
豆瓣top250电影的链接
<p class="info">
<p class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
</p>
<p class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins<br>
1994 / 美国 / 犯罪 剧情
</p>
</p>网页的dom一般都是以这样的形式排列的,想请教两点:
以电影名来说,有两个标签的class都是title,我这种原始方法会匹配两个title,有什么方法可以只匹配第一个中文title呢?
titles = soup.find_all(name='span', attrs={'class': 'title'})导演和主演栏目<p>标签的class为空,请问beautifulsoup中有什么方法可以匹配到这个标签内的内容呢?
下面这种实现并不行,因为豆瓣一个页面的话有25个电影,有40多个这样的title标签,没有50个的原因是国产电影没有英文名只有一个title
titles = soup.find_all(name='span', attrs={'class': 'title'})[0].text如果它有50个标签还好,我可以通过列表推倒式来排除偶数的title的标签,但是国产电影没有英文名,它只会有一个title标签,所以这种实现并不完美。
[title for index, title in enumerate(titles) if index % 2 == 0]
巴扎黑2017-04-18 09:56:21
See if this works too
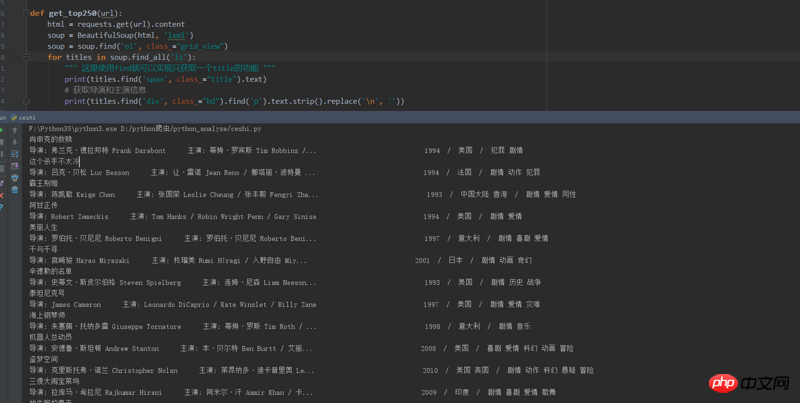
def get_top250(url):
html = requests.get(url).content
soup = BeautifulSoup(html, 'lxml')
soup = soup.find('ol', class_="grid_view")
for titles in soup.find_all('li'):
""" 这里使用find就可以实现只获取一个title的功能 """
print(titles.find('span', class_="title").text)
# 获取导演和主演信息
print(titles.find('p', class_="bd").find('p').text.strip().replace('\n', ''))

PHP中文网2017-04-18 09:56:21
1: Just subscript to get the value
titles = soup.find_all(name='span', attrs={'class': 'title'})[0].textIf there is no other p in <p class="bd">, just look for p directly in p:
content = soup.find('p',attrs={'class':'bd'}).find('p').textRe-answer:
import requests
from bs4 import BeautifulSoup as BS
soup = BS(requests.get('https://movie.douban.com/top250').text)
ol = soup.find('ol', attrs={"class":'grid_view'}) # 找到包含电影的ol
lis = ol.find_all('li') # 找到所有的电影li
for movie in lis:
###
# 处理每个电影,就跟上面一样了
###
