python - 如何爬取带有日期选择的ajax网站?
需要爬取三峡水库的实时水情数据,可以在网页中选择日期显示水情信息,如果一天天选择再复制数据发现很是耗时,我现在需要将下图中三峡水利枢纽2014年-2016年每天的数据爬下来。

网址如下:
http://www.ctgpc.com.cn/sxjt/...
通过浏览器自带的检查工具,右键检查元素,查看 network,查看调用的 ajax API 地址:初步分析后发现是通过ajax调用了以下网址,并用POST传递了一个日期数据,例如今天2017-02-15给该网址:
http://www.ctgpc.com.cn/eport...
Header如下:
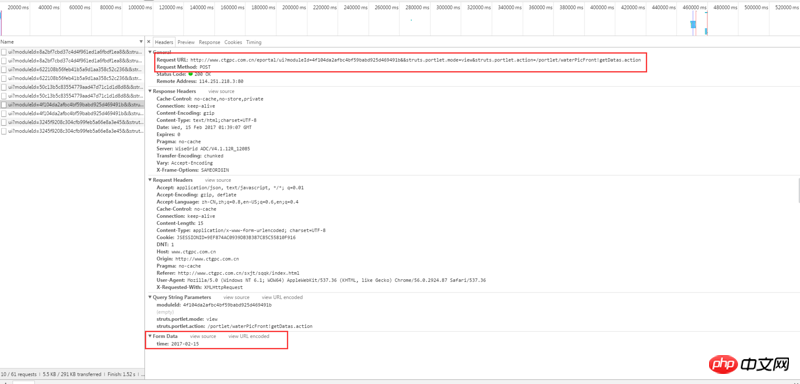
Response如下:

之前有搜索到类似的问题:https://segmentfault.com/q/10...
但是按照回答并没能解决我的疑惑,因此在这里求助各位前辈,麻烦大家了


