
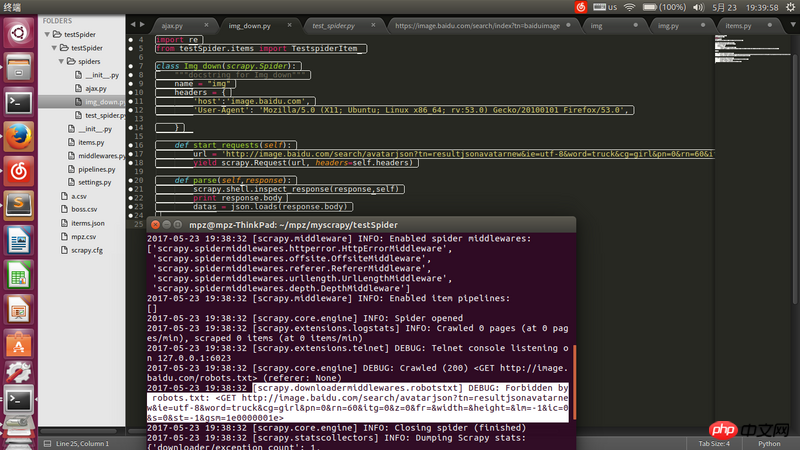
The request address url is the address of json obtained through firefox. It can be opened with a browser, but it was banned when crawling with scrapy. Please solve it.
https://image.baidu.com/searc...

为情所困2017-05-24 11:36:48
I agree with the upstairs, if there will still be a wall. The method of scrapy+selenium+phantomjs can be used.