
I want to capture the house profiles separately and store them in the dictionary as independent columns, but there is no way to directly extract the inline elements using a for loop.
This is my code:
soup.select('.house-info li')[1].text.strip()This is the html code of the web page:
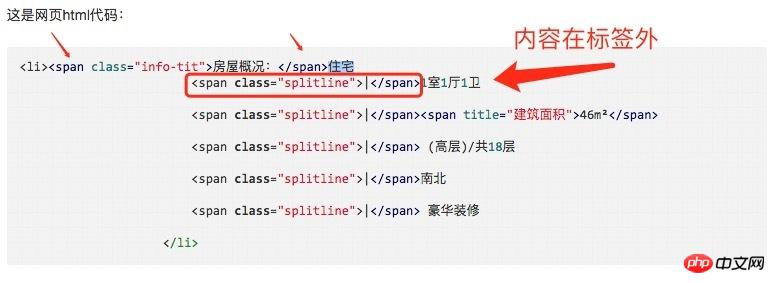
<li><span class="info-tit">房屋概况:</span>住宅
<span class="splitline">|</span>1室1厅1卫
<span class="splitline">|</span><span title="建筑面积">46m²</span>
<span class="splitline">|</span> (高层)/共18层
<span class="splitline">|</span>南北
<span class="splitline">|</span> 豪华装修
</li>曾经蜡笔没有小新2017-05-18 10:54:42
Actually, it is very simple. You can see that there is a pattern in this. The pattern lies in the separator |. I wrote a DEMO
something = '''<li><span class="info-tit">房屋概况:</span>住宅 <span class="splitline">|</span>1室1厅1卫<span class="splitline">|</span><span title="建筑面积">46m²</span><span class="splitline">|</span> (高层)/共18层
<span class="splitline">|</span>南北
<span class="splitline">|</span> 豪华装修
</li>''';
soup = BeautifulSoup(something, 'lxml')
plaintext = soup.select('li')[0].get_text().strip()Get all the inner content through get_text(), and then remove the spaces. You can use split to divide it later, and I won’t write the rest.
If you have any questions, please communicate.
给我你的怀抱2017-05-18 10:54:42
House Overview:
46m²
滿天的星座2017-05-18 10:54:42
In your case, I think it is most convenient to use a for loop plus regular expressions, if all templates are fixed like this

黄舟2017-05-18 10:54:42
用pyquery吧
from pyquery import PyQuery as Q
Q(text).find('.house-info li').text()