
一、问题描述
用Jsoup抓取36氪网站的这部分数据(下图),也就是<p id="app">里面的数据,总是返回null。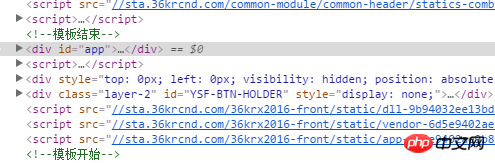
二、我的尝试
1、用id查找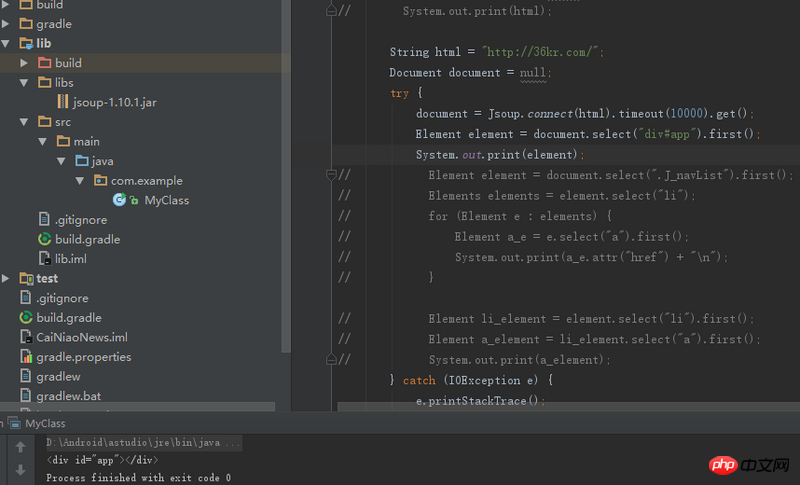
2、用其中的一个类查找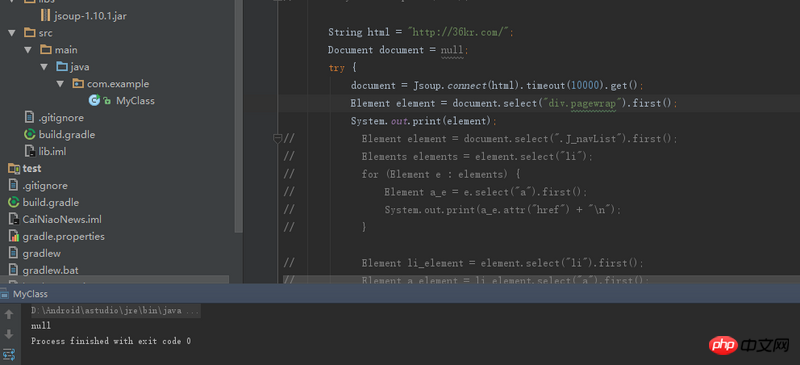
3、打印整个document,结果如下图,好像这是一个空标签。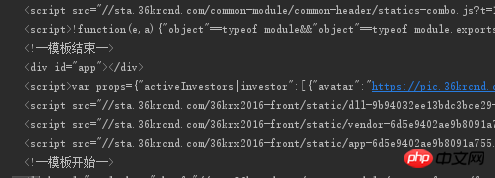
三、我的思考
当我点击<p id="app">这行代码时(谷歌的“检查”),发现右边的小窗口styles里面有句p{display:block;}。然后我在网站上找到类似的(下图:class="top_swing"),发现获取到的element也是空的。经过查阅,display:block代表元素以块状显示。所以我猜想是不是块状元素要用另外的方法获取,还是其它原因??用Jsoup怎么解决??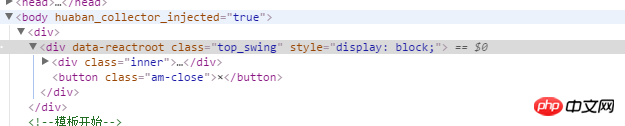

怪我咯2017-04-18 10:25:55
Those contents are dynamically generated by Javascript. Do not look at the Google Developer Tools, but right-click on the web page and view the source code.
can be seen
<p id="app"></p>If you use Jsoup or the like, you can only crawl html content, but content generated by js cannot be crawled.

