
能不能实现这种:
aItem的数据由aPipeline处理
bItem的数据由bPipeline处理

天蓬老师2017-04-18 09:51:55
Is this the purpose?
For example, your items.py has the following items
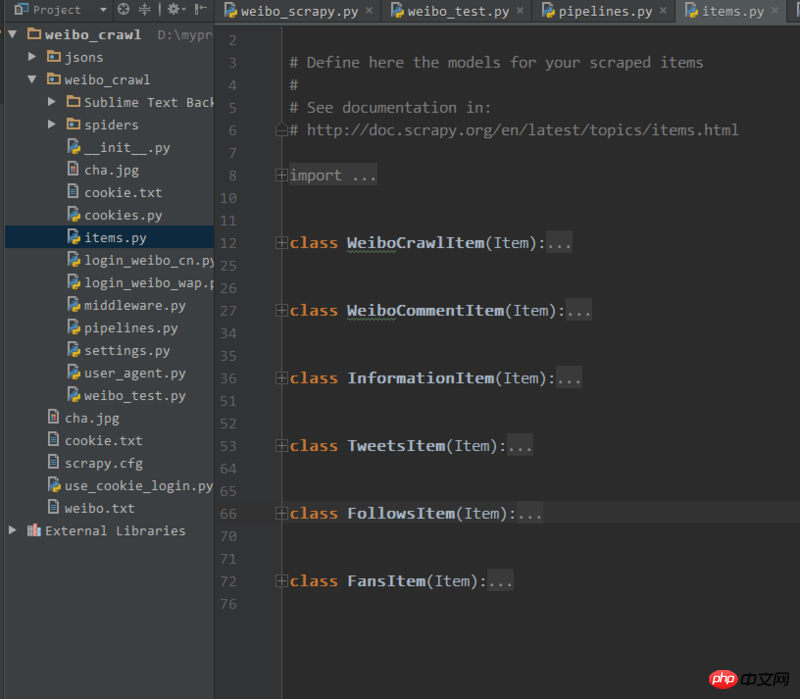
Then you can do the following in the process_item function in pipelines.py
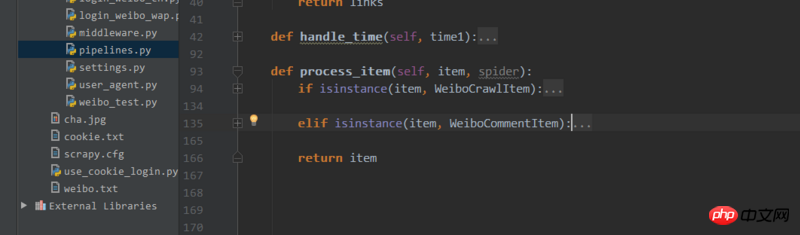
This way different data can be processed separately,
天蓬老师2017-04-18 09:51:55
You can determine which crawler the result is in the pipeline:
def process_item(self, item, spider):
if spider.name == 'news':
#这里写存入 News 表的逻辑
news = News()
...(省略部分代码)
self.session.add(news)
self.session.commit()
elif spider.name == 'bsnews':
#这里写存入 News 表的逻辑
bsnews = BsNews()
...(省略部分代码)
self.session.add(bsnews)
self.session.commit()
return item
For this kind of problem where multiple crawlers are in one project, different crawlers need to use different logic in the pipeline. The author of scrapy explained it this way.
Go and have a look

PHP中文网2017-04-18 09:51:55
Yes, the process_item of pipelines has a spider parameter, which can filter the corresponding spider to use this pipeline
