statistics tree就丢弃了,而需要重新计算。通常partition的统计信息是不需要全表扫描的,只需扫描需要更新的partition的数据就可以了。
我们可以用dbcc show_statistics来查看对应的表,试图,索引的统计信息:
1 找到对应表的统计对象(statistics object):
<code class=" hljs cs"><span class="hljs-keyword">select</span> * <span class="hljs-keyword">from</span> sys.stats <span class="hljs-keyword">where</span> object_id = object_id(N<span class="hljs-string">'dbo.cdc_driven'</span>)</code>
2 将表 以及对应的统计对象传给 dbcc show_statistics函数:
<code class=" hljs bash">dbcc show_statistics (<span class="hljs-string">'dbo.cdc_driven'</span>,<span class="hljs-string">'_WA_Sys_00000002_32E0915F'</span>)</code>
还可以使用create statistics 来给我们想要的列(column)加上统计信息:
<code class=" hljs livecodeserver"><span class="hljs-built_in">create</span> statistics statsofCDCdriven <span class="hljs-command"><span class="hljs-keyword">on</span> <span class="hljs-title">dbo</span>.<span class="hljs-title">cdc_driven</span>(<span class="hljs-title">cdcMinLsn</span>)</span></code>
同样,我们可以使用 dbcc show_statistics ('dbo.cdc_driven','statsofCDCdriven') 来查看统计信息的具体内容。
这里要注意的是,
<code class=" hljs scss">dbcc <span class="hljs-function">show_statistics(table_view_index_name, column_statisticsobject_name)</span>,</code>
这里如果没有为column创建自动统计信息更新的话,会报错误:
<code class=" hljs livecodeserver">dbcc show_statistics(<span class="hljs-string">'dbo.cdc_driven'</span>,[cdcMinLsn]) Msg <span class="hljs-number">2767</span>, Level <span class="hljs-number">16</span>, State <span class="hljs-number">1</span>, Line <span class="hljs-number">31</span> Could <span class="hljs-operator">not</span> locate statistics <span class="hljs-string">'cdcMinLsn'</span> <span class="hljs-operator">in</span> <span class="hljs-operator">the</span> <span class="hljs-keyword">system</span> catalogs. DBCC execution completed. If DBCC printed error messages, contact your <span class="hljs-keyword">system</span> administrator.</code>
这里等的自动统计信息更新,其实指的就是非SQL语句创建的statistics。上面的例子就证明了,只要一个column有了相应的statistics object,那么显示这个column对应的统计信息,在dbcc show_statistics中就不能用column,而只能用statistics object了。

DBCC SHOW_Statistics会返回三个结果集,分别是header, the density vector和the histogram。如果想要返回三者之一 ,在dbcc show_statistics的时候要加上with option,比如:
<code class=" hljs javascript">dbcc show_statistics (<span class="hljs-string">'dbo.cdc_driven'</span>,<span class="hljs-string">'statsofCDCdriven'</span>) dbcc show_statistics (<span class="hljs-string">'dbo.cdc_driven'</span>,<span class="hljs-string">'_WA_Sys_00000002_32E0915F'</span>) <span class="hljs-keyword">with</span> histogram dbcc show_statistics (<span class="hljs-string">'dbo.cdc_driven'</span>,<span class="hljs-string">'_WA_Sys_00000002_32E0915F'</span>) <span class="hljs-keyword">with</span> stat_header dbcc show_statistics (<span class="hljs-string">'dbo.cdc_driven'</span>,<span class="hljs-string">'_WA_Sys_00000002_32E0915F'</span>) <span class="hljs-keyword">with</span> density_vector</code>
有意思的是,_WA,这里是指 Washington, the state of the United Stats where the SQL Server development team is located。 SQL SERVER开发小组所在地。[00000002]在这里指的是column id, [32E0915F]是object_id:
<code class=" hljs cs"><span class="hljs-keyword">select</span> object_id(N<span class="hljs-string">'dbo.cdc_driven'</span>) <span class="hljs-keyword">select</span> convert(bigint, <span class="hljs-number">0x32E0915F</span>)</code>

这里density_vector结果集里面的[All Density]是所有唯一值的总数的倒数,即 1/countof(all distinct values)。 与header结果集里面的density不同,header结果集里面的density已经弃用了。
<code class=" hljs oxygene">dbcc show_statistics(<span class="hljs-string">'dbo.fctdbsize'</span>,<span class="hljs-string">'dt_ty_nm_size'</span>) <span class="hljs-keyword">with</span> density_vector <span class="hljs-keyword">select</span> <span class="hljs-number">1.0000</span>/count(<span class="hljs-keyword">distinct</span> record_date) <span class="hljs-keyword">from</span> dbo.fctdbsize</code>

这里4.228509E-05,指的是4.228509*10(-5)。Density就是数据密度,对Group By 是有优化提示作用的。
Histogram又是另一种数据统计信息表达方式,每个statistics object的第一个column就有一个histogram, 它把数据 压缩后平均分配到 200个subset或者step,bcukets里面去。如果数据超过 200个bucket,那么就用算法算出最近频繁使用的数据。这个算法是maxdiff的一种变形,让一个range尽量去覆盖最大的数值空间。
Statistics的维护:刚才我们在谈到这个属性 is_auto_update_statistics_asnyc_on时,建议维护statistics的最佳方法是放在一个维护窗口期,更有可能的话应该放在index rebuilt或者碎片化整理之后,这样对于index statistics的维护更新也更有利,既节约了时间,还能使用full scan 对全表做抽样:
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">update</span> statistics dbo.cdc_driven statsofCDCdriven <span class="hljs-keyword">with</span> fullscan</span></code>
update statistics是最细粒度的更新语法,任何其他的统计信息更新方法都要调用到这个方法。像sp_updateStats。当然我们还是要知道update statistics是怎么工作的。
在更新统计信息之前,先截图保存当前的统计信息:
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">select</span> * <span class="hljs-keyword">from</span> sys.stats <span class="hljs-keyword">where</span> object_id = object_id(<span class="hljs-string">'dbo.cdc_driven'</span>) dbcc show_statistics (<span class="hljs-string">'dbo.cdc_driven'</span>,statsofCDCdriven) <span class="hljs-keyword">with</span> stat_header dbcc show_statistics (<span class="hljs-string">'dbo.cdc_driven'</span>,_WA_Sys_00000002_32E0915F) <span class="hljs-keyword">with</span> stat_header dbcc show_statistics (<span class="hljs-string">'dbo.cdc_driven'</span>,_WA_Sys_00000005_32E0915F) <span class="hljs-keyword">with</span> stat_header dbcc show_statistics (<span class="hljs-string">'dbo.cdc_driven'</span>,_WA_Sys_00000007_32E0915F) <span class="hljs-keyword">with</span> stat_header</span></code>

