
https://www.everysaving.co.uk
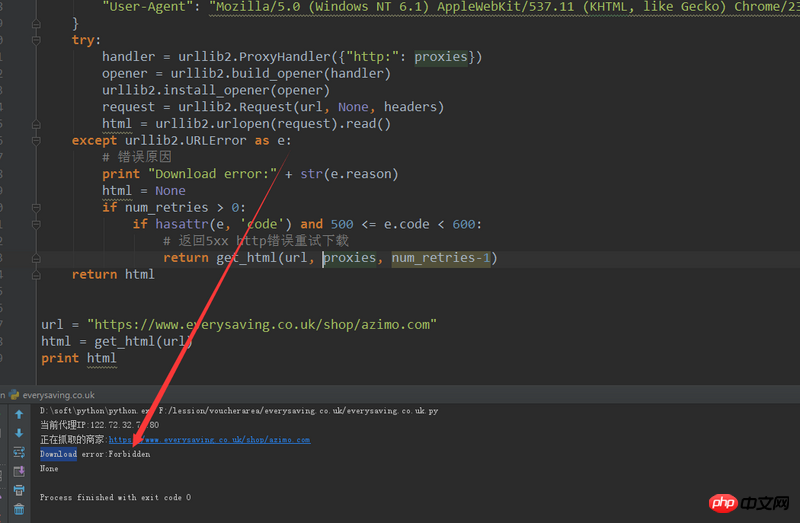
Crawling the data of this website through python, but the data cannot be returned! I added the header and proxy IP to crawl, but it didn't work. I hope you guys can give it a try. . .

迷茫2017-05-18 11:03:00
The proxy access website can be seen in the picture below: 
Through https://www.17ce.com/, I found that almost all mainland China is blocked, and the HTTP status returns 403.
The security policy level of this website is relatively high. It is recommended to use a high-anonymity proxy VPN or server in Europe and the United States to reduce the frequency of crawling.
迷茫2017-05-18 11:03:00
Your address cannot be accessed directly through the browser. Is it blocked?
过去多啦不再A梦2017-05-18 11:03:00
I can’t access it if I click on it directly. I tested it using a proxy in Singapore and it can be opened