import re
text = 'thenextnothingis123456'
print(re.search(r'(\d*)', text).group(0))
为什么这段代码不能匹配出数字?如果将d替换成w反倒可以匹配出所有字符?

高洛峰2017-04-18 09:55:18
Because the meaning of * in r'(d*)' is to match 0 or more, it can not match any characters. Use re.search to start matching from the beginning of the string. Because the first character of 'thenextnothingis123456' is not a number, it cannot be matched, but r'(d*)' can not match any characters, so an empty string is returned.
And r'(d+)' requires matching 1 to multiple numbers. When used to match 'thenextnothingis123456', it is found that the first character is not a letter, and it will continue to try the second character until character 1 starts with numbers. So "123456" is matched. You can understand it by looking at the output below.
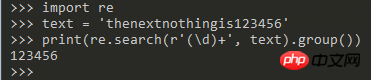
>>> import re
>>> text = 'thenextnothingis123456'
>>> p = re.search(r'(\d*)', text)
>>> p.start()
0
>>> p.end()
0
>>> p.groups()
('',)
>>> p = re.search(r'(\d+)', text)
>>> p.start()
16
>>> p.end()
22
>>> p.groups()
('123456',)

怪我咯2017-04-18 09:55:18
Why can’t this code match numbers?
I feel that it has actually been matched, which is the number of 0 times: Your .group(0) did not report a nonetype error, indicating that the match was successful


阿神2017-04-18 09:55:18
>>> print(re.search(r'(\d*)', "abcd1234").group(0)) ########11111111
>>> print(re.search(r'(\d*)', "1234abcd").group(0))
1234
>>> print(re.search(r'[a-z]*(\d*)', "abcd1234").group(1))
1234
>>> print(re.search(r'(\d{0})', "abcd1234").group(0)) #######2222222
>>> print(re.search(r'(\d+)', "abcd1234xxx4321").group(0))
1234
>>> print(re.search(r'(\d+)', "abcd1234xxx4321").group(1)) ####可见re.search第一次匹配成功后就不再接着匹配
1234
>>> print(re.search(r'(\d+)', "abcd1234xxx4321").group(2))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group


天蓬老师2017-04-18 09:55:18
>>> import re
>>> text = 'thenextnothingis123456'
>>> print(re.search(r'(\d+)', text).group(0))
123456
>>>
可以用(\d+)规则匹配~
同问为什么r'(\d*)无法匹配出字符串"123456"?