1 这里有 4 个统计信息对象(statistics object)。Sys.stats中的auto_create顾名思义就是系统自动创建的,而user_created则表示是用户自己创建的。
2 系统自建的这些统计信息对象,在小数据量下,更新的频率不好掌握,比如我根据这些自动更新统计信息的列查询了一些数据,统计信息并不自动更新。而且当我更新了或者插入了新的数据,统计信息依旧不更新,不管是index还是column,或者新建的statistics objects.
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">insert</span> <span class="hljs-keyword">into</span> dbo.cdc_driven(transactionId,cdcId,cdcStartDT,cdcEndDT,cdcCompleted,cdcMinLsn,cdcMaxLsn) <span class="hljs-keyword">select</span> transactionId,cdcId,cdcStartDT,cdcEndDT,cdcCompleted,cdcMinLsn,cdcMaxLsn <span class="hljs-keyword">from</span> dbo.cdc_driven <span class="hljs-keyword">select</span> * <span class="hljs-keyword">from</span> sys.stats <span class="hljs-keyword">where</span> object_id = object_id(<span class="hljs-string">'dbo.cdc_driven'</span>) dbcc show_statistics (<span class="hljs-string">'dbo.cdc_driven'</span>,statsofCDCdriven) <span class="hljs-keyword">with</span> stat_header dbcc show_statistics (<span class="hljs-string">'dbo.cdc_driven'</span>,_WA_Sys_00000002_32E0915F) <span class="hljs-keyword">with</span> stat_header dbcc show_statistics (<span class="hljs-string">'dbo.cdc_driven'</span>,_WA_Sys_00000005_32E0915F) <span class="hljs-keyword">with</span> stat_header dbcc show_statistics (<span class="hljs-string">'dbo.cdc_driven'</span>,_WA_Sys_00000007_32E0915F) <span class="hljs-keyword">with</span> stat_header dbcc show_statistics (<span class="hljs-string">'dbo.cdc_driven'</span>,idx_cdcid) <span class="hljs-keyword">with</span> stat_header <span class="hljs-keyword">select</span> <span class="hljs-aggregate">count</span>(*) <span class="hljs-keyword">from</span> dbo.cdc_driven</span></code>

3 如果我创建一个index,系统会添加一个index 的统计信息对象,名称就是index名字。而且auto_created,user_created都为0。并且都是基于最新的数据作统计 。
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">create</span> index idx_cdcid <span class="hljs-keyword">on</span> dbo.cdc_driven(cdcId) <span class="hljs-keyword">go</span> <span class="hljs-keyword">select</span> * <span class="hljs-keyword">from</span> sys.stats <span class="hljs-keyword">where</span> object_id = object_id(<span class="hljs-string">'dbo.cdc_driven'</span>) dbcc show_statistics (<span class="hljs-string">'dbo.cdc_driven'</span>,statsofCDCdriven) <span class="hljs-keyword">with</span> stat_header dbcc show_statistics (<span class="hljs-string">'dbo.cdc_driven'</span>,_WA_Sys_00000002_32E0915F) <span class="hljs-keyword">with</span> stat_header dbcc show_statistics (<span class="hljs-string">'dbo.cdc_driven'</span>,_WA_Sys_00000005_32E0915F) <span class="hljs-keyword">with</span> stat_header dbcc show_statistics (<span class="hljs-string">'dbo.cdc_driven'</span>,_WA_Sys_00000007_32E0915F) <span class="hljs-keyword">with</span> stat_header dbcc show_statistics (<span class="hljs-string">'dbo.cdc_driven'</span>,idx_cdcid) <span class="hljs-keyword">with</span> stat_header</span></code>

4 所以基于这些统计信息自动更新不好掌握的情况,我们就手工来执行更新。综上, 一个表可能会有三种统计信息对象:statistics object, column, index。
Statistics object的更新:
<code class=" hljs fsharp"><span class="hljs-keyword">use</span> lenistest4 go update statistics dbo.cdc_driven statsofCDCdriven <span class="hljs-keyword">with</span> fullscan</code>
注意table, statistics object的顺序,table 在前,statistics object 在后
Column statistics的更新:
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">update</span> statistics dbo.cdc_driven <span class="hljs-keyword">with</span> fullscan ,columns</span></code>
Index Statistics的更新:
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">update</span> statistics dbo.cdc_driven <span class="hljs-keyword">with</span> fullscan ,index</span></code>
如果要全部更新,加上 all :
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">update</span> statistics dbo.cdc_driven <span class="hljs-keyword">with</span> fullscan ,<span class="hljs-keyword">all</span></span></code>
Statistics失灵的地方:函数式列匹配。我们先创建一个索引,比如:
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">create</span> index idx_size <span class="hljs-keyword">on</span> dbo.fctdbsize(<span class="hljs-keyword">size</span>) <span class="hljs-keyword">go</span> <span class="hljs-keyword">select</span> <span class="hljs-aggregate">count</span>(*) <span class="hljs-keyword">from</span> dbo.fctdbsize <span class="hljs-keyword">where</span> <span class="hljs-keyword">size</span> > <span class="hljs-number">10000</span></span></code>

<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">select</span> <span class="hljs-aggregate">count</span>(*) <span class="hljs-keyword">from</span> dbo.fctdbsize <span class="hljs-keyword">where</span> convert(<span class="hljs-keyword">int</span>,<span class="hljs-keyword">size</span>) > <span class="hljs-number">10000</span></span></code>
这里列加了函数就不能走index seek而只能index scan 了。

这里和oracle的函数索引就不一样了。但是我们还是可以让这个查询走上索引的道路,用scalar expression column。我们可以将convert(int,size)创建成一个列,加个索引,然后就能用上statistics了和索引了
<code class=" hljs livecodeserver"><span class="hljs-built_in">create</span> index idx_size_int <span class="hljs-command"><span class="hljs-keyword">on</span> <span class="hljs-title">dbo</span>.<span class="hljs-title">fctdbsize</span>(<span class="hljs-title">size_int</span>)</span></code>
这里statistics的真正用法是建立scalar expression column之后,这个column 的statistics就能上了,比如:
没有建立scalar expression column之前 :
<code class=" hljs cs"><span class="hljs-keyword">select</span> * <span class="hljs-keyword">from</span> dbo.cdc_driven <span class="hljs-keyword">where</span> datediff(ms,cdcStartDT,cdcEndDT) > <span class="hljs-number">1</span></code>
这里estimated number of rows是6.6, 而actual number of rows是20, 所以并不准确;


然后,我们建立一个computed column也就是scalar expression column,
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">alter</span> <span class="hljs-keyword">table</span> dbo.cdc_driven <span class="hljs-keyword">add</span> dur_cdc <span class="hljs-keyword">as</span> datediff(ms,cdcStartDT,cdcEndDT) <span class="hljs-keyword">select</span> * <span class="hljs-keyword">from</span> dbo.cdc_driven <span class="hljs-keyword">where</span> dur_cdc > <span class="hljs-number">1</span></span></code>
或者:
<code class=" hljs cs"><span class="hljs-keyword">select</span> * <span class="hljs-keyword">from</span> dbo.cdc_driven <span class="hljs-keyword">where</span> datediff(ms,cdcStartDT,cdcEndDT) > <span class="hljs-number">1</span></code>
这里estimated number of rows就和actual number of rows一样了 。可见统计信息可以建立在computed column之上,提高优化器的准确性。

这里的策略其实是以空间换取时间,一种折中的办法。
还有一种奇特的statistics,叫做filtered statistics,他的语法是这样的:
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">create</span> statistics dur_minlsn <span class="hljs-keyword">on</span> dbo.cdc_driven(cdcMinLsn) <span class="hljs-keyword">where</span> cdcStartDT > convert(datetime2, <span class="hljs-string">'2016-04-24'</span>)</span></code>
察看这个statistics的形态:
<code class=" hljs javascript">dbcc show_statistics (<span class="hljs-string">'dbo.cdc_driven'</span>,dur_minlsn ) <span class="hljs-keyword">with</span> stat_header。</code>
这里有意思的是 Unfiltered Rows,它指的是在statistics object创建的时候,表总共有的数据量。

