问题:
爬取信息页面为:知乎话题广场
当点击加载的时候,用Chrome 开发者工具,可以看到Network中,实际请求的链接为: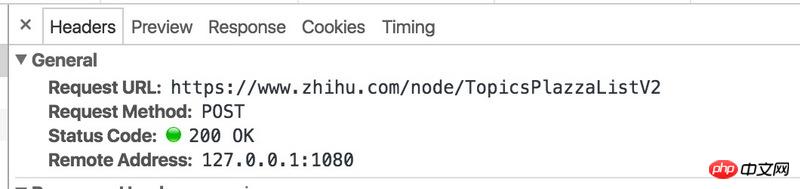
FormData为:
urlencode:
然后我的代码为:
...
data = response.css('.zh-general-list::attr(data-init)').extract()
param = json.loads(data[0])
topic_id = param['params']['topic_id']
# hash_id = param['params']['hash_id']
hash_id = ""
for i in range(32):
params = json.dumps({"topic_id": topic_id,"hash_id": hash_id, "offset":i*20})
payload = {"method": "next", "params": params, "_xsrf":_xsrf}
print payload
yield scrapy.Request(
url="https://m.zhihu.com/node/TopicsPlazzaListV2?" + urlencode(payload),
headers=headers,
meta={
"proxy": proxy,
"cookiejar": response.meta["cookiejar"],
},
callback=self.get_topic_url,
)执行爬虫之后,返回的是:
{'_xsrf': u'161c70f5f7e324b92c2d1a6fd2e80198', 'params': '{"hash_id": "", "offset": 140, "topic_id": 253}', 'method': 'next'}
^C^C^C{'_xsrf': u'161c70f5f7e324b92c2d1a6fd2e80198', 'params': '{"hash_id": "", "offset": 160, "topic_id": 253}', 'method': 'next'}
2016-05-09 11:09:36 [scrapy] DEBUG: Retrying <GET https://m.zhihu.com/node/TopicsPlazzaListV2?_xsrf=161c70f5f7e324b92c2d1a6fd2e80198¶ms=%7B%22hash_id%22%3A+%22%22%2C+%22offset%22%3A+80%2C+%22topic_id%22%3A+253%7D&method=next> (failed 1 times): [<twisted.python.failure.Failure OpenSSL.SSL.Error: [('SSL routines', 'SSL3_READ_BYTES', 'ssl handshake failure')]>]
2016-05-09 11:09:36 [scrapy] DEBUG: Retrying <GET https://m.zhihu.com/node/TopicsPlazzaListV2?_xsrf=161c70f5f7e324b92c2d1a6fd2e80198¶ms=%7B%22hash_id%22%3A+%22%22%2C+%22offset%22%3A+40%2C+%22topic_id%22%3A+253%7D&method=next> (failed 1 times): [<twisted.python.failure.Failure OpenSSL.SSL.Error: [('SSL routines', 'SSL3_READ_BYTES', 'ssl handshake failure')]>]是不是url哪里错了?请指点一二。

伊谢尔伦2017-04-17 17:46:32
DEBUG: Retrying <GET It’s hard to tell from such a big prompt. . . The request when you capture the packet is post. Why use get when using scrapy? . .
伊谢尔伦2017-04-17 17:46:32
Writing a crawler should be done step by step, not in one step, otherwise you won’t know what went wrong. Generally, you need to get the data you want first, and then parse and filter.
Send a request first to see if you can get the data you want. If not, the URL may be wrong or blocked

大家讲道理2017-04-17 17:46:32
#coding=utf-8
import requests
headers = {'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8'}
url = 'https://www.zhihu.com/node/TopicsPlazzaListV2'
data = 'method=next¶ms=%7B%22topic_id%22%3A833%2C%22offset%22%3A0%2C%22hash_id%22%3A%22%22%7D'
r = requests.post(url, data, headers=headers)
print r.text