
1. The data format is very simple. There are four weeks or 28 days of data. There are 144 data every day and a total of 4032, as follows:
11.028366381681027
11.127100875673675
10.892770602791097
8.6224245909897488
8.0099274624457563
8.1184195540896
8.0262697485121513
8.5141785771838925
······
Use Sij to represent the i-th observation value on the j-th day of the week, where j=1,2,3,4,5,6,7; i=1,2,3,…,144;
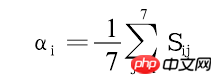
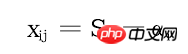
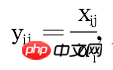
Now I want to find the value of 4032 Yij
I wrote a somewhat complicated one, but it doesn’t feel right. Please help me, thank you
from __future__ import pision
import matplotlib.pyplot as plt
with open('training_data.txt')as reader,open('weken4-4.txt','w')as writer:
sum1=[0 for x1 in range(0,144)]
sum2=[0 for x2 in range(0,144)]
sum3=[0 for x3 in range(0,144)]
sum4=[0 for x4 in range(0,144)]
data=[0 for y1 in range(0,4032)]
for index,line in enumerate(reader):
for i in range(0,144):
if index<1008:
if (index-i)%144==0:
sum1[i]=sum1[i]+float(line)
if 1008<=index<2016:
if (index-i)%144==0:
sum2[i]=sum2[i]+float(line)
if 2016<=index<3024:
if (index-i)%144==0:
sum3[i]=sum3[i]+float(line)
elif 3024<=index<4032:
if (index-i)%144==0:
sum4[i]=sum4[i]+float(line)
file = open('training_data.txt','r')
for j in range(0,4032):
line = file.readline()
a= line.split()
if j<1008:
data[j]=(float(a[0])-(sum1[j%144]/7))/(sum1[j%144]/7)
if 1008<=j<2016:
data[j]=(float(a[0])-(sum2[j%144]/7))/(sum2[j%144]/7)
if 2016<=j<3024:
data[j]=(float(a[0])-(sum3[j%144]/7))/(sum3[j%144]/7)
elif 3024<=j<4032:
data[j]=(float(a[0])-(sum4[j%144]/7))/(sum4[j%144]/7)

ringa_lee2017-05-18 11:00:40
Let’s find the average deviation ratio of each point every week! The key is to define the data structure, and everything else will be easy to handle!
from __future__ import pision
# 4*7*144维度的列表
data = [
[[0]*144 for i in range(7)]
for _ in range(4)
]
# 4*144维度的列表
data_sum = [[0]*144 for i in range(4)]
data_avg = [[0]*144 for i in range(4)]
# 结果
with open('training_data.txt')as reader,open('weken4-4.txt','w')as writer:
# 初始化数据
for i in range(4):
for j in range(7):
for k in range(144):
v = float(reader.readline())
data[i][j][k] = v
data_sum[i][k] += v
# 求平均
for i in range(4):
for j in range(144):
data_avg[i][j] = data_sum[i][j] / 144
# 求结果
for i in range(4):
for j in range(7):
for k in range(144):
v = (data[i][j][k] - data_sum[i][k]) / data_avg[i][k]
writer.write('{}\n'.format(v))