但是filter不能使用computed column,也不能使用scalar expression。
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">create</span> statistics dur_minlsn <span class="hljs-keyword">on</span> dbo.cdc_driven(cdcMinLsn) <span class="hljs-keyword">where</span> datediff(ms,cdcStartDT,cdcEndDT) > <span class="hljs-number">1</span> <span class="hljs-keyword">create</span> statistics dur_minlsn <span class="hljs-keyword">on</span> dbo.cdc_driven(cdcMinLsn) <span class="hljs-keyword">where</span> dur_cdc > <span class="hljs-number">1</span></span></code>
类似的错误有 :
<code class=" hljs applescript">Msg <span class="hljs-number">10609</span>, Level <span class="hljs-number">16</span>, State <span class="hljs-number">1</span>, Line <span class="hljs-number">14</span> Filtered statistics 'dur_minlsn' cannot be created <span class="hljs-function_start"><span class="hljs-keyword">on</span></span> table 'dbo.cdc_driven' because <span class="hljs-keyword">the</span> column 'dur_cdc' <span class="hljs-keyword">in</span> <span class="hljs-keyword">the</span> filter expression <span class="hljs-keyword">is</span> a computed column. Rewrite <span class="hljs-keyword">the</span> filter expression so <span class="hljs-keyword">that</span> <span class="hljs-keyword">it</span> <span class="hljs-keyword">does</span> <span class="hljs-keyword">not</span> include this column.</code>
Cardinality基数的估计错误会导致优化器不能很好的挑选最优执行计划,所以这个时候,我们要看是不是statistics没有正确被更新,或者压根就没statistics。怎么去判断statistics的错误呢? 只要看estimated number of rows 和actual number of rows是不是对得上,就可以了:
<code class=" hljs vbnet"><span class="hljs-keyword">set</span> statistics profile <span class="hljs-keyword">on</span> <span class="hljs-keyword">select</span> * <span class="hljs-keyword">from</span> dbo.cdc_driven <span class="hljs-keyword">where</span> datediff(ms,cdcStartDT,getutcdate()) > <span class="hljs-number">1</span> <span class="hljs-keyword">set</span> statistics profile <span class="hljs-keyword">off</span></code>
对不上怎么办,看情况。像上面这种函数式判断条件,我们可以创建computed column来解决。
Undocumented Options: ROWCOUNT & PageCount: 引导优化器产生小表或者大表的执行计划:
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">select</span> * <span class="hljs-keyword">from</span> sys.stats <span class="hljs-keyword">where</span> object_id = object_id(N<span class="hljs-string">'dbo.cdc_driven'</span>) <span class="hljs-keyword">select</span> object_name(object_id) <span class="hljs-keyword">as</span> objectName,index_id,<span class="hljs-keyword">rows</span> <span class="hljs-keyword">from</span> sys.partitions <span class="hljs-keyword">where</span> object_id = object_id(N<span class="hljs-string">'dbo.cdc_driven'</span>) <span class="hljs-keyword">select</span> object_name(object_id) <span class="hljs-keyword">as</span> objectName,index_id,partition_id,row_count,used_page_count <span class="hljs-keyword">from</span> sys.dm_db_partition_stats <span class="hljs-keyword">where</span> object_id = object_id(N<span class="hljs-string">'dbo.cdc_driven'</span>)</span></code>

<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">update</span> statistics dbo.cdc_driven <span class="hljs-keyword">with</span> ROWCOUNT = <span class="hljs-number">1000000</span>, PAGECOUNT = <span class="hljs-number">1000000</span></span></code>

成本估计 - cost estimated: 查询优化器并不会遍历或者穷举所有的执行计划,并对所有的执行计划都做一边成本估算,从而来选择最优的执行计划,而是一旦计算出一个可行的执行计划并且该计划的成本相对低廉有效,就立即执行。那么这里对成本的定义就很重要了。
1 成本估算有CPU,IO, Memory的估算。我们用table scan的方式来查找一张表的部分数据再观察这个执行的计划的成本
<code class=" hljs cs"><span class="hljs-keyword">select</span> * <span class="hljs-keyword">from</span> dbo.cdc_driven <span class="hljs-keyword">where</span> cdcStartDT >=<span class="hljs-string">'2016-2-23'</span></code>

这里显示的 Estimated I/O Cost 有 740.743, Estimated CPU Cost 有1.10016, Estimated Operator Cost是前面两部分的总和 741.843. Cost的单位是什么?将每一个operator的estimated cost相加,成为这个执行计划的成本估算,一旦合理就执行 。 每个operator的成本如下图可见:

Execution Engine
1 数据访问操作符号
Scan:并不保证是排过序的,除非使用了order by
Seek: non-heap table才有可能用到seek.
Bookmark Lookup: RID lookup
2 聚合运算符号
Sort:
Hash:
Stream Aggregation and Hash Aggregation (Union: Sum: Count: )
3 一次元操作符号
Scalar Expression:
4 Join操作符
Nested Loop:
Merge join:
Hash Join:对两者中较小的表创建一个has table。
5 Parallel运算符
The Optimization Process
1. 整个query optimization的进程 : 软解析和硬解析:软解析从语法到对象绑定;硬解析,除了进行软解析之外,还需要进行执行计划的优化,包括评估计划模型成本,生成计划的物理操作。怎么让语句只进行软解析,将软解析的错误异常先抛出来?
解析语法可以用: set parseonly on
<code class=" hljs cs"><span class="hljs-keyword">select</span> top <span class="hljs-number">2</span> * <span class="hljs-keyword">from</span> dbo.cdc_driven</code>


<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">set</span> parseonly <span class="hljs-keyword">on</span> <span class="hljs-keyword">select</span> Id,LastUpdated <span class="hljs-keyword">from</span> dbo.cdc_driven</span></code>
这里不管表里面有没有这个字段,都可以解析成功,不会有任何错误。
但是如果我们的语法错误了,就要报错了:

这里多了一个逗号,语法错误。
进行name resolution的时候,也就是在binding这个环节,会检查所有在语句中引用到的对象,是不是都存在,不存在就报错。这个时候还没有执行SQL 。
<code class=" hljs vbnet">begin <span class="hljs-keyword">try</span> <span class="hljs-keyword">declare</span> @sqlstatement nvarchar(max) = <span class="hljs-comment">'set noexec on</span> <span class="hljs-keyword">select</span> transactionid,cdcId,cdcStartDT <span class="hljs-keyword">from</span> dbo.cdc_driven<span class="hljs-comment">'</span> exec sp_executesql @stat = @sqlstatement <span class="hljs-keyword">end</span> <span class="hljs-keyword">try</span> begin <span class="hljs-keyword">catch</span> <span class="hljs-keyword">select</span> ERROR_MESSAGE() <span class="hljs-keyword">end</span> <span class="hljs-keyword">catch</span></code>
这里我们故意把 transactionId这个字段改为 transactionid,大小写不匹配。结果就捕获了这个错误:

