
还以书上例子来说
sqlcreate table people( last_name varchar(50) not null, first_name varchar(50) not null, dob date not null, gender enum('m','f') no null, key(last_name,first_name,dob) );
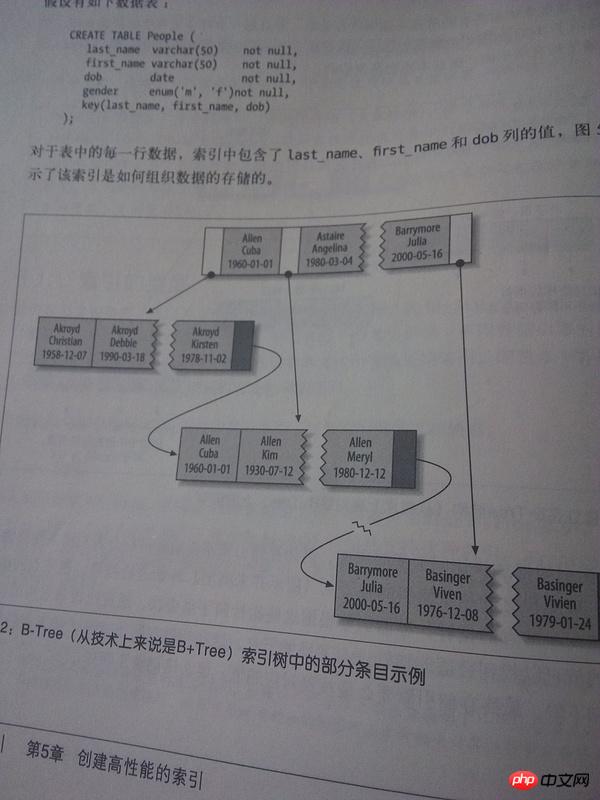
这个 B+tree 的索引示意图能明白,但是为什么马上在下文就说"B+树索引适用于全键值,键值范围或者最左键前缀查找"
我应该如何去理解,是否和 B+tree 有着不可分割的关系,应该如何理解.
巴扎黑2017-04-17 13:00:12
The understanding of this sentence is indeed closely related to the principle of B+ tree.
Let's look at a simple B+ tree diagram. This diagram has a root node and only leaf nodes (no intermediate nodes). 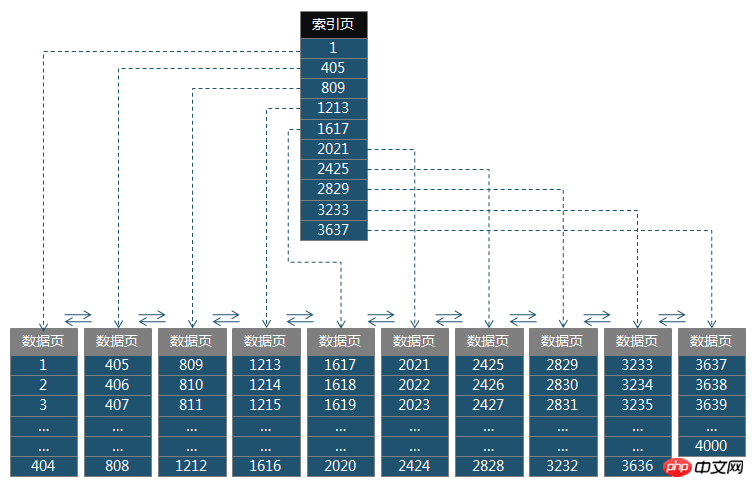
Compared with the B-tree, the B+ tree has the following characteristics: the elements of the upper-level node will appear in the lower-level node. For example, "1" in the root node in the figure will also appear in the first leaf node. points; leaf nodes are connected to each other (this is a doubly linked list structure).
Now assume that the root node in the graph stores the primary key ID, and the leaf nodes store data items (including the primary key ID, and other columns). Now we want to execute SQL like this:
SELECT *
FROM table
WHERE id = 2426
At this time, the database will search for id=2426 in the root node. Search from top to bottom in the root node. You can find that 2426 is between 2425 and 2829, so you need to search in the 7th leaf node. You can find the data with id=2426. This is how to search for key values in the B+ tree. You can see that to find the data with id=2426, you only need to access two nodes of the B+ tree, and the disk IO overhead is relatively small.
When you want to execute SQL like this:
SELECT *
FROM table
WHERE id > 407 AND id < 1618
This involves the problem of key value range search. First look at 407, which is between 405 and 809 in the root node, so you should start looking at the second leaf node. Since the leaves of the B+ tree The node is a doubly linked list, which means that after the second data page 406-808 is retrieved, you can jump directly to the next leaf node to retrieve until all the required data is retrieved.
If you want to deepen your understanding of the advantages of B+ trees, you can compare them with B-trees.
巴扎黑2017-04-17 13:00:12
This statement is incorrect,
If it’s just the advantages in your question, then obviously a binary tree is more suitable,
However, in use, the binary tree is unstable and may become a singly linked list, so there is also a balanced binary tree.
Moreover, as the amount of data increases, the search efficiency decreases exponentially, because the search efficiency of a binary tree is directly proportional to its level.
B-tree and B+ tree are both improved on the basis of binary trees (but not binary trees themselves) and are a balancing strategy.
The B+ tree narrows the scope through the parent node, and then traverses the leaf nodes to find, which is not the most efficient,
However, due to the design of IO for database or file operations, this greatly reduces IO, so it is fast.
The above is a range search. For point search, hash is more suitable.
