
处理的是一个.js文件,中间包含大量insert命令和update命令。一个命令占一行。
文件大小为222M.
错误信息如下: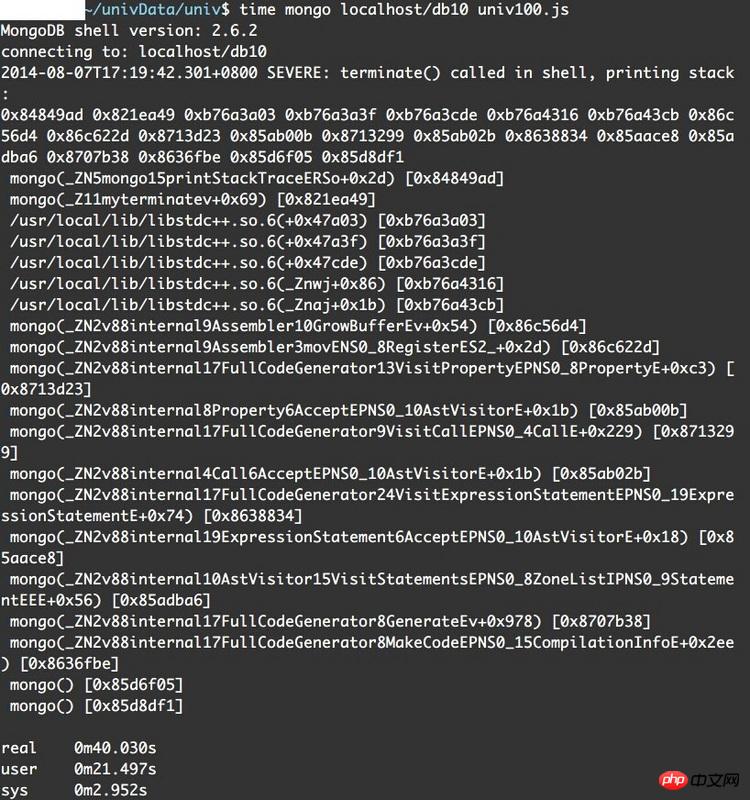
我猜测可能是因为单条命令太长的缘故,但是用mongo直接处理.js文件按理说不会有这样的问题才对吧
系统是debian 32位,版本2.6.32-5-386
在stackoverflow和segmentfault找,也只看到有人遇到堆栈信息中是_ZN5开头的。
在64位mongodb上运行成功了。
但是64位加载2.3G文件的时候又有错误,好在这次有明确信息了。
拆成200多M的文件就能处理了。
很奇怪,我在mongodb文档中没看到说有这种限制啊
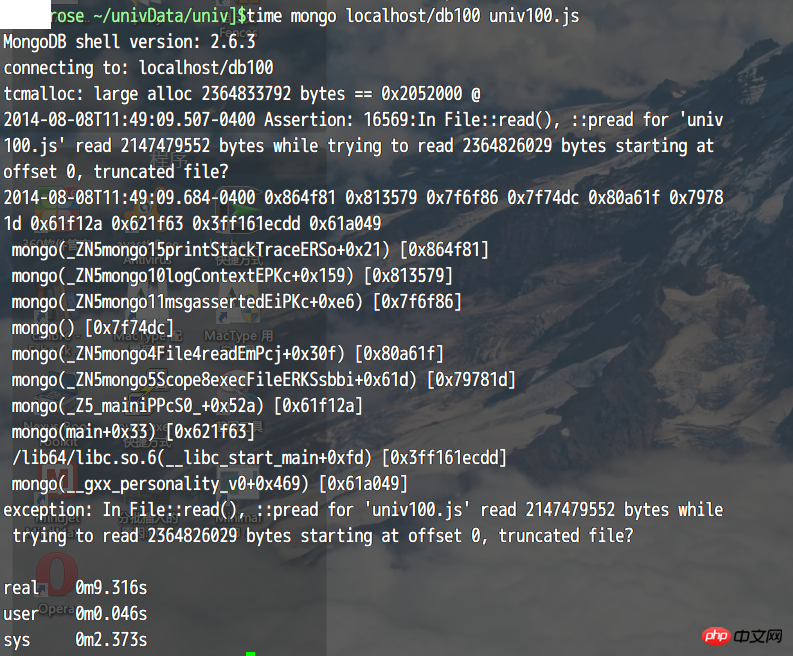
connecting to: localhost/test
tcmalloc: large alloc 2364833792 bytes == 0x2658000 @
2014-08-19T21:49:28.069-0400 Assertion: 16569:In File::read(), ::pread for 'univ100-100.js' read 2147479552 bytes while trying to read 2364826029 bytes starting at offset 0, truncated file?
2014-08-19T21:49:28.164-0400 0x864f81 0x813579 0x7f6f86 0x7f74dc 0x80a61f 0x79781d 0x61f12a 0x621f63 0x3ff161ecdd 0x61a049
mongo(_ZN5mongo15printStackTraceERSo+0x21) [0x864f81]
mongo(_ZN5mongo10logContextEPKc+0x159) [0x813579]
mongo(_ZN5mongo11msgassertedEiPKc+0xe6) [0x7f6f86]
mongo() [0x7f74dc]
mongo(_ZN5mongo4File4readEmPcj+0x30f) [0x80a61f]
mongo(_ZN5mongo5Scope8execFileERKSsbbi+0x61d) [0x79781d]
mongo(_Z5_mainiPPcS0_+0x52a) [0x61f12a]
mongo(main+0x33) [0x621f63]
/lib64/libc.so.6(__libc_start_main+0xfd) [0x3ff161ecdd]
mongo(__gxx_personality_v0+0x469) [0x61a049]
exception: In File::read(), ::pread for 'univ100-100.js' read 2147479552 bytes while trying to read 2364826029 bytes starting at offset 0, truncated file?
real 0m7.922s
user 0m0.045s
sys 0m2.477s

高洛峰2017-04-24 09:12:13
Thank you very much for your report.
First of all, the stack trace is mangleed by gcc and can be seen in reverse using demangler.
Assuming that your server is 2.6.3 like the shell, the problem lies directly here. The shell will read the entire script file into memory and then compile it. It can be explained that there is a problem with the 2.3G file on a 32-bit machine. But it should not cause problems on 64-bit machines.
There are two questions here.
1. JS file size should be limited to 2G to be compatible with 32-bit operating systems. The current logic is correct, but the upper limit is too large and does not match the description.
2. When reading a file, the system cannot always guarantee that it will be read in one pread call, so it is best to read multiple times in file.cpp until it ends or an error occurs.
Hope I made the problem clear. A temporary solution is to do what you did and break the file into smaller pieces. It would be great if you could submit this issue in Jira, simply describing the problem you are encountering in English. Kernel engineers will improve it in future development, and you can also track this issue on Jira. If it's inconvenient for you, I can submit it for you.
A better way is to fork the MongoDB code on Github after submitting the report on Jira, modify it and then submit a Pull Request. The Kernel engineer will code reivew it and finally merge it into the code base. Because this problem is relatively rare, relatively independent, and relatively clear, it is very suitable to submit a Pull Request after completing a small task. Then MongoDB users all over the world are running the code you wrote. I think since there are so many MongoDB users in China, we have the ability to contribute to the MongoDB community. If you have any more questions, just tell me.
P.S. I'm curious why you need a 2.3G script, if you can tell me what you are trying to do, there may be a more elegant solution.