这里, set noexec on起到了只编译而不执行的作用。
2.DBCC TRACEON(3604):这里的作用是将DBCC的一些结果返回给客户端。关于flag 3604有说法:一般的 DBCC PAGE等命令,默认的输出不是输入命令的客户端(通常 是SSMS)。 开启 3604,就能使得返回结果输出到客户端。
<code class=" hljs scss">dbcc <span class="hljs-function">traceoff(<span class="hljs-number">3604</span>)</span> dbcc <span class="hljs-function">page(<span class="hljs-string">'lenistest4'</span>,<span class="hljs-number">1</span>,<span class="hljs-number">520</span>)</span></code>

<code class=" hljs scss">dbcc <span class="hljs-function">traceon(<span class="hljs-number">3604</span>)</span> dbcc <span class="hljs-function">page(<span class="hljs-string">'lenistest4'</span>,<span class="hljs-number">1</span>,<span class="hljs-number">520</span>)</span></code>

这里的DBCC PAGE 就是察看data page的一部分数据。如果拿到某一个表的所有page,我们可以用这个DMV sys.dm_db_database_page_allocations。
语法是这样的:
<code class=" hljs vhdl">sys.dm_db_database_page_allocations (@DatabaseId , @TableId , @IndexId , @PartionID , @Mode) Parameters : @DatabaseId :You need <span class="hljs-keyword">to</span> pass the required database ID. This parameter <span class="hljs-keyword">is</span> mandatory <span class="hljs-keyword">and</span> data <span class="hljs-keyword">type</span> <span class="hljs-keyword">of</span> this argument <span class="hljs-keyword">is</span> small <span class="hljs-typename">integer</span>. @TableId:You need <span class="hljs-keyword">to</span> pass the required table ID. This parameter <span class="hljs-keyword">is</span> optional <span class="hljs-keyword">and</span> data <span class="hljs-keyword">type</span> <span class="hljs-keyword">of</span> this argument <span class="hljs-keyword">is</span> <span class="hljs-typename">integer</span>. @IndexId:You need <span class="hljs-keyword">to</span> pass the required Index ID. This parameter <span class="hljs-keyword">is</span> optional <span class="hljs-keyword">and</span> data <span class="hljs-keyword">type</span> <span class="hljs-keyword">of</span> this argument <span class="hljs-keyword">is</span> <span class="hljs-typename">integer</span>. @PartionID:You need <span class="hljs-keyword">to</span> pass the required Partion ID. This parameter <span class="hljs-keyword">is</span> optional <span class="hljs-keyword">and</span> data <span class="hljs-keyword">type</span> <span class="hljs-keyword">of</span> this argument <span class="hljs-keyword">is</span> <span class="hljs-typename">integer</span>. @Mode:You need <span class="hljs-keyword">to</span> pass the required Mode. This parameter <span class="hljs-keyword">is</span> mandatory <span class="hljs-keyword">and</span> data <span class="hljs-keyword">type</span> <span class="hljs-keyword">of</span> this argument <span class="hljs-keyword">is</span> nvarchar(<span class="hljs-number">64</span>). <span class="hljs-keyword">In</span> this argument we must pass only ‘DETAILED’ <span class="hljs-keyword">OR</span> ‘LIMITED’.</code>
<code class=" hljs cs"><span class="hljs-keyword">select</span> object_id,index_id,partition_id,extent_file_id,extent_page_id,allocated_page_iam_file_id,allocated_page_iam_page_id,allocated_page_file_id, allocated_page_page_id,is_iam_page,page_type_desc <span class="hljs-keyword">from</span> sys.dm_db_database_page_allocations( db_id(N<span class="hljs-string">'lenistest4'</span>),object_id(N<span class="hljs-string">'dbo.cdc_driven'</span>),<span class="hljs-number">0</span>,<span class="hljs-number">1</span>,<span class="hljs-string">'detailed'</span>)</code>

与sys.dm_db_index_physical_stats联合起来看,更能说明问题,毕竟sys.dm_db_database_page_allocations不是官方document的函数。
<code class=" hljs cs"><span class="hljs-keyword">select</span> object_id,index_id,partition_id,extent_file_id,extent_page_id,allocated_page_iam_file_id,allocated_page_iam_page_id,allocated_page_file_id, allocated_page_page_id,is_iam_page,page_type_desc <span class="hljs-keyword">from</span> sys.dm_db_database_page_allocations( db_id(N<span class="hljs-string">'lenistest4'</span>),object_id(N<span class="hljs-string">'dbo.cdc_driven'</span>),<span class="hljs-number">0</span>,<span class="hljs-number">1</span>,<span class="hljs-string">'detailed'</span>) <span class="hljs-keyword">select</span> * <span class="hljs-keyword">from</span> sys.dm_db_index_physical_stats (db_id(N<span class="hljs-string">'lenistest4'</span>),object_id(N<span class="hljs-string">'dbo.cdc_driven'</span>),<span class="hljs-number">0</span>,<span class="hljs-number">1</span>,<span class="hljs-string">'detailed'</span>)</code>

既然谈到了DBCC PAGE,我们把相关的概念都了解下:

