怪我咯2017-04-17 15:36:05
The questioner probably has a misunderstanding about encoding and decoding.
getBytes(String charsetName) refers to encoding the string using the encoding format represented by chasetName to obtain a byte array.
String(byte bytes[], String charsetName) The construction method refers to using the encoding format represented by chasetName to decode the direct array to obtain a string.
In other words, to get a character array encoded in a certain format, just use getBytes(String charsetName). The byte array needs to be decoded using the same encoding format used to encode it. Otherwise the code will be garbled. If you use an already garbled string to convert the encoding at this time, you may not be able to get the previously correctly encoded byte array.
Example:
String str = "上海上海"; // 我这设置 file.encoding 为 UTF-8
byte[] utf8Bytes = str.getBytes("utf-8");
byte[] defaultBytes = str.getBytes();
Assert.assertArrayEquals(utf8Bytes, defaultBytes);
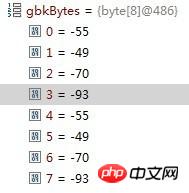
byte[] gbkBytes = str.getBytes("GBK");
// Assert.assertArrayEquals(utf8Bytes, gbkBytes);// 这儿不过!! array lengths differed, expected.length=12 actual.length=8。
String errorStr = new String(gbkBytes, "utf-8");// 此时是乱码的
Assert.assertNotEquals(str, errorStr); // 肯定不一样
byte[] errorUtf8Bytes = errorStr.getBytes("utf-8"); // 乱码后重新编码
// Assert.assertArrayEquals(gbkBytes, errorUtf8Bytes); // 不过! 已经和之前的字节数组不一样了。array lengths differed, expected.length=8 actual.length=16
// Assert.assertArrayEquals(utf8Bytes, errorUtf8Bytes); // 不过! 更不会和 utf8Bytes 相同。array lengths differed, expected.length=12 actual.length=16
Where: errorStr is "�Ϻ��Ϻ�"
The other byte array is:


reply
0


