
sql语句是:
explain SELECT bp.amount / (select count(*) from yd_order_product where order = bp.order and product = bp.product) as amount,s.costprice as price,s.store,b.type from yd_batch_product as bp left join yd_order_product as op on op.order = bp.order and op.product = bp.product left join yd_batch as b on bp.batch = b.id left join yd_order as o on bp.order = o .id left join yd_stock as s on bp.product = s.id where o.deleted = '0' and s.forbidden = '0' and b.createdDate between '2015-10-13 00:00:00' and '2017-04-30 23:59:59' and s.store in (1,2,3,4,5,6) and s.chainID = 1
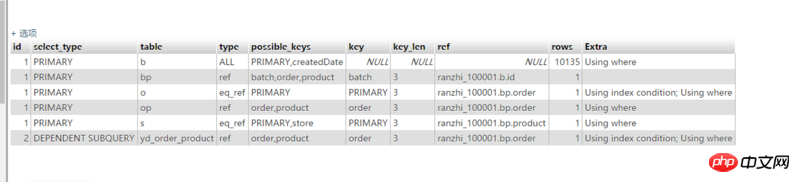
请问下这个第一行的type值为什么会是ALL
巴扎黑2017-05-16 13:15:12
@TroyLiu, your suggestion is that too many indexes are created, and the idea of establishing a combined order/product/batch/amount index feels wrong.
The core idea of SQL optimization is that the big data table can filter the data according to the conditions in the existing where statement. In this example:
yd_batch_product table should be the largest, but in the where statement There are no filtering conditions, resulting in poor execution efficiency.
The reason why "Using temporary; Using filesort" appears is that the fields in group by are not completely within the field range of the first table yd_batch_product table.
Suggestions:
1. yd_batch/yd_order/yd_stock uses LEFT JOIN, but there are filter conditions for these table fields in the where statement, so it is equivalent to INNER JOIN, so the connection method can be changed to INNER JOIN, so mysql When judging the execution plan, you can not only query the yd_batch_product table first.
2. Create an index on the createdDate field of the yd_batch table to see if there is any change in the first driver table in the execution plan. If the condition of createdDate is very filtering, the first table in the execution plan should be yd_batch.
3. The yd_stock table, how to combine store and chainID to achieve strong filtering, can create a combined index, and determine whether the execution plan has changed in the same way as the previous step.
Of course, the most ideal situation is to start from the business and data, find out the conditions on the yd_batch_product table that can filter a large amount of data, and then create an index based on this condition. For example, the createdDate field of the yd_batch table also has similar redundant fields on the yd_batch_product table, and this field is used to create an index.
Suggestions after updating the question:
1. TYPE=ALL indicates that a full table scan is used. Although createdDate has already created an index, the database evaluation believes that using a full table scan is cheaper and is generally considered normal (the range of createdDate Larger, including more than one year of data, more than 10,000 items in total). If you want to use an index, you can narrow the range within a few days and see if there is any change in the execution plan. Of course, you can also use prompts to force the use of indexes, but the efficiency is not necessarily high.
2. The yd_order_product table is queried twice, especially the select subquery in the execution plan, which should be avoided as much as possible.

阿神2017-05-16 13:15:12
First of all, the amount of data in the yd_batch_product table is very large, and the index is not created correctly, resulting in the entire query not utilizing the index.
It can be seen from the corresponding key column of table bp is NULL.
Optimization reference:
Create a joint index on the order/product/batch/amount column for the yd_batch_product table. Pay attention to the joint index order. (amount is also added to the index in order to use the covering index)
If there are no other queries for yd_batch_product, consider deleting all single-column indexes on the table.
yd_stock table is jointly indexed on the forbidden/store/chainID column (note the index order).
yd_order table creates a single column index on the deleted column.
yd_batch table creates a single column index on the createdDate column.
Based on the current analysis, the above optimization can be done.
Since there is no data sheet for testing, please correct me if there are any errors.