这里的 GAM,SGAM, PFS, IAM 都分别代表了啥意思,要彻底了解这些概念的作用,我们就要知道在分配存储的时候,大概的过程是怎么样的,猜想下哪些关键流程可能会用到这些概念。
1). 数据页的分配是按照一个Extent来分的,不管需要多少page,首先会先分配一个Extent出来,一个Extent能包含多少page呢?8个连续的page成为一个Extent,共64KB.
2). Extent的原数据管理?怎么知道这些Extent是属于这个数据库的,多少个Extent已经申请分配了?
GAM(Global Allocation Map)就是用来查看哪些 extent已经被分配了, 哪些还没有?1 表示还没分配,0表示已经被分配了。 Bitmaps就是映射Extent的整体分配情况。
SGAP(Shared Global Allocation Map),混合extent的分配情况,1表示还没分配,0表示已经分配了(并且是mixed extent).什么叫 mixed extent?
3). Page有很多种, data page, index page, text or image page, GAM page, SGAM page.所以当一个extent有多种page存在的时候,就叫做 mixed extent.
4).GAM,SGAM,IAM的存储:这三种都是data page或者index data page.所以理应归档在Extent的范畴里面。当data file的第一个extent分配的时候,先产生一个GAM, 或者SGAM,当第一个index建立的时候,IAM 是第一个创建的page。这三种page只存储bitmaps而不存储数据或者 index data。一个page有8K,那么总共能有64000个Extent能被map到,大概是64000*64KB的数据量,即4GB。当过了4GB 之后,需要新建GAM,SGAM,IAM.
5). PFS: Page Free Space.每个page都会留点空间给修改或者insert。好处就是一个update不至于引起整个page或者一连串page的迁移。
3 SQL Server 有自己的优化步骤,可能soft parsing, hard parsing不适合T-SQL。它的专署流程是这样的: Parsing->Binding->Transformation->Simplification|Trivial Plan|Full Optimization->Execution. 从输出角度看,分别对应了 parse tree -> algebrized tree->memo(s)->execution plan->result
上面讲到parse和binding了,下面开始讨论transformation。
简单讲,transformation就是将sql源代码根据transformation rules转换成各种optimizer可以理解的逻辑和物理操作,这些转换后的表达式都放在叫做Memo的内存里面。问题来了,Memo究竟占用了多少内存,transformation的深度有多少,肯定不会是全部都遍历一边,那么规则是怎么样定的?最后一个问题,为什么要有transformation?其实这么问为什么要有transformation挺傻的,既然要有最优计划,当然是要罗列所有可能的执行路径了,比如join, 实际上可能有merge join, hash join等等, 那么将这些可能性都罗列出来才有可能进行下一步的比较。Transformation Rules有哪些呢?其实这里讲的就是将逻辑处理单元转成各种物理算法的转换规则,有可互换原则(commutative rules),可互协原则(associative rules),实现原则(implementation rules)等。Commutative rules就是 A JOIN B可换成B JOIN A; Associative Rules就是 (A JOIN B) JOIN C 可转成A JOIN (B JOIN C), Implementation Rule就是 A JOIN B转成 A MER JOIN B or A HASHJOIN B. 有意思的是,我们通过观察这个DMV, 可以看到很多的Transformation rules被用到了SQL Server里面:
<code class=" hljs cs"><span class="hljs-keyword">select</span> * <span class="hljs-keyword">from</span> sys.dm_exec_query_transformation_stats</code>
SQL SERVER 2014中已经到了394种 Transformation rules。如果一条SQL语句要经过这么多转换来获取最优的执行计划,本身就是耗费性能的一件事,而Memo中还只是存储了每个执行计划的成本,并没有生成这些执行计划的成本 。当然在我们非常熟练的情况下,我们可以禁用掉一些transformation rules,dbcc ruleson 和dbcc rulesoff 就是用来开启和禁用Transformation rules的命令。我们也可以用hint来忽略掉一些rules从而确保执行计划最优而不增加生成执行计划的成本。Hint显然比dbcc rulesoff有效的多,dbcc rulesoff在production环境引用的时候,会干扰所有执行计划,不建议使用 。通过截获SQL时间前后的sys.dm_exec_query_transformation_stats统计,我们可以看到所有transformation rules被用到了这个SQL里面,但是仅在你一个人用SERVER的情况下才正确。我们还可以使用 dbcc showoffrules可以看到当前SQL Server禁用掉的transformation rules.
<code class=" hljs scss">dbcc <span class="hljs-function">traceon(<span class="hljs-number">3604</span>)</span> dbcc showoffrules</code>
trace flag 3604表示将所有的dbcc 结果从默认的输出改到传输到客户端。
看下 transformation rules的整个过程,举一个简单的例子:
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">SELECT</span> FirstName, LastName, CustomerType <span class="hljs-keyword">FROM</span> Person.Contact <span class="hljs-keyword">AS</span> C <span class="hljs-keyword">JOIN</span> Sales.Individual <span class="hljs-keyword">AS</span> I <span class="hljs-keyword">ON</span> C.ContactID = I.ContactID <span class="hljs-keyword">JOIN</span> Sales.Customer <span class="hljs-keyword">AS</span> Cu <span class="hljs-keyword">ON</span> I.CustomerID = Cu.CustomerID</span></code>
这个查询就是join三张表,在Memo中,一个transformation就换到一个group里面。

上面的几个表格,就是各个transformation rule被应用到SQL上面的整个过程。第一张图,产生了一个transformation rule applied之后的逻辑执行树,Group 1,2,3,4,5分别代表了一个操作,Group 6是root节点,可以看到这里是从上到下的分层,最小的group是最先执行的。第二,第三个图是又产生了几个逻辑执行计划的结果 。第四张图很重要,就是最后一个环节,生成各种不同的物理执行计划,在这个时候,就会加上各个计划的成本了。实际上,这个时候还不是评估计划成本的时候,只不过已经生成了可以附加计划成本的对象而以,这个对象就是各种存在Memo里面的逻辑表示树
经过Transformation rules应用过滤后,就到最后一个优化环节了。 优化还有3个步骤,第一simplification, trivial plan以及full optimize。 Full Optimize还分 Search 0, Search 1, Search 2. Simplification 简单来讲概念就是去重,比如有where条件了,就不用Foreign Key约束,或者join的时候,提前将where条件放到join里面去做限制以减少数据集;Trivial Plan就是不经历full optimize 直接产生执行计划,这里要注意的执行计划属性StatementOptmLevel, 走Trivial Plan,他的值就是Trivial,如果不走Trivial Plan就是 Full(Optimize)。
Full Optimize的原则,从Search 0, Search 1, Search 2来分别做Transformation rule的应用,评估计划成本,任何一个stage出现最优计划,就直接使用。Search 0步骤做的主要工作就是更改Join Order来获取最小的数据集;Search 1接收到Search 0拿到的最优计划,进行parallel分析以得到最优计划,同样也要经过应用transformation rules, 在sys.dm_exec_query_optimizer_info这个DMV里面,有这么个Counter ,叫做 gain stageo 0 to stage1,表达的意思是stage1提升了多少成本,比如0.45923就是50%; Search 2叫做Full optimization,最终产生计划的地方,同样也有gain stage1 to stage2,表示提升的百分比 。Stage 2 (search 2)里面有个特别的概念,Time Out 事件。这个time out是通过transformation rules的应用状况和已经流失时间的总和计算的,如果超过这个时间,我们在执行计划的Reason For Early Termination Of Statement Optimization属性里看到Time Out,还可以在sys.dm_exec_query_optimizer_info DMV里面看到。这个 Time Out出现的时间也很有讲究,Search 0 这个阶段还处于改写逻辑树阶段,没有真正可用的执行计划产生,这个阶段没有Time Out事件。
一些有意思的话题,但是并不适合放在优化里面讲的,但是很重要也很有意思:
1 Query Parameter: 一种是SQL语句hard code参数,一种是参数探嗅(parameter sniffing).
Hard code 参数的示例:
<code class=" hljs vbnet"><span class="hljs-keyword">declare</span> @ptableName varchar(<span class="hljs-number">10</span>) = <span class="hljs-comment">'fctdbsize'</span> <span class="hljs-keyword">select</span> * <span class="hljs-keyword">from</span> sys.tables <span class="hljs-keyword">where</span> name = @ptableName</code>
另一种参数探嗅的示例:
<code class=" hljs cs"><span class="hljs-keyword">select</span> * <span class="hljs-keyword">from</span> sys.tables <span class="hljs-keyword">where</span> name = <span class="hljs-string">'fctdbsize'</span></code>
貌似上面一种情况是针对oracle优化器的,sql server优化器还没那么智能可以识别出这种参数探嗅的模式,只能对语句一模一样的SQL进行软解析。这里有特殊,除非是明显不会影响查询计划的参数化,比如用主键来做等于限制,无论怎么样都是做cluster index seek,所以SQL SERVER优化器就自动参数化了。
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">select</span> * <span class="hljs-keyword">from</span> dbo.dimstatisticscounters <span class="hljs-keyword">WHERE</span> row_id = <span class="hljs-number">2890</span></span></code>
dbo.dimstatisticscounters这个表以row_id作为主键,而且用了相等匹配模式 row_id = 2890,所以只走cluster index seek而且只返回一条数据 。这样的查询模式就会被自动参数化。

