Python Chinese coding
In the previous chapter, we have learned how to use Python to output "Hello, World!". There is no problem in English, but if you output the Chinese characters "Hello, World", you may encounter Chinese characters. Encoding issues.
If no encoding is specified in the Python file, an error will appear during execution:
print "Hello, world";
The execution output of the above program is:
SyntaxError: Non-ASCII character '\xe4' in file test. py on line 2, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
The default encoding format in Python is ASCII format. Chinese characters cannot be printed correctly without modifying the encoding format, so an error will be reported when reading Chinese.
The solution is to just add # -*- coding: UTF-8 -*- or #coding=utf-8 at the beginning of the file.
Instance
#!/usr/bin/python # -*- coding: UTF-8 -*- print "你好,世界";
Run Instance»
Click the "Run Instance" button to view the online instance
The output result is:
So if you find that the code contains Chinese during the learning process, you need to specify the encoding in the header.
Note: Python3.X source code files use UTF-8 encoding by default, so Chinese can be parsed normally without specifying UTF-8 encoding.
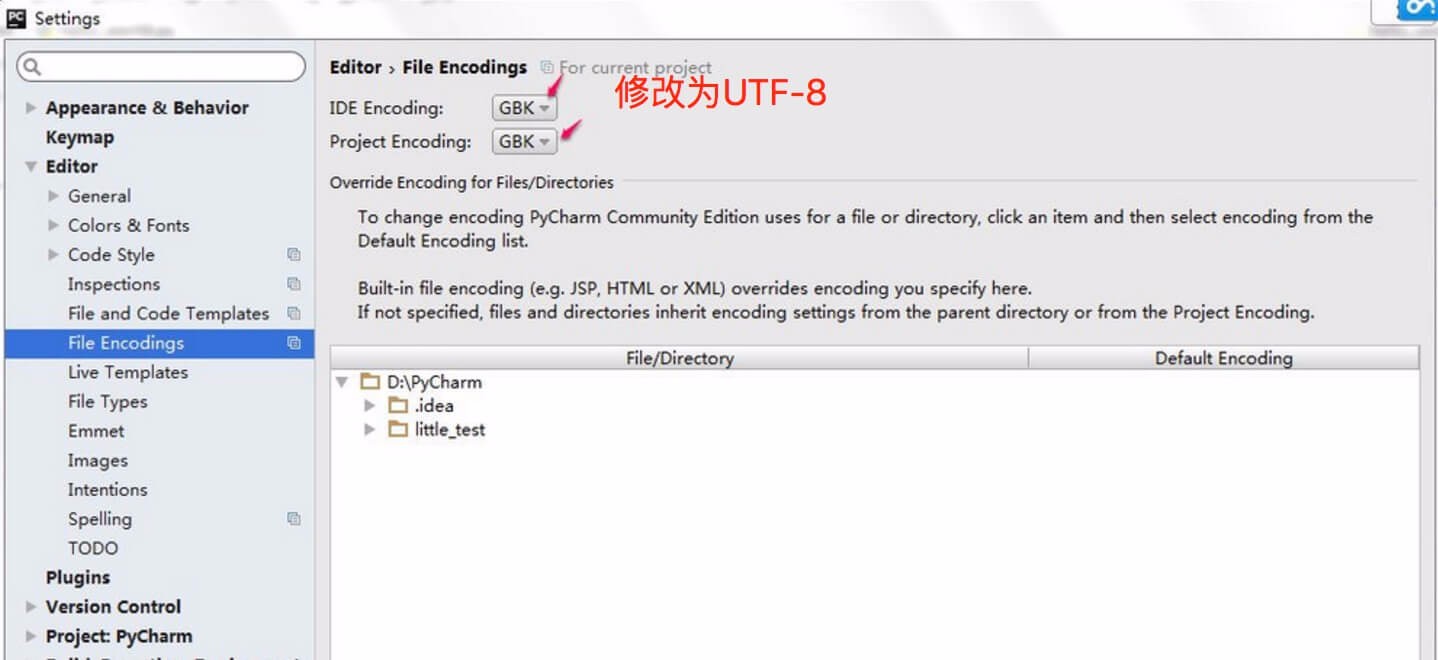
Note: If you use an editor, you also need to set the encoding of the editor, such as Pycharm setting steps:
Enter file > Settings, search for encoding in the input box.
Find Editor > File encodings, and set IDE Encoding and Project Encoding to utf-8.