
- masyarakat
- Belajar
- Perpustakaan Alatan
- Masa lapang
Rumah > Soal Jawab > teks badan
在70W的数据中,执行 'name': /Mamacitas / 需要17.358767秒才完成
数据内容例:
{
"Attitude_low": NumberInt(0),
"Comments": "i",
"file": [
"mamacitas-7-scene3.avi",
"mamacitas-7-scene4.avi",
"mamacitas-7-scene5.avi",
"mamacitas-7-scene2.avi",
"mamacitas-7-scene1.avi",
"14968frontbig.jpg",
"[000397].gif",
"mamacitas-7-bonus-scene1.avi",
"14968backbig.jpg"
],
"Announce": "http://exodus.desync.com/announce",
"View": NumberInt(0),
"Hash": "9E3842903C56E8BBC0C7AF7A0A8636590491923C",
"name": "Mamacitas 7[SILVERDUST]",
"Encoding": "!",
"EntryTime": 1403169286.9712,
"Attitude_top": NumberInt(0),
"CreatedBy": "ruTorrent (PHP Class - Adrien Gibrat)",
"CreationDate": NumberInt(1365851919)
}
关于索引部分: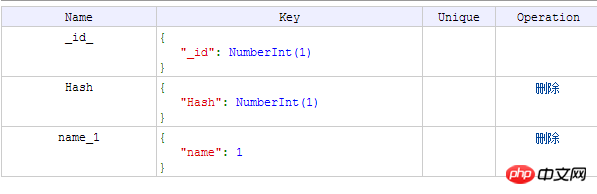
请问我该如何提高匹配速度?

怪我咯2017-04-24 09:11:39
Indeks jenis cincang tidak berguna apabila menggunakan pertanyaan kabur Anda benar-benar perlu bergantung pada enjin carian untuk membina indeks secara khusus selepas pembahagian perkataan
Salah satunya ialah menggunakan sesuatu seperti carian elastik dan membina carian khusus
Anda juga boleh mempertimbangkan untuk menggunakan pustaka pembahagian perkataan untuk membahagikan medan anda kepada perkataan, dan kemudian menggunakan mongodb untuk mencipta koleksi pembahagian perkataan Anda boleh menggunakan mekanisme pengindeksan lalai mongodb

天蓬老师2017-04-24 09:11:39
Anda boleh mencuba Indeks Teks MongoDB Nampaknya anda hanya mahu memadankan perkataan yang lengkap, yang sama dengan senario aplikasi indeks jenis ini.

PHPz2017-04-24 09:11:39
Anda boleh menggunakan Lucence/Sphinx digabungkan dengan MongoDb untuk melakukan pertanyaan carian kecekapan pertanyaan Mongodb memang agak rendah