察看执行计划,这里有 where (row_Id) = @1 的提示 。
而且理论上, SQL TEXT也会被改写,但是这里并没有。
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">select</span> text <span class="hljs-keyword">from</span> sys.dm_exec_cached_plans cp <span class="hljs-keyword">cross</span> apply sys.dm_exec_sql_text(cp.plan_handle) <span class="hljs-keyword">where</span> text <span class="hljs-keyword">like</span> <span class="hljs-string">'%dimstatisticscounters WHERE row_id%'</span> [@<span class="hljs-number">1</span> <span class="hljs-keyword">int</span> ]<span class="hljs-keyword">select</span> * <span class="hljs-keyword">from</span> dbo.dimstatisticscounters <span class="hljs-keyword">WHERE</span> row_id = @<span class="hljs-number">1</span></span></code>
期望是这个 SQL TEXT, 结果并没有 。
当我们使用非主键作搜索时,就不会被参数化(这里貌似也可以做参数化,例子不好还是SQL SERVER 2014更改了?)
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">select</span> * <span class="hljs-keyword">from</span> dbo.dimstatisticscounters <span class="hljs-keyword">WHERE</span> counter_name > <span class="hljs-string">'Wait'</span></span></code>
由于这么多不确定性 ,我们还是使用sp_executesql来强制化走参数化以便降低解析成本 。
<code class=" hljs mel">declare <span class="hljs-variable">@stat</span> nvarchar(<span class="hljs-keyword">max</span>) = N<span class="hljs-string">'select * from dbo.dimstatisticscounters where row_id = @rowid'</span> <span class="hljs-keyword">exec</span> sp_executesql <span class="hljs-variable">@stmt</span> = <span class="hljs-variable">@stat</span>, <span class="hljs-variable">@params</span> = N<span class="hljs-string">'@rowid int'</span> , <span class="hljs-variable">@rowid</span> = <span class="hljs-number">121</span> (<span class="hljs-variable">@rowid</span> <span class="hljs-keyword">int</span>)<span class="hljs-keyword">select</span> * from dbo.dimstatisticscounters where row_id = <span class="hljs-variable">@rowid</span></code>
可见,省事儿多了。直接就根据参数编译了语句,生成的执行计划就再也不变了。
更多的是针对同一条带参数的查询 ,根据 column statistics的统计信息(histogram)来判断是走index scan还是index seek。为什么会有这两种执行方案呢? 还是要看index的存储信息来确定。假如index的Key存储了很多RID或者KEY,一边扫描就能找到很多记录(sequential read),而不象index seek,用的是random read就会慢很多。
<code class=" hljs oxygene"><span class="hljs-keyword">create</span> <span class="hljs-function"><span class="hljs-keyword">procedure</span> <span class="hljs-title">dbo</span>.<span class="hljs-title">gettopdbsize</span> <span class="hljs-params">(@dbsize int )</span> <span class="hljs-title">as</span> <span class="hljs-title">begin</span> <span class="hljs-title">select</span> <span class="hljs-title">top</span><span class="hljs-params">(10)</span> * <span class="hljs-title">from</span> <span class="hljs-title">dbo</span>.<span class="hljs-title">fctdbsize</span> <span class="hljs-title">where</span> <span class="hljs-title">size</span> = @<span class="hljs-title">dbsize</span> <span class="hljs-title">end</span> <span class="hljs-title">go</span></span></code>
根据 @dbsize的传入值,执行计划会有不同,seek与scan的区别。如果想要执行计划一直按照seek或者scan计算 ,我们可以用option(optimize for(@dbsize = 1000)) :
<code class=" hljs delphi">alter <span class="hljs-function"><span class="hljs-keyword">procedure</span> <span class="hljs-title">dbo</span>.<span class="hljs-title">gettopdbsize</span> <span class="hljs-params">(@dbsize int )</span> <span class="hljs-title">as</span> <span class="hljs-title">begin</span> <span class="hljs-title">select</span> <span class="hljs-title">top</span><span class="hljs-params">(10)</span> * <span class="hljs-title">from</span> <span class="hljs-title">dbo</span>.<span class="hljs-title">fctdbsize</span> <span class="hljs-title">where</span> <span class="hljs-title">size</span> = @<span class="hljs-title">dbsize</span> <span class="hljs-title">option</span><span class="hljs-params">(optimize <span class="hljs-keyword">for</span> (@dbsize = 100)</span>) <span class="hljs-title">end</span> <span class="hljs-title">go</span></span></code>
用本地变量来hard code参数,其实不会产生不同的执行计划,举个例子,我们将上面的存储过程改写,可以使得它只产生唯一计划:
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">alter</span> <span class="hljs-keyword">procedure</span> dbo.gettopdbsize (@dbsize <span class="hljs-keyword">int</span> ) <span class="hljs-keyword">as</span> <span class="hljs-keyword">begin</span> <span class="hljs-keyword">declare</span> @dbsize_local <span class="hljs-keyword">int</span> = @dbsize <span class="hljs-keyword">select</span> top(<span class="hljs-number">10</span>) * <span class="hljs-keyword">from</span> dbo.fctdbsize <span class="hljs-keyword">where</span> <span class="hljs-keyword">size</span> = @dbsize_local <span class="hljs-keyword">end</span> <span class="hljs-keyword">go</span></span></code>
用optimize for unknown也可以得到类似地功效:
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">alter</span> <span class="hljs-keyword">procedure</span> dbo.gettopdbsize (@dbsize <span class="hljs-keyword">int</span> ) <span class="hljs-keyword">as</span> <span class="hljs-keyword">begin</span> <span class="hljs-keyword">select</span> top(<span class="hljs-number">10</span>) * <span class="hljs-keyword">from</span> dbo.fctdbsize <span class="hljs-keyword">where</span> <span class="hljs-keyword">size</span> = @dbsize <span class="hljs-keyword">option</span>(optimize <span class="hljs-keyword">for</span> <span class="hljs-keyword">unknown</span>) <span class="hljs-keyword">end</span> <span class="hljs-keyword">go</span></span></code>
Hints, 唯一可以改变query optimizer产生执行计划的方法:
1 query hint : 用option来分隔SQL语句与hint语句
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">Select</span> xxx <span class="hljs-keyword">from</span> table_name <span class="hljs-keyword">option</span>(<span class="hljs-keyword">table</span> tableName index(indexName)): <span class="hljs-keyword">select</span> object_id,column_id ,column_name <span class="hljs-keyword">from</span> siebeldbTableSchema <span class="hljs-keyword">where</span> table_name = <span class="hljs-string">'S_CONTACT'</span> <span class="hljs-keyword">and</span> column_id = <span class="hljs-number">11</span> <span class="hljs-keyword">and</span> object_id = <span class="hljs-number">1415428562</span> <span class="hljs-keyword">option</span>( <span class="hljs-keyword">table</span> hint (siebeldbTableSchema,index(idx_colstr_sts)))</span></code>
这里还有这么一个坑,就是exposed object name必须和 from的表对象引用一致,否则出现类似这个错误:
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">select</span> object_id,column_id ,column_name <span class="hljs-keyword">from</span> siebeldbTableSchema <span class="hljs-keyword">where</span> table_name = <span class="hljs-string">'S_CONTACT'</span> <span class="hljs-keyword">and</span> column_id = <span class="hljs-number">11</span> <span class="hljs-keyword">and</span> object_id = <span class="hljs-number">1415428562</span> <span class="hljs-keyword">option</span>( <span class="hljs-keyword">table</span> hint (dbo.siebeldbTableSchema,index(idx_colstr_sts)))</span></code>
