
最近初学用Python写网页爬虫视图扒取一个站点上的特定数据。
最近碰到的一个现象是,当爬虫运行了一段时间后(根据Fiddler抓包的结果来看,大概是发送了将近3万个http请求后),爬虫的获取的http响应的StatusCode骤然都变成了 504, 之后就再也获取不到200的响应了。
想请教一下各位大神,这种现象是否是由于扒取对象的站点的反爬虫策略造成的?
如果是的话,有什么常用的回避策略么?
P.S.
还注意到一个现象,不知与上述现象是否有关,一并描述:
即当爬虫的响应变成504之后,发现我的浏览器的代理选项被自动勾上了,如下所示:
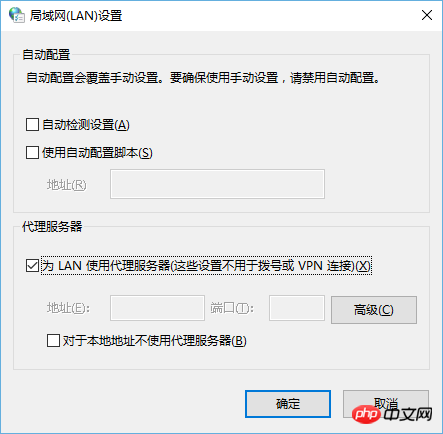

PHP中文网2017-04-17 17:27:54
The proxy option is checked, which is caused by fiddler. In the past, I often used fiddler to capture packets. After a period of time, I could not access the network. Uncheck the proxy option and the problem was solved

ringa_lee2017-04-17 17:27:54
You can pay attention to an open source component I wrote, set up a proxy server pool to prevent the blocking of anti-crawler strategies, and automatically adjusted the request frequency, handled abnormal requests, and prioritized agents with fast responses. https://github.com/letcheng/ProxyPool

PHP中文网2017-04-17 17:27:54
1.Agent
2. Simulate a complete request
3. Reasonable intervals
4.adsl disconnection and redial

PHPz2017-04-17 17:27:54
Method:
Change the IP and use a proxy IP. There are many free and paid ones on the Internet
Free IP: http://www.uuip.net/
Paid IP: http://www.daili666.net/


天蓬老师2017-04-17 17:27:54
Why is the answer to this question like this? The 50x error lies in the website itself