
First code:
a = "hello" #定义一个字符串的变量
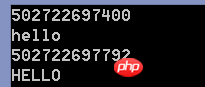
print(id(a)) #第一次的地址
print(a) #a = hello
a = a.upper() # 单纯的a.upper() 执行过后,无法存储到a本身,必须得重新赋值给a 换句话说,a在被upper之后,重新指向了一个新的地址
print(id(a)) #第二次的地址
print(a)The first code execution result:
Second code:
b = [11,22,33,44,55] #定义一个列表的变量
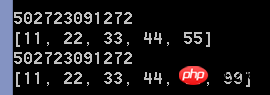
print(id(b)) #第一次的地址
print(b) #b = [11,22,33,44,55]
b.append(99) #单纯的b.append()执行过后,不需要存储到b,因为b已经被更改
print(id(b)) #检查第一次的地址
print(b) #发现在第一次地址当中,b已经改变
#b = b.append(99) #如果将修改b这个行为赋值到b
#print(id(b)) #检查地址,发现已经变更
#print(b) #检查b的值,发现已经变更。b的值为none 因为b.append(99)本身的返回值为none
#[***列表为可修改变量,因此修改完之后,地址跟原来的一样。反而是如果像修改字符串那样重新赋值,变得不可行。原因在于append语句本身并不返回值。***]
#字符串赋值之后放在内存一个地址,这个地址上面的字符串是无法更改的,只能重新做一个新的字符串,然后改变变量的指向位置。
#而列表赋值之后存在一个内存的地址,这个列表里面的值是可以直接修改的。不需要重新做一个新的列表,然后改变变量的指向位置。The second code execution result:
In the process of learning python, I was told that strings are immutable types and lists are mutable types. In other words, if I want to change a string, I actually create a new string and put it in the new address of the memory. The original string is still the same. As shown in the first piece of code.
The list is different. The list can be modified directly at the original memory address. As shown in the second piece of code.
My question:
What is the fundamental difference between variable types and immutable types? Why does this difference occur? Why in the first code, if a wants to change, the address must be changed, but in the second code, b can directly modify the value of the list without changing the address. What is the underlying logic here? I wonder if it means that the list itself is actually a collection of values. It just reflects the collection itself and points a collection of values to this one place, so it can be modified. ? I don't know if I expressed it clearly.
I'm just curious about this thing. That is to say, what exactly is a list? Why can it be changed directly? The string cannot be changed. After going deeper to the bottom, what are the two of them?

大家讲道理2017-06-12 09:23:12
In fact, objects are mutable and immutable. For py, it is all a matter of internal implementation. If I modify the corresponding method and write it back to itself, I can also imitate the mutable phenomenon, which is slightly similar to tuple The relationship between and list,
Since you want to understand the bottom layer, let’s look at the source code directly:
This is the upper()
static PyObject *
string_upper(PyStringObject *self)
{
char *s;
Py_ssize_t i, n = PyString_GET_SIZE(self); # 取出字符串对象中字符串的长度
PyObject *newobj;
newobj = PyString_FromStringAndSize(NULL, n); # 可以理解成申请内存空间
if (!newobj)
return NULL;
s = PyString_AS_STRING(newobj); # 从newobj对象取出具体字符串指针
Py_MEMCPY(s, PyString_AS_STRING(self), n); # 拷贝旧的字符串
for (i = 0; i < n; i++) {
int c = Py_CHARMASK(s[i]);
if (islower(c))
s[i] = _toupper(c); # 修改对应指针位置上的内容
}
return newobj; # 返回新字符串对象 (区分字符串对象和里面字符串的指针)
}
This is the listappend
int
PyList_Append(PyObject *op, PyObject *newitem)
{
if (PyList_Check(op) && (newitem != NULL))
return app1((PyListObject *)op, newitem);
PyErr_BadInternalCall();
return -1;
}
static int
app1(PyListObject *self, PyObject *v)
{
Py_ssize_t n = PyList_GET_SIZE(self);
assert (v != NULL);
if (n == PY_SSIZE_T_MAX) {
PyErr_SetString(PyExc_OverflowError,
"cannot add more objects to list");
return -1;
}
if (list_resize(self, n+1) == -1)
return -1;
Py_INCREF(v);
PyList_SET_ITEM(self, n, v); # 因为列表是头和和成员分开的, 所以直接将新成员追加在原来的成员数组后面, 长度变化通过resize实现
return 0;
}巴扎黑2017-06-12 09:23:12
Python strings are cached. If two identical strings are in different variables a and b, their id(a) and id(b) are the same.
But if the reference of a and b is 0, the object will be automatically destroyed.
Example of the original poster:
a = a.upper()
The variable content ofa has changed and is different. The old content has no reference and the object is destroyed by garbage collection.
b is a list, it is variable, and you can apply for memory again. At the same time, b has content reference and will not be destroyed.
为情所困2017-06-12 09:23:12
Go deeper and look at the C source code of python~
It can be immutable, which is stipulated by the python language.
Immutable types do not provide methods to modify the object itself, while mutable types provide these methods. There is nothing mysterious about these differences.
仅有的幸福2017-06-12 09:23:12
From a hardware perspective, the interface provided to users is set according to regulations, and the memory is operated in a fixed way. There is no mutability or immutability.
Going up is the operating system layer, which encapsulates a large number of hardware APIs to enrich user operations. The Python interpreter is written in C language. When using Python, only Python pragmatics are used to write code. Then it is handed over to the interpreter for execution. Under the above premise, to explain the current problem, the mutability and immutability of Python are stipulated by the creator of Python. The way to implement these regulations may be to call different underlying APIs, or different The underlying APIs are implemented by combining each other. These provisions are provided to users in the form of Python pragmatics, and finally compiled into 0,1 for computer execution. For users, mutable and immutable objects are a feature provided by the language and can complete some functions, but there is actually no difference for computers.