
用charles对一览(https://www.yilan.io/home/?ca...)进行抓包,该页面是懒加载形式,每一次加载会生成一个recommended(登录情况下文件名变化但是原理相同),这个文件里面有json可以取得想要的数据。
但是post的地址(见图片顶部)如果直接复制访问会报404,不知道该如何获得可以获取数据的真实地址,并进行若干个recommended的批量抓取呢?
谢谢!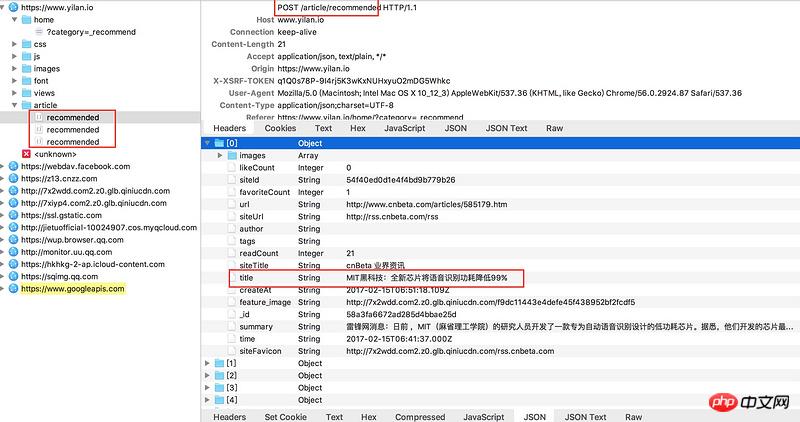
巴扎黑2017-04-18 10:24:53
Let me talk about my method, I have crawled the data. I use firebug. After opening it, I found the following path: https://www.yilan.io/article/recommended
After looking at the content to be posted, I need this set of data {"skip":0,"limit":20}. Start writing code below:
import urllib2
import urllib
import gzip
from StringIO import StringIO
import json
api = 'https://www.yilan.io/article/recommended'
data = {"skip":0,"limit":20}
headers = { 'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh',
'Connection': 'keep-alive',
'Cookie': 'XSRF-TOKEN=APc3KgEq-6wavGArI6rLf6tPW69j7H_Qm2s0; user=%7B%22_id%22%3A%22%22%2C%22role%22%3A%7B%22title%22%3A%22anon%22%2C%22bitMask%22%3A1610612736%7D%7D; Metrix-sid=s%3AjDAFvFGo3C0BJzR7cTXBXHl6VM493Gp0.C1svjUqfnY3NhUluURMDdaL3HEpUX8rpSj9%2F9yhKnEI',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:51.0) Gecko/20100101 Firefox/51.0',
'X-XSRF-TOKEN': 'APc3KgEq-6wavGArI6rLf6tPW69j7H_Qm2s0'
}
url_data = urllib.urlencode(data)
request = urllib2.Request(api, data=url_data,headers=headers)
content = urllib2.urlopen(request).read()
contents = StringIO(content)
f = gzip.GzipFile(mode='rb', fileobj=contents).read()
b = json.loads(f)
print bThe running results are as follows:
[{u'readCount': 12, u'siteTitle': u'\u5de5\u5177\u7656', u'siteUrl': u'http://jianshu.milkythinking.com/feeds/collections/2mvgxp', u'siteFavicon': u'http://7xiyp4.com2.z0.glb.qiniucdn.com/site-5627773e8b3ac7e104c6280f-favicon', u'feature_image': u'http://7x2wdd.com2.z0.glb.qiniucdn.com/54e7178471ab07ea378e0d254a57b3cc', u'author': u'', u'url': ...]Then just extract the content you want. You can change the value of limit to change the amount of content you want to get at one time.
The website may check the data you posted in the background. If there is an error, it will result in 404, which is why it cannot be accessed by directly opening the path.

大家讲道理2017-04-18 10:24:53
Probably the HTTP HEADERS setting is improper. I can’t figure out how to set it up specifically. You can come up with a set of HEADERS that simulates a regular browser, or track the request in the browser.
