
最近在读 shadowsocks 的源码,有一些疑惑。 shadowsocks 每次通过 epoll 监听到新连接之后,程序都会阻塞一段时间去执行 on_remote_read() 或 on_remote_write() 来传输数据,数据传输完毕之后才会再次调用 epoll 并 accept 新的 socket 连接,当连接达到一定数量之后,会出现高延迟、低效率的情况啊
# 在知乎上问了这个问题,没人理只好来 SegmentFault 啦~

PHP中文网2017-04-18 09:28:46
Because this process is a high-CPU and high-memory operation, not a high-hard disk IO operation. In other words, this process tests the CPU performance. And we know that computers do not have real multi-processes or multi-threads, they are all simulated through CPU scheduling. So for high-CPU operations, it is best to use a single-process or single-threaded method (multi-core can be considered to increase). This is the most efficient method, because it avoids the consumption caused by switching back and forth between threads or processes.
You can refer to the architecture of Nginx for this. The high load of Nginx is also completed in a single process.
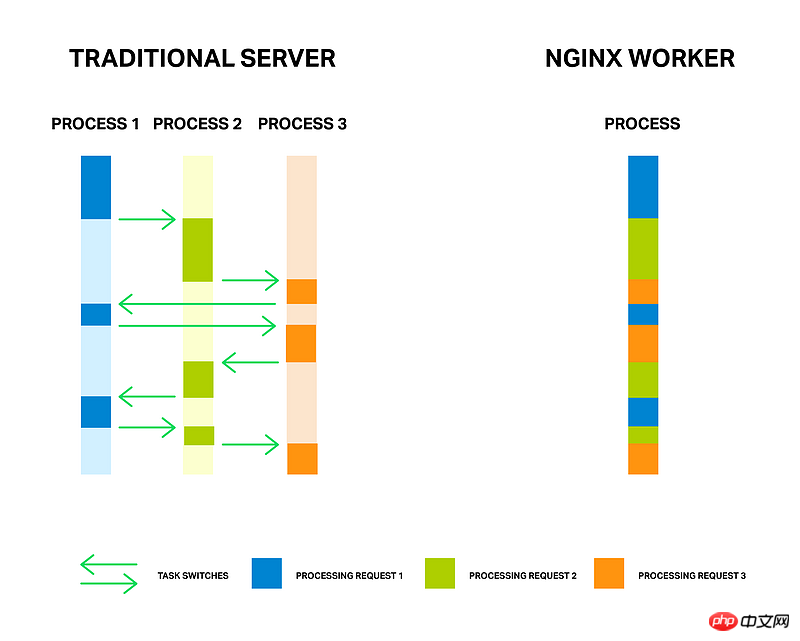

高洛峰2017-04-18 09:28:46
CPython’s multi-threading is not “real” multi-threading (see GIL for details). If you don’t change the language, the solution is to multi-process, with a load balancing (haproxy or the like) in front.

PHPz2017-04-18 09:28:46
There are multiple models for handling concurrent connections. Multithreading is one type, and the non-blocking I/O + multiplexing represented by epoll is also one type. As long as it is used correctly, read/write after a new connection comes in will not block even for a small period of time.
Experienced drivers in the early years have all read Dan Kegel’s The C10K Problem, which explains various concurrency processing models. If your English is passable, I still recommend you read it. Oh, by the way, if you are learning concepts that do not involve various technical enhancements made in the actual system to handle large concurrency, then Richard Stevens' "Unix Network Programming" explains it more clearly, and the Chinese translation is also easier to read. .
