
最近想提取出特定的URL,遇到问题为预期提取出URL中带有webshell或者phpinfo字段的URL,但是全部URL都匹配出来了:
for url in urls:
if "webshell" or "phpinfo" in url:
print url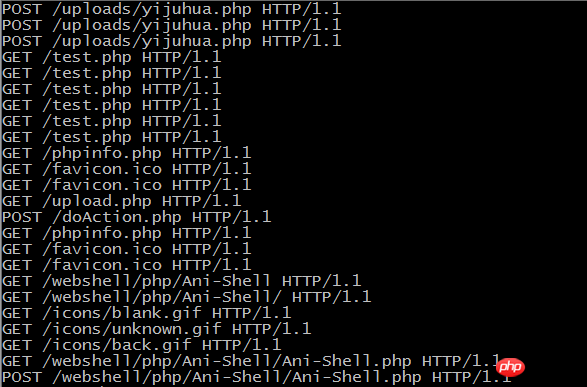
改成and语句也不符合预期,只提取出了含有phpinfo的url:
for url in urls:
if "webshell" and "phpinfo" in url:
print url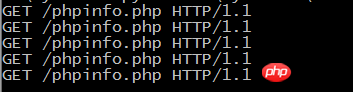

ringa_lee2017-04-18 09:07:15
for url in urls:
if "webshell" in url or "phpinfo" in url:
print url
That's it. You originally judged "webshell" first, and if it's not zero, then judge "phpinfo" in url. "webshell" and "phpinfo" in url are tied...

天蓬老师2017-04-18 09:07:15
if "webshell" or "phpinfo" in url:This means if "webshell" or if "phpinfo" in url and the former is always true.
if "webshell" and "phpinfo" in url:What this means is if "phpinfo" in url 因為 if "webshell" always established.
The solution is basically as @lock said:
for url in urls:
if "webshell" in url or "phpinfo" in url:
print url If there are a lot of words used to match today:
urls = [
'https://www.example.com/aaa',
'https://www.example.com/bbb',
'https://www.example.com/ccc',
]
def urlcontain(url, lst):
return any(seg for seg in url.split('/') if seg and seg in lst)
for url in urls:
if urlcontain(url, ['aaa', 'bbb']):
print(url)Result:
https://www.example.com/aaa
https://www.example.com/bbburlcontain(url, lst) 可以問 url 裡面是不是有 lst Any string inside
This way you can compare ten keywords without writing too long an if statement.
Of course you have to use re 也可以,只是我個人不太喜歡 re That’s it...
Questions I answered: Python-QA
