
我现在有一个行数很多的数据集,需要用这些数据集做分类算法,数据实在太多需要采样
数据集部分如下: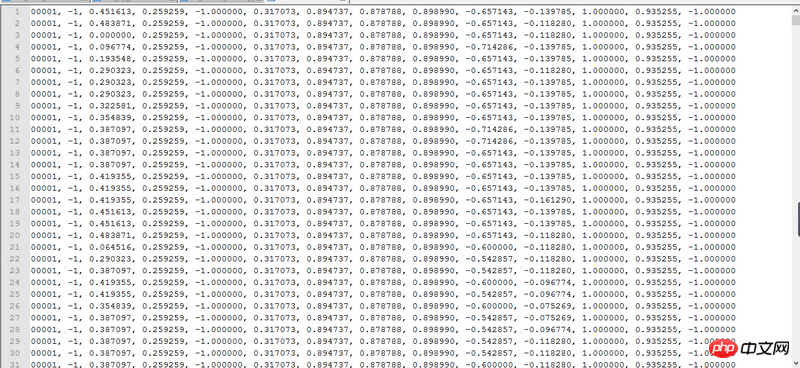
比如说我想每取10行放到一个新的文件中,就是取这个数据集的第1行,第11行,第21行。。。直到文本最后,放到一个新的文件中,用Python如何实现呢?
希望的结果如下: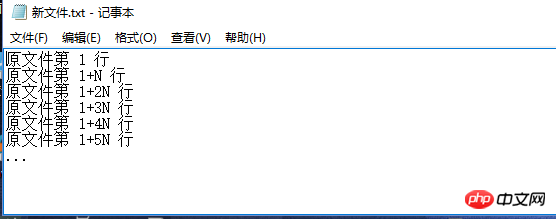
巴扎黑2017-04-17 17:55:59
with open('file.txt') as reader, open('newfile.txt', 'w') as writer:
for index, line in enumerate(reader):
if index % 10 == 0:
writer.write(line) 
阿神2017-04-17 17:55:59
Read line by line, read the line number and add one. If the line number is modulus to n, it is equal to 1. Write this line to a new file
巴扎黑2017-04-17 17:55:59
# 先得知道文件有多少行,linux下 `wc -l filename`,或者
line_count = sum(1 for i in open(filename))
# 然后pandas
pd.read_csv(filename, skiprows=(i for i in range(line_count) if i % 9 == 0))
# 如果文件不大,可以一次性读入内存
pd.read_csv(filename)[::10]