
import json
f_member = open(r'C:\Users\Desktop\xxxx.json')
users = json.loads(f_member.read(), encoding="utf8")然后报错了
json.decoder.JSONDecodeError: Invalid control character at: line 388080 column 18 (char 4802144)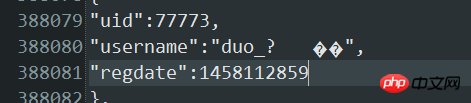
信息量很大,我不能手动去一条一条删这种吧...
如何略过这一行呢?

大家讲道理2017-04-17 17:31:48
1) Try using the open function of codecs. When reading data, you can specify the encoding method of the read data stream
codecs.open(filename, mode[, encoding[, errors[, buffering ]]])
Open an encoded file using the given mode and return a wrapped version providing transparent encoding/The default file mode is ’r’ meaning to open the file in read mode.
Note: The wrapped version will only accept the object format defined by the codecs, i.e. Unicode objects for most built-in codecs. Output is also codec-dependent and will usually be Unicode as well.
Note: Files are always opened in binary mode, even if no binary mode was specified. This is done to avoid
loss due to encodings using 8-bit values. This means that no automatic conversion of ‘n’ is done on reading and writing.
specifies the encoding which is to be used for the file.
may be given to define the error handling. It defaults to ’strict’ which causes a ValueError to be raised in case an encoding error occurs.
has the same meaning as for the built-in open() function. It defaults to line buffered
2) Judge the data in json.loads character by character, skip the non-utf-8 encoding, and load after getting the complete string