<code class=" hljs applescript">Msg <span class="hljs-number">8723</span>, Level <span class="hljs-number">16</span>, State <span class="hljs-number">1</span>, Line <span class="hljs-number">62</span> Cannot execute query. Object 'dbo.siebeldbTableSchema' <span class="hljs-keyword">is</span> specified <span class="hljs-keyword">in</span> <span class="hljs-keyword">the</span> TABLE HINT clause, <span class="hljs-keyword">but</span> <span class="hljs-keyword">is</span> <span class="hljs-keyword">not</span> used <span class="hljs-keyword">in</span> <span class="hljs-keyword">the</span> query <span class="hljs-keyword">or</span> <span class="hljs-keyword">does</span> <span class="hljs-keyword">not</span> match <span class="hljs-keyword">the</span> <span class="hljs-type">alias</span> specified <span class="hljs-keyword">in</span> <span class="hljs-keyword">the</span> query. Table references <span class="hljs-keyword">in</span> <span class="hljs-keyword">the</span> TABLE HINT clause must match <span class="hljs-keyword">the</span> WITH clause.</code>
2 Join hint: 指定采取join的方式
<code class=" hljs sql">Left|Right|Full{Loop|<span class="hljs-operator"><span class="hljs-keyword">merge</span>|hash} <span class="hljs-keyword">join</span>:
<span class="hljs-keyword">select</span> top <span class="hljs-number">500000</span> f.record_date, d.object_name, d.counter_name, d.instance_name , f.cntr_value <span class="hljs-keyword">from</span> dimstatisticscounters d
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">merge</span> <span class="hljs-keyword">join</span> fctstatisticscollection f <span class="hljs-keyword">on</span> f.row_id = d.row_id</span></code>
3。Table hint :针对单张表作hint ,一般是指定某个具体的索引
<code class=" hljs oxygene"><span class="hljs-keyword">With</span>(<span class="hljs-keyword">index</span>(index_name)): <span class="hljs-keyword">select</span> object_id,column_id ,column_name <span class="hljs-keyword">from</span> siebeldbTableSchema <span class="hljs-keyword">with</span>(<span class="hljs-keyword">index</span>(idx_obj_col_id)) <span class="hljs-keyword">where</span> column_id = <span class="hljs-number">11</span> <span class="hljs-keyword">and</span> object_id = <span class="hljs-number">1415428562</span></code>
这三种索引地写法除了第一种是独立于SQL之外的,其他都是要嵌入到SQL内部的,写法比较复杂。
每种hint的写法都会有自己适用的场合, 比如想要单个join实现某一特定join type,我们只要用join hint就可以了,但是如果全局的join都要使用一种或者两种join type,那么用 join hint就比较麻烦了,用Query hint就比较方便:
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">select</span> top <span class="hljs-number">500000</span> f.record_date, d.object_name, d.counter_name, d.instance_name , f.cntr_value <span class="hljs-keyword">from</span> dimstatisticscounters d <span class="hljs-keyword">inner</span> <span class="hljs-keyword">merge</span> <span class="hljs-keyword">join</span> fctstatisticscollection f <span class="hljs-keyword">on</span> f.row_id = d.row_id <span class="hljs-keyword">inner</span> <span class="hljs-keyword">merge</span> <span class="hljs-keyword">join</span> fctdbsize dbs <span class="hljs-keyword">on</span> dbs.record_date = f.record_date</span></code>
这里每个join都用了join hint,不方便的地方就是有多少join就要写多少merge join,所以不方便。但是我们要换了query join,就简单了:
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">select</span> top <span class="hljs-number">500000</span> f.record_date, d.object_name, d.counter_name, d.instance_name , f.cntr_value <span class="hljs-keyword">from</span> dimstatisticscounters d <span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span> fctstatisticscollection f <span class="hljs-keyword">on</span> f.row_id = d.row_id <span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span> fctdbsize dbs <span class="hljs-keyword">on</span> dbs.record_date = f.record_date <span class="hljs-keyword">option</span>(<span class="hljs-keyword">merge</span> <span class="hljs-keyword">join</span>)</span></code>
还可以指定使用三种join方式的其中两种,具体哪一种由优化器判断:
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">select</span> top <span class="hljs-number">500000</span> f.record_date, d.object_name, d.counter_name, d.instance_name , f.cntr_value <span class="hljs-keyword">from</span> dimstatisticscounters d <span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span> fctstatisticscollection f <span class="hljs-keyword">on</span> f.row_id = d.row_id <span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span> fctdbsize dbs <span class="hljs-keyword">on</span> dbs.record_date = f.record_date <span class="hljs-keyword">option</span>(<span class="hljs-keyword">merge</span> <span class="hljs-keyword">join</span>, hash <span class="hljs-keyword">join</span>)</span></code>
当然,得在适合的场合用join,比如merge join, hash join就得用在相等的Join条件下:
<code class=" hljs avrasm">select top <span class="hljs-number">500000</span> f<span class="hljs-preprocessor">.record</span>_date, d<span class="hljs-preprocessor">.object</span>_name, d<span class="hljs-preprocessor">.counter</span>_name, d<span class="hljs-preprocessor">.instance</span>_name , f<span class="hljs-preprocessor">.cntr</span>_value from dimstatisticscounters d inner merge join fctstatisticscollection f on f<span class="hljs-preprocessor">.row</span>_id > d<span class="hljs-preprocessor">.row</span>_id</code>
<code class=" hljs livecodeserver">Msg <span class="hljs-number">8622</span>, Level <span class="hljs-number">16</span>, State <span class="hljs-number">1</span>, Line <span class="hljs-number">5</span> Query processor could <span class="hljs-operator">not</span> produce <span class="hljs-operator">a</span> query plan because <span class="hljs-operator">of</span> <span class="hljs-operator">the</span> hints defined <span class="hljs-operator">in</span> this query. Resubmit <span class="hljs-operator">the</span> query <span class="hljs-keyword">without</span> specifying <span class="hljs-keyword">any</span> hints <span class="hljs-operator">and</span> <span class="hljs-keyword">without</span> <span class="hljs-keyword">using</span> SET FORCEPLAN.</code>
这里的join条件是f.row_Id>d.row_id,所以不是merge join, hash join适用的场景,query optimizer保证不会产生无效的计划。
Force Order :option(Force Order)
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">select</span> top <span class="hljs-number">10</span> d.*,sc.*,db.*
<span class="hljs-keyword">from</span> dbo.dimstatisticscounters d
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span> dbo.fctstatisticscollection sc
<span class="hljs-keyword">on</span> d.row_id = sc.row_id
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span> dbo.fctdbsize db
<span class="hljs-keyword">on</span> db.record_date = sc.record_date
<span class="hljs-keyword">option</span>(Force <span class="hljs-keyword">Order</span>)
<span class="hljs-keyword">select</span> top <span class="hljs-number">10</span> d.*,sc.*,db.*
<span class="hljs-keyword">from</span> dbo.dimstatisticscounters d
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span> dbo.fctstatisticscollection sc
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span> dbo.fctdbsize db
<span class="hljs-keyword">on</span> db.record_date = sc.record_date
<span class="hljs-keyword">on</span> d.row_id = sc.row_id
<span class="hljs-keyword">option</span>(Force <span class="hljs-keyword">Order</span>)</span></code>
先看没有option(Force Order)的处理 :
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">select</span> top <span class="hljs-number">10</span> d.*,sc.*,db.*
<span class="hljs-keyword">from</span> dbo.dimstatisticscounters d
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span> dbo.fctstatisticscollection sc
<span class="hljs-keyword">on</span> d.row_id = sc.row_id
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span> dbo.fctdbsize db
<span class="hljs-keyword">on</span> db.record_date = sc.record_date</span></code>

