
** I crawled data from referee documents before. After re-running the crawler during this period, I found that the web page data could not be obtained.
After searching, I found that the source code of the requests web page returned garbled characters**
(Intercept part of the returned data as follows: <meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<meta id="JLyKZlWgYjpTkAsEt9LnA" ) 
#I don’t know if the website has encrypted the content of the web page. How can I solve this problem? Thanks!
Intercept part of the program source code:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-TW,zh;q=0.8,en-US;q=0.6,en;q=0.4',
'Accept-Encoding': 'gzip, deflate',
'Connection': 'keep-alive',
'Content-Type': 'text/html; charset=utf-8'}
html = requests.post('http://wenshu.court.gov.cn/List/ListContent', data=data, headers=headers)
print(html.text)But the data that should be returned is returned in the review element. What is the problem? 
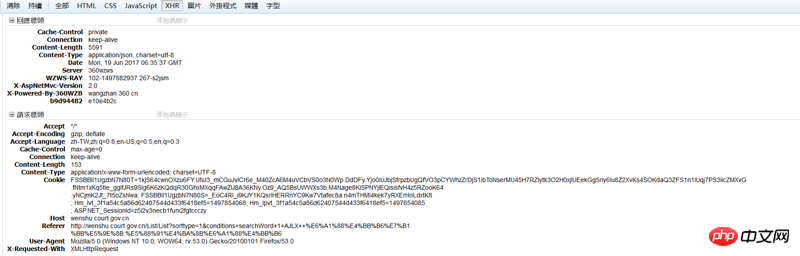
The data returned when the program was running normally was like this: 
仅有的幸福2017-06-22 11:53:56
Ajax loaded result page, if no feedback results similar to json can be obtained in the network. Just use PHANTOMJS to simulate loading. Then match crawling.

高洛峰2017-06-22 11:53:56
The encoding used by your html object is wrong.
Add a line html.encoding = html.apparent_encoding
Infer the encoding based on the actually obtained text and re-decode it.

怪我咯2017-06-22 11:53:56
If you are willing to drill, I will give you a reference address: http://www.qingpingshan.com/j...
