
爬取了一个用户的论坛数据,但是这个数据库中有重复的数据,于是我想把重复的数据项给去掉。数据库的结构如下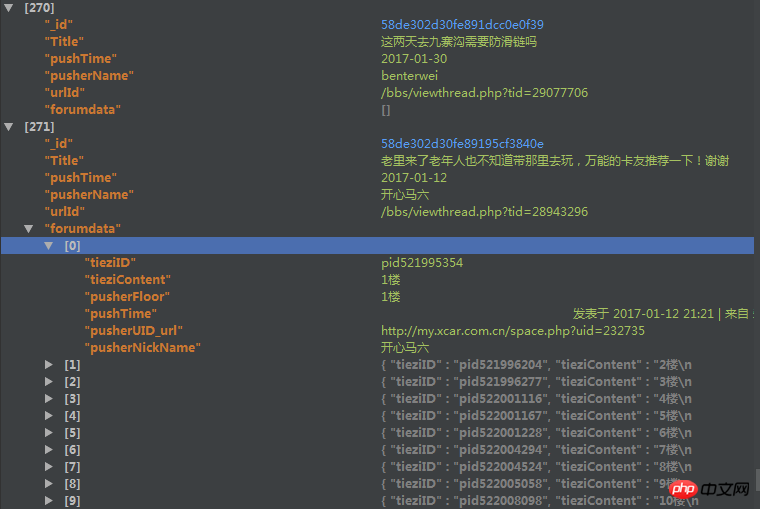
里边的forundata是这个帖子的每个楼层的发言情况。
但是因为帖子爬取的时候有可能重复爬取了,我现在想根据里边的urlId来去掉重复的帖子,但是在去除的时候我想保留帖子的forumdata(是list类型)字段中列表长度最长的那个。
用mongodb的distinct方法只能返回重复了的帖子urlId,都不返回重复帖子的其他信息,我没法定位。。。假如重复50000个,那么我还要根据这些返回的urlId去数据库中find之后再在mongodb外边代码修改吗?可是即使这样,我发现运行的时候速度特别慢。
之后我用了group函数,但是在reduce函数中,因为我要比较forumdata函数的大小,然后决定保留哪一个forumdata,所以我要传入forumdata,但是有些forumdata大小超过了16M,导致报错,然后这样有什么解决办法吗?
或者用第三种方法,用Map_reduce,但是我在map-reduce中的reduce传入的forumdata大小限制竟然是8M,还是报错。。。
代码如下
group的代码:
reducefunc=Code(
'function(doc,prev){'
'if (prev==null){'
'prev=doc'
'}'
'if(prev!=null){'
'if (doc.forumdata.lenth>prev.forumdata.lenth){'
'prev=doc'
'}'
'}'
'}'
)
map_reduce的代码:
reducefunc=Code(
'function(urlId,forumdata){'
'if(forumdata.lenth=1){'
'return forumdata[0];'
'}'
'else if(forumdata[0].lenth>forumdata[1].lenth){'
'return forumdata[0];'
'}'
'else{'
'return forumdata[1]}'
'}'
)
mapfunc=Code(
'function(){'
'emit(this.urlId,this.forumdata)'
'}'
)望各位高手帮我看看这个问题该怎么解决,三个方案中随便各一个就好,或者重新帮我分析一个思路,感激不尽。
鄙人新人,问题有描述不到位的地方请提出来,我会立即补充完善。

黄舟2017-04-18 10:34:12
If this problem has not been solved yet, you may wish to refer to the following ideas:
1. Aggregation is recommended in MongoDB, but map-reduce is not recommended;
2. Among your requirements, a very important point is to obtain the length of Forumdata: the length of the array, so as to find the document with the longest array length. Your original article said that Forumdata is a list (it should be an array in MongoDB); MongoDB provides the $size operator to obtain the size of the array.
Please refer to the chestnuts below:
> db.data.aggregate([ {$project : { "_id" : 1, "name" : 1, "num" : 1, "length" : { $size : "$num"}}}])
{ "_id" : ObjectId("58e631a5f21e5d618900ec20"), "name" : "a", "num" : [ 12, 123, 22, 34, 1 ], "length" : 5 }
{ "_id" : ObjectId("58e631a5f21e5d618900ec21"), "name" : "b", "num" : [ 42, 22 ], "length" : 2 }
{ "_id" : ObjectId("58e631a7f21e5d618900ec22"), "name" : "c", "num" : [ 49 ], "length" : 1 }3. After having the above data, you can then use $sort, $group, etc. in aggregation to find the objectId of the Document that meets your needs. For specific methods, please refer to the following post:
https://segmentfault.com/q/10...
4. Finally delete related ObjectIds in batch
Similar to:
var dupls = [] Save the objectId to be deleted
db.collectionName.remove({_id:{$in:dupls}})
For reference.
Love MongoDB! Have Fun!
Poke me<--Please poke me on the left, it’s April! Registration for the MongoDB Chinese Community Shenzhen User Conference has begun! Gathering of great gods!

迷茫2017-04-18 10:34:12
If the amount of data is not very large, you can consider crawling it again and query it every time you save it. Only the set of data with the most data will be saved.
Excellent crawler strategy>>Excellent data cleaning strategy

PHPz2017-04-18 10:34:12
Thank you netizens. In the qq group, someone gave an idea. In the map, the forumdata is processed with urlId first, and urlId and forumdatad.length are returned. Then it is processed in reduce, and the one with the largest forumdata.length is retained. and the corresponding urlId, and finally save it into a database, and then read all the data from the original database through the urlId in this database. I tried it. Although the efficiency is not what I expected, the speed is still much faster than using python before.
Attached are the codes for map and reduce:
'''javaScript
mapfunc=Code(
'function(){'
'data=new Array();'
'data={lenth:this.forumdata.length,'
'id:this._id};'
# 'data=this._id;'
'emit({"id":this.urlId},data);'
'}'
)
reducefunc=Code(
'function(tieziID,dataset){'
'reduceid=null;'
'reducelenth=0;'
''
''
'redecenum1=0;'
'redecenum2=0;'
''
'dataset.forEach(function(val){'
'if(reducelenth<=val["lenth"]){'
'reducelenth=val["lenth"];'
'reduceid=val["id"];'
'redecenum1+=1;'
'}'
'redecenum2+=1;'
'});'
'return {"lenth":reducelenth,"id":reduceid};'
'}'
)上边是先导出一个新的数据库的代码,下边是处理这个数据库的代码:
mapfunc=Code(
'function(){'
# 'data=new Array();'
'lenth=this.forumdata.length;'
''
'emit(this.urlId,lenth);'
'}')
reducefunc=Code(
'function(key,value){'
'return value;'
'}')
之后添加到相应的map_reduce中就行了。
感觉Bgou回答的不错,所以就选他的答案了,还没有去实践。上边是我的做法,就当以后给遇到同样问题的人有一个参考。
