
爬虫使用scrapy框架写的,使用脚本方式执行,配合APScheduler任务调度器定时执行,爬虫本身可以执行,只是定时执行失败,也没有报错误原因,日志见图,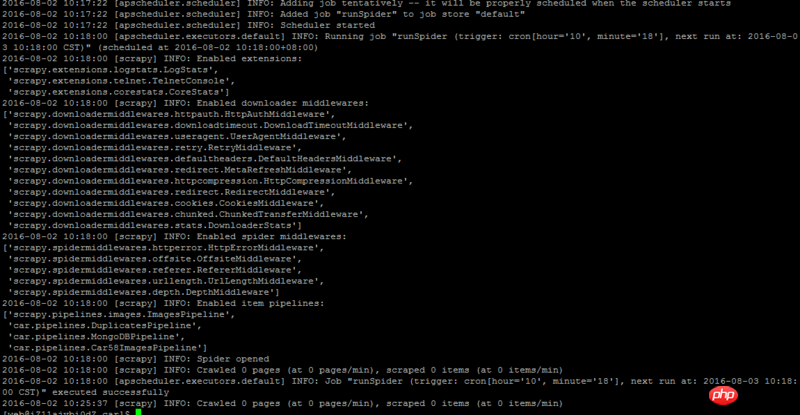
这是程序执行主要代码部分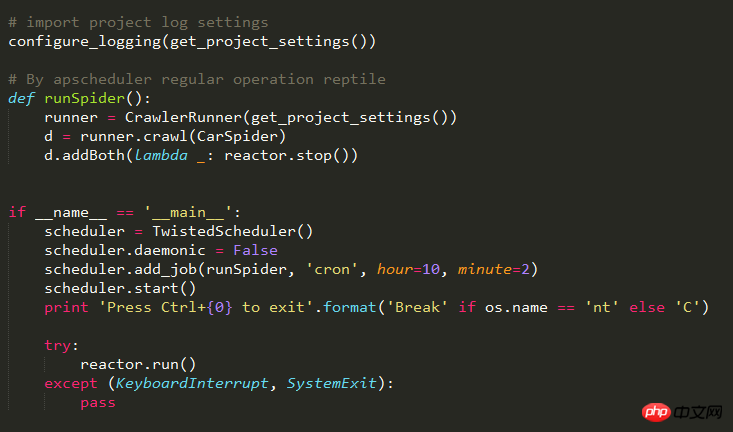
代码在windows系统可以运行,目前在Linux失败了,请问是什么原因?

ringa_lee2017-04-18 09:20:05
After much fiddling and searching over the wall, I finally got it running under Linux. The first time the crawler job was scheduled, it was turned on, but the web page was not parsed. Only when it was scheduled for the second time did it start parsing and work normally. My own guess is that it is related to react.run(). When the apscheduler task scheduling framework is used in conjunction with Scrapy, it must be used under the twisted framework. When the crawler task is to be executed regularly, the parsing will not be performed for the first time, but will be parsed for the second time.
