
- masyarakat
- Belajar
- Perpustakaan Alatan
- Masa lapang
Rumah > Soal Jawab > teks badan
import urllib2
opener = urllib2.build_opener()
html = None
response = None
response = opener.open('http://www.sxxrcs.com/was5/web/')
html = response.code
print html比如这个爬虫,输出状态码是200。
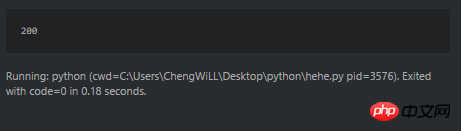
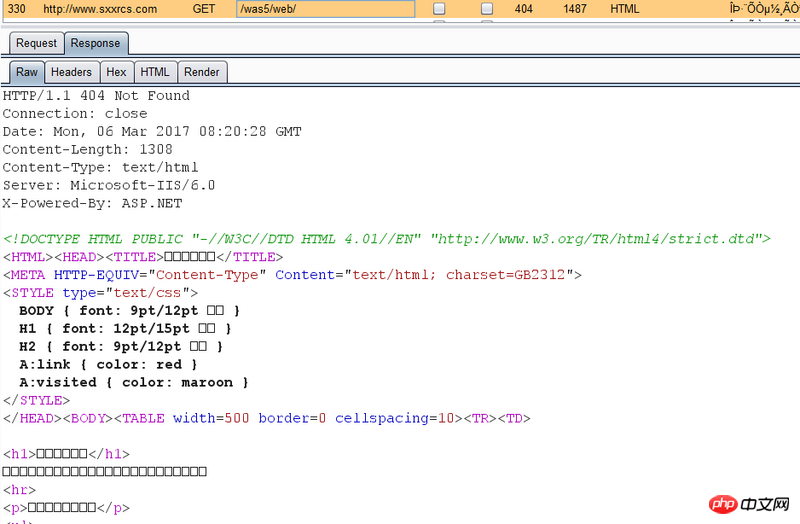
可是直接访问http://www.sxxrcs.com/was5/web/是404,抓包响应的也是404,请问这是为什么?

伊谢尔伦2017-04-18 10:26:31
Gunakan permintaan
import requests
r = requests.get('http://www.sxxrcs.com/was5/web/')
print r.status_code
print r.text
