
打印出返回的用户信息的json值,如果是中文会出现乱码,比如省份,得到的值为u'province': u'\xe6\xb5\x99\xe6\xb1\x9f', 不知道哪里出错了。
另外,如果对返回的json值作解码,居然会出现40029错误。

高洛峰2017-04-17 15:40:02
That's right. The questioner, please try printing 'xe6xb5x99xe6xb1x9f'. Doesn't this mean "Zhejiang" is printed out? 
First of all, there is a bug in python2's print, that is, although x = {'province': 'Zhejiang'}, print x will still display {'province': 'xe6xb5x99xe6xb1x9f'}. 
This problem has been solved in Python3. 
But look carefully this is not your case. Your problem is that the utf8-encoded string is treated as a unicode-encoded string and put into the unicode object.
At this time only (assuming that the object after your json deserialization exists in x)
python>>> print x[u'province'].encode('raw_unicode_encoding') '浙江'
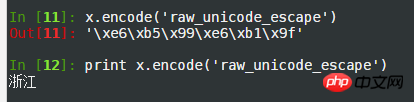
Voilà!

PHPz2017-04-17 15:40:02
It should be that the encoding format is not set. When obtaining user information, set the encoding to UTF-8. In addition, the parameters https://api.weixin.qq.com/cgi-bin/user/info?access_token=ACCESS_TOKEN&openid=OPENID&lang=zh_CN in the interface for obtaining user information lang=zh_CN should be brought.
As for the 40029 error, it may be that the code obtained through authorization has expired. The code can only be used once and will automatically expire if not used for 5 minutes.

大家讲道理2017-04-17 15:40:02
@lohocla4dam's answer helped me a lot, but I need to make some additions, because his answer is for python2, and my answer here is for python3
According to https://docs.python.org/3/library/codecs..., the encoding is changed to raw_unicode_escape, which is
>>> print(x['province'].encode('raw_unicode_escape')