
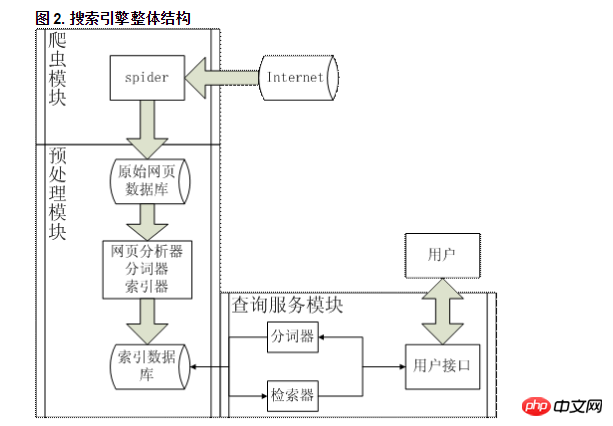
爬虫从 Internet 中爬取众多的网页作为原始网页库存储于本地,然后网页分析器抽取网页中的主题内容交给分词器进行分词,得到的结果用索引器建立正排和倒排索引,这样就得到了索引数据库,用户查询时,在通过分词器切割输入的查询词组并通过检索器在索引数据库中进行查询,得到的结果返回给用户。
请问这里原始网页库是该怎么实现,是直接存到数据库里吗?还是什么形式?
如果是存到数据库里,应该有哪些字段?

黄舟2017-04-17 17:49:58
#coding=utf-8
import urllib.request
import re
import os
'''
Urllib 模块提供了读取web页面数据的接口,我们可以像读取本地文件一样读取www和ftp上的数据
urlopen 方法用来打开一个url
read方法 用于读取Url上的数据
'''
def getHtml(url):
page = urllib.request.urlopen(url);
html = page.read();
return html;
def getImg(html):
imglist = re.findall('img src="(http.*?)"',html)
return imglist
html = getHtml("https://www.zhihu.com/question/34378366").decode("utf-8");
imagesUrl = getImg(html);
if os.path.exists("D:/imags") == False:
os.mkdir("D:/imags");
count = 0;
for url in imagesUrl:
print(url)
if(url.find('.') != -1):
name = url[url.find('.',len(url) - 5):];
bytes = urllib.request.urlopen(url);
f = open("D:/imags/"+str(count)+name, 'wb');
f.write(bytes.read());
f.flush();
f.close();
count+=1;
迷茫2017-04-17 17:49:58
What he means here is that the captured web pages are directly stored in the local disk in the form of files


PHP中文网2017-04-17 17:49:58
It is recommended that you use the Shenjianshou Cloud Crawler (http://www.shenjianshou.cn). The crawler is completely written and executed on the cloud. There is no need to configure any development environment, and rapid development and implementation are possible.
A simple few lines of javascript can implement complex crawlers and provide many functional functions: anti-anti-crawlers, js rendering, data publishing, chart analysis, anti-leeching, etc., which are often encountered in the process of developing crawlers. All problems will be solved by Archer.
Collected data:
(1) You can choose to publish it to a website, such as wecenterwordpressdiscuzdedeempire and other cms systems
(2) You can also publish it to a database
(3) or export a file To local
The specific settings are in "Data Publishing & Export"