
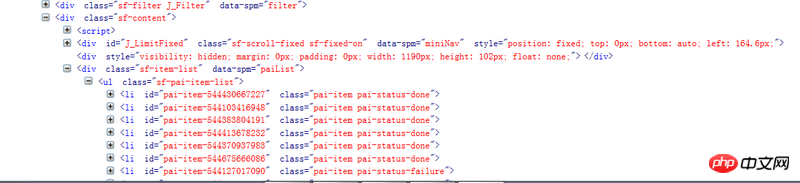
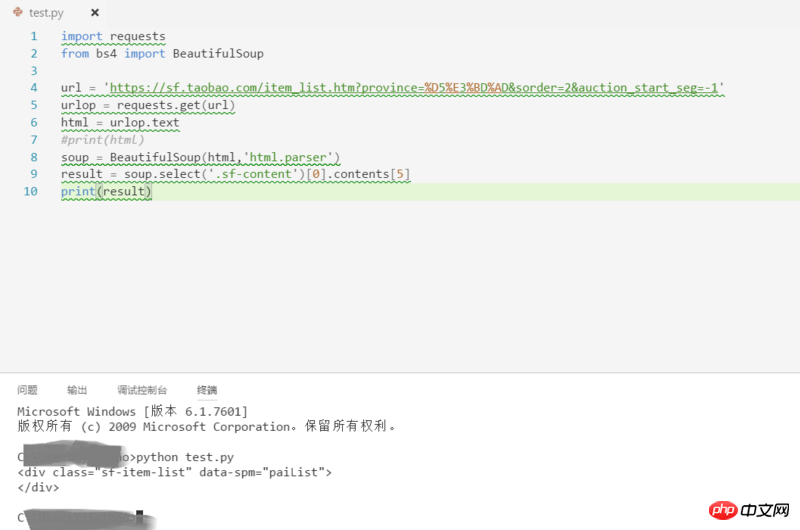
待解析页面的部分代码如第一幅图所示,我自己写的代码及运行结果如第二幅图所示。看到已经有答主提问解析页面丢失是因为用的是lxml的解析方式,我想说我一直用的是html.parser的方式。希望各位大神不吝赐教~


伊谢尔伦2017-04-18 10:20:51
Tips, if you use Chrome F12 to view it, there will be dynamically loaded content, and you cannot get this content by directly requesting the URL of the page. It is recommended that you right-click to view the source code of the web page and compare it with the content in F12. If there is no content in the source code, check other requests in the Network to see if there is any data you need.
