
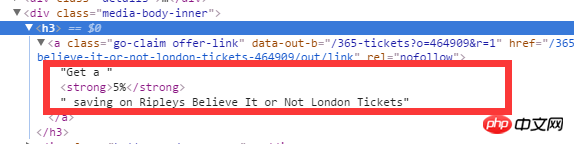
I want to get the complete content under the a tag under h3 (Get a 5% saving on Ripleys Believe It or Not London Tickets). How to get this using xpath? I beg for advice from experts

阿神2017-05-24 11:37:18
The most convenient way is to select it and there is an option to copy to xpath

黄舟2017-05-24 11:37:18
The previous answer did not address the original poster’s question, because the original poster did not describe the problem clearly. I think what the original poster wanted to say is that you cannot get the content in the sub-tag by directly using the text() method or text attribute (assuming you have already seen it) The basic syntax of xpath).
Google search xpath get all text, the first one is the answer.
The poster can ask this question: How to use xpath to extract the text content contained in the tag (although the answer here is not satisfactory)
漂亮男人2017-05-24 11:37:18
You try it
response.xpath('//h3/a/descendant-or-self::text()[normalize-space()]')
descendant-or-self indicates the current node and descendant nodes
normal-space() removes the descendant nodes of whitespace-only nodes (this is optional)
Reference link:
http://stackoverflow.com/ques...
