
source_ip = line.split('- -')[0].strip()
if re.match('[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}',source_ip):
if source_ip_dict.get(source_ip,'-')=='-':
source_ip_dict[source_ip]=1
else:
source_ip_dict[source_ip]=source_ip_dict[source_ip]+1Extract the apache log IP through the above code, and perform statistical deduplication.
The extracted IP data is as follows: 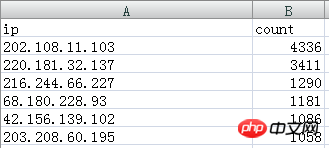
So how to name and classify these IP addresses,
For example,
202.108.11.103 and 220.181.32.137 are Baidu Spider IPs
The effect you want to achieve is as follows
The two IPs are named Baidu Spider, and then add their statistics together, that is 4336 3411
Baidu Spider 7747
How to do this
仅有的幸福2017-05-18 11:02:19
from itertools import groupby
NAME_IP_MAPPING = {
'202.108.11.103':'百度蜘蛛',
'220.181.32.137': '百度蜘蛛',
}
spiders = [
{'ip':'202.108.11.103','count':123},
{'ip':'220.181.32.137','count':345}
]
# 先用ip通过映射得到名字,再根据名字将spiders里的item分组,之后各自求和存入新的dict中。
{k: sum(s['count'] for s in g)
for k, g in groupby(spiders, lambda s:NAME_IP_MAPPING.get(s['ip']))}
# output: {'百度蜘蛛': 468}
黄舟2017-05-18 11:02:19
You can try to build a large dictionary with the dictionary as the key and the crawler name as the value;
ip_map = {
'202.108.11.103': 'baidu-spider',
'220'.181.32.137: 'baidu-spider',
'192.168.1.1': 'other'
....
}
sum = {}
for ip in source_ip:
print ip
sum[ip_mapping.get(ip, 'other')] = sum.get(ip, 0) + source_ip[ip]
print sum

阿神2017-05-18 11:02:19
How tiring it is!
Why not create a separate table for this IP group, named IPGroup (id, ip, groupname)
| id | ip | groupName |
|---|---|---|
| 1 | 202.108.11.103 | Baidu Spider |
| 2 | 220.181.32.137 | Baidu Spider |
After that, it can be done with just one SQL, how easy it is (let the poster use IPStastics)
SELECT b.groupName, SUM(a.count)
FROM IPStastics a
INNER JOIN IPGroup b
ON a.ip = b.ip
GROUP BY b.groupName