PHPz2017-04-18 10:06:56
I found that the spaces in each line are divided by two encodings, although they look the same. Simply rewritten your code
# coding: utf-8
import re
import requests
from bs4 import BeautifulSoup
code = '000917电广传媒'
def getinfo(code,page):
baseurl = 'http://news.baidu.com/ns?word=title%3A%28{}%29&pn={}&cl=2&ct=0&tn=newstitle&rn=20&ie=utf-8&bt=0&et=0'.format(code,10*(page-1))
wd = requests.get(baseurl).content
soup = BeautifulSoup(wd,'lxml')
title = soup.select('.c-title > a ')
resource = soup.select('p .c-title-author')
resource1 = [i.text.encode('utf-8') for i in resource]
for i in resource1:
l = re.split("\xa02016|\xc2\xa0\xc2\xa0", i)
print l[0]
print l[1]
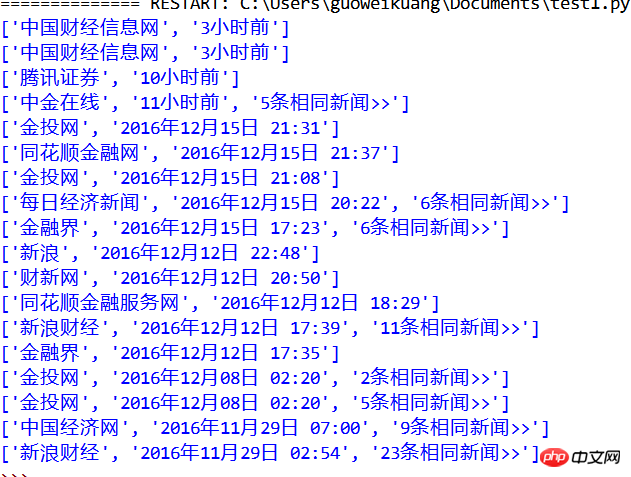
getinfo(code,1)The output result is
中金在线
1小时前
金投网
2016年12月15日 21:31
同花顺金融网
2016年12月15日 21:37
金投网
2016年12月15日 21:08
每日经济新闻
2016年12月15日 20:22
金融界
2016年12月15日 17:23
潇湘晨报数字报
2016年12月13日 03:00
新浪
2016年12月12日 22:48
财新网
2016年12月12日 20:50
同花顺金融服务网
2016年12月12日 18:29
新浪财经
2016年12月12日 17:39
金融界
2016年12月12日 17:35
金投网
2016年12月08日 02:20
金投网
2016年12月08日 02:20
中国经济网
2016年11月29日 07:00
新浪财经
2016年11月29日 02:54
潇湘晨报数字报
2016年11月28日 02:45
证券时报
2016年11月26日 02:48
同花顺金融服务网
2016年11月25日 22:37
同花顺金融网
2016年11月25日 19:48
PHP中文网2017-04-18 10:06:56
The timestamps in the data all start with a number, such as 59 minutes and 201 years. Why not try dividing by the first number.
巴扎黑2017-04-18 10:06:56
# coding=utf-8
import requests
from bs4 import BeautifulSoup
code = '000917电广传媒'
def getinfo(code,page):
baseurl = 'http://news.baidu.com/ns?word=title%3A%28{}%29&pn={}&cl=2&ct=0&tn=newstitle&rn=20&ie=utf-8&bt=0&et=0'.format(code,10*(page-1))
wd = requests.get(baseurl).content
soup = BeautifulSoup(wd,'lxml')
for text in soup.find_all('p', class_='result title', id=True):
for i in text.find_all('p', class_='c-title-author'):
print(i.get_text().split('\xa0\xa0'))
getinfo(code,1)
It can be divided in python3 environment,