
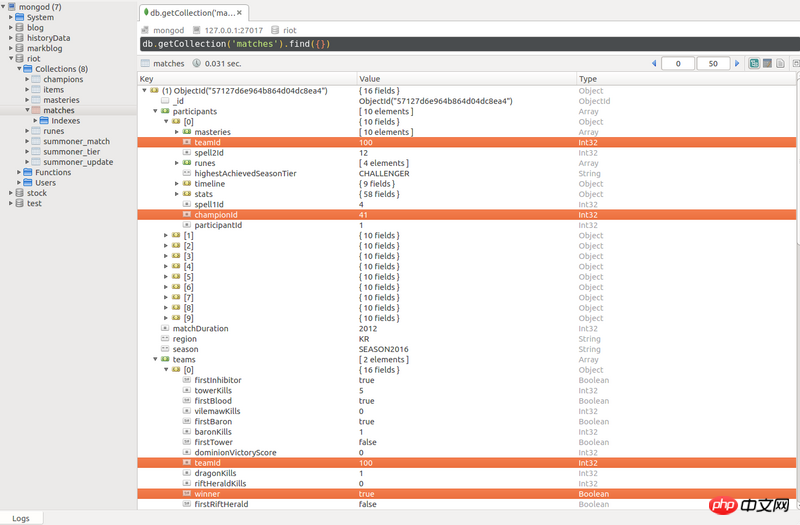
图为mongodb中一条document结构,记录的是LOL的一场比赛对局详情
participants中有10个玩家,前5个teamID为100,后5个teamId为200.比赛的结果哪个队伍取胜是记录在teams那个子文档中的。
我现在的想要查询championId为64(盲僧), 157(亚索)这两个英雄在同一个队伍时的胜利场次,(规定游戏版本号>6.7),查询语句我是这样写的:
db.getCollection('matches').count({
$and: [
{ "matchVersion": {$gte:"6.7"} }
, {
$or:
[
{
$and:
[
{ "participants": {$elemMatch: {"teamId": 100, "championId": 64 } } }
, { "participants": {$elemMatch: {"teamId": 100, "championId": 157 } } }
, { "teams":{ $elemMatch: {"teamId": 100, "winner":true} } }
]
},
{
$and:
[
{ "participants": {$elemMatch: {"teamId": 200, "championId": 64 } } }
, { "participants": {$elemMatch: {"teamId": 200, "championId": 157 } } }
, { "teams":{ $elemMatch: {"teamId": 200, "winner":true} } }
]
}
]
}
]
}
)数据规模为14万,可是执行这样一个查询要花费3秒。已经对对应的查询建立了索引。对查询explain的结果如下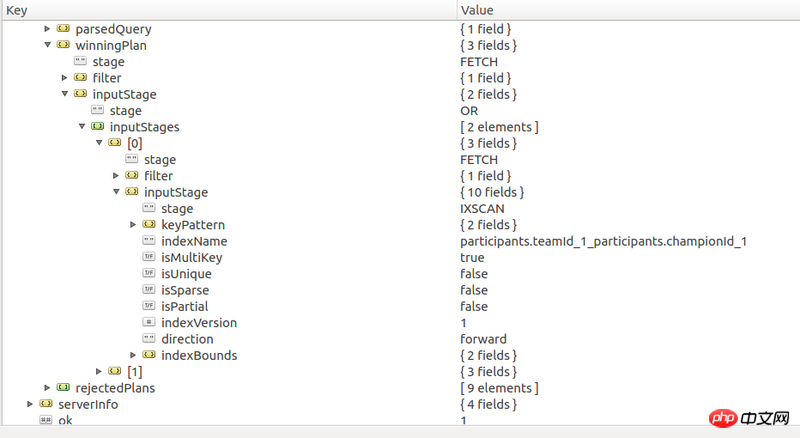
不过好像有些索引也没有用到,比如teams.teamId, teams.winner的复合索引,matchVersion的索引
请问这个查询该如何优化呢?我觉得这个数据规模花费这么久时间应该是我的使用姿势不对吧?
淡淡烟草味2017-05-02 09:20:33
Your execution plan index is used, but it can be seen that it is not efficient, but a lot of key information is folded and the details cannot be seen. Next time it is best to send the original JSON directly as it will be easier to understand. Similarly, if you have a data sample, it is best to send it in JSON, so that others can have a copy of the test data when solving the problem, which will be much more convenient. $andThis thing does not need to appear most of the time. Two parallel elements in an object are the relationship between and. This simplifies your query structure and makes it easier for others to look at. So your query has been simplified as follows:
db.getCollection('matches').count({
"matchVersion": {$gte: "6.7"},
$or: [{
"participants": {$elemMatch: {"teamId": 100, "championId": 64}},
"participants": {$elemMatch: {"teamId": 100, "championId": 157}},
"teams": {$elemMatch: {"teamId": 100, "winner": true}}
}, {
"participants": {$elemMatch: {"teamId": 200, "championId": 64}},
"participants": {$elemMatch: {"teamId": 200, "championId": 157}},
"teams": {$elemMatch: {"teamId": 200,"winner": true}}
}]
})The last and most critical index issue is that it is speculated that the index that is more useful to you should be the joint index of participants.teamId+participants.championId+teams.teamId+teams.winner+matchVersion. Conditions with better filterability should be placed first according to the filterability of the conditions. Even remove some conditions to improve writing efficiency. But it depends on your data distribution.
Why is your index not being used? Although mongodb 2.6 and later supports cross-indexing and multiple indexes can be used to satisfy the same query, the current execution plan evaluation system makes it difficult to trigger the cross-index. So try to use an index to satisfy your query.