执行计划并没有按照从上到下的join order来产生执行计划。而是第二和第三个表先做了join. 最后才和第一个表作join.
比较下option(Force Order)的执行计划:
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">select</span> top <span class="hljs-number">10</span> d.*,sc.*,db.*
<span class="hljs-keyword">from</span> dbo.dimstatisticscounters d
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span> dbo.fctstatisticscollection sc
<span class="hljs-keyword">on</span> d.row_id = sc.row_id
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span> dbo.fctdbsize db
<span class="hljs-keyword">on</span> db.record_date = sc.record_date
<span class="hljs-keyword">option</span>(Force <span class="hljs-keyword">Order</span>)</span></code>

从上到下,依次join,速度上也快了很多。
有意思的是,这里有这么个写法 :
<code class=" hljs mathematica">SELECT A.*,B.*,<span class="hljs-keyword">C</span>。* FROM xxx A <span class="hljs-keyword">Join</span> xxx B <span class="hljs-keyword">Join</span> xxx <span class="hljs-keyword">C</span> on B.xx = <span class="hljs-keyword">C</span>.xx <span class="hljs-keyword">On</span> A.xxx = B.xxx</code>
Join原来是可以嵌套写的。 嵌套的Join,两表的on必须紧挨着写,再写外层的Join On条件。所以下面的写法是错的:
<code class=" hljs mathematica">SELECT A.*,B.*,<span class="hljs-keyword">C</span>。*
FROM xxx A
<span class="hljs-keyword">Join</span> xxx B
<span class="hljs-keyword">Join</span> xxx <span class="hljs-keyword">C</span>
on A.xx = <span class="hljs-keyword">C</span>.xx
<span class="hljs-keyword">On</span> <span class="hljs-keyword">C</span>.xxx = B.xxx</code>
Force Order 对aggregation的影响:
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">select</span> d.row_id, <span class="hljs-aggregate">count</span>(f.record_date) <span class="hljs-keyword">as</span> instances <span class="hljs-keyword">from</span> dbo.dimstatisticscounters d <span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span> dbo.fctstatisticscollection f <span class="hljs-keyword">on</span> d.row_id = f.row_id <span class="hljs-keyword">group</span> <span class="hljs-keyword">by</span> d.row_id</span></code>

先join之前做了aggregation。
<code class=" hljs sql"><span class="hljs-operator"><span class="hljs-keyword">select</span> d.row_id, <span class="hljs-aggregate">count</span>(f.record_date) <span class="hljs-keyword">as</span> instances <span class="hljs-keyword">from</span> dbo.dimstatisticscounters d <span class="hljs-keyword">inner</span> <span class="hljs-keyword"></span></span></code>

 SQL Server使用CROSS APPLY与OUTER APPLY实现连接查询Aug 26, 2022 pm 02:07 PM
SQL Server使用CROSS APPLY与OUTER APPLY实现连接查询Aug 26, 2022 pm 02:07 PM本篇文章给大家带来了关于SQL的相关知识,其中主要介绍了SQL Server使用CROSS APPLY与OUTER APPLY实现连接查询的方法,文中通过示例代码介绍的非常详细,下面一起来看一下,希望对大家有帮助。
 SQL Server解析/操作Json格式字段数据的方法实例Aug 29, 2022 pm 12:00 PM
SQL Server解析/操作Json格式字段数据的方法实例Aug 29, 2022 pm 12:00 PM本篇文章给大家带来了关于SQL server的相关知识,其中主要介绍了SQL SERVER没有自带的解析json函数,需要自建一个函数(表值函数),下面介绍关于SQL Server解析/操作Json格式字段数据的相关资料,希望对大家有帮助。
 聊聊优化sql中order By语句的方法Sep 27, 2022 pm 01:45 PM
聊聊优化sql中order By语句的方法Sep 27, 2022 pm 01:45 PM如何优化sql中的orderBy语句?下面本篇文章给大家介绍一下优化sql中orderBy语句的方法,具有很好的参考价值,希望对大家有所帮助。
 一文搞懂SQL中的开窗函数Sep 02, 2022 pm 04:55 PM
一文搞懂SQL中的开窗函数Sep 02, 2022 pm 04:55 PM本篇文章给大家带来了关于SQL server的相关知识,开窗函数也叫分析函数有两类,一类是聚合开窗函数,一类是排序开窗函数,下面这篇文章主要给大家介绍了关于SQL中开窗函数的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下。
 Monaco Editor如何实现SQL和Java代码提示?May 07, 2023 pm 10:13 PM
Monaco Editor如何实现SQL和Java代码提示?May 07, 2023 pm 10:13 PMmonacoeditor创建//创建和设置值if(!this.monacoEditor){this.monacoEditor=monaco.editor.create(this._node,{value:value||code,language:language,...options});this.monacoEditor.onDidChangeModelContent(e=>{constvalue=this.monacoEditor.getValue();//使value和其值保持一致i
 Monaco Editor怎么实现SQL和Java代码提示May 11, 2023 pm 05:31 PM
Monaco Editor怎么实现SQL和Java代码提示May 11, 2023 pm 05:31 PMmonacoeditor创建//创建和设置值if(!this.monacoEditor){this.monacoEditor=monaco.editor.create(this._node,{value:value||code,language:language,...options});this.monacoEditor.onDidChangeModelContent(e=>{constvalue=this.monacoEditor.getValue();//使value和其值保持一致i
 如何使用exp进行SQL报错注入May 12, 2023 am 10:16 AM
如何使用exp进行SQL报错注入May 12, 2023 am 10:16 AM0x01前言概述小编又在MySQL中发现了一个Double型数据溢出。当我们拿到MySQL里的函数时,小编比较感兴趣的是其中的数学函数,它们也应该包含一些数据类型来保存数值。所以小编就跑去测试看哪些函数会出现溢出错误。然后小编发现,当传递一个大于709的值时,函数exp()就会引起一个溢出错误。mysql>selectexp(709);+-----------------------+|exp(709)|+-----------------------+|8.218407461554972
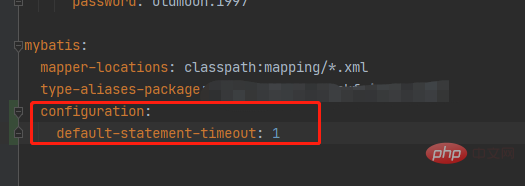 springboot配置mybatis的sql执行超时时间怎么解决May 15, 2023 pm 06:10 PM
springboot配置mybatis的sql执行超时时间怎么解决May 15, 2023 pm 06:10 PM当某些sql因为不知名原因堵塞时,为了不影响后台服务运行,想要给sql增加执行时间限制,超时后就抛异常,保证后台线程不会因为sql堵塞而堵塞。一、yml全局配置单数据源可以,多数据源时会失效二、java配置类配置成功抛出超时异常。importcom.alibaba.druid.pool.DruidDataSource;importcom.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceBuilder;importorg.apache.


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

ZendStudio 13.5.1 Mac
強大的PHP整合開發環境

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

SublimeText3漢化版
中文版,非常好用

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

