
- masyarakat
- Belajar
- Perpustakaan Alatan
- Masa lapang
Rumah > Soal Jawab > teks badan
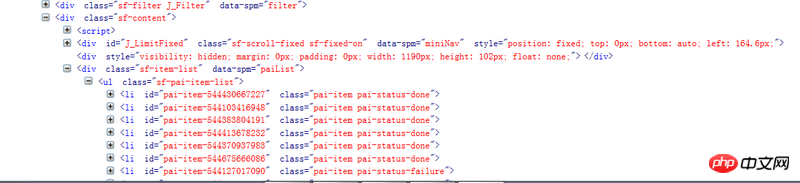
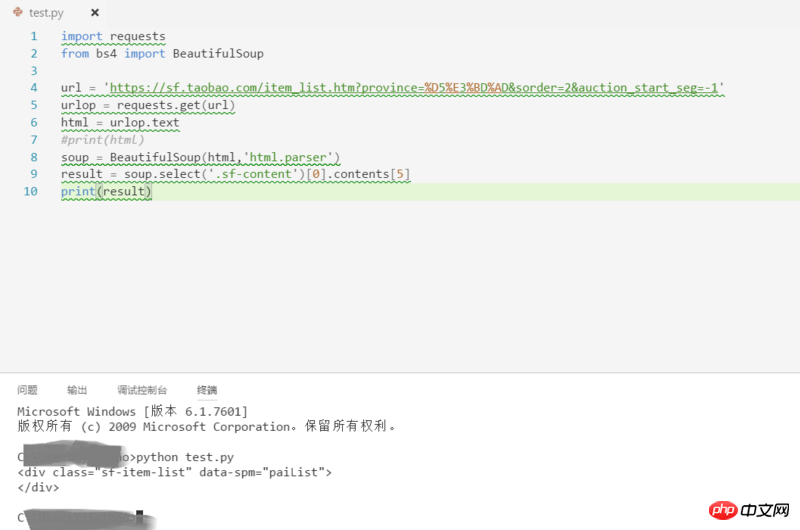
待解析页面的部分代码如第一幅图所示,我自己写的代码及运行结果如第二幅图所示。看到已经有答主提问解析页面丢失是因为用的是lxml的解析方式,我想说我一直用的是html.parser的方式。希望各位大神不吝赐教~

ringa_lee2017-04-18 10:20:51
Pernahkah anda mempertimbangkan pemuatan dinamik dengan javascript?

伊谢尔伦2017-04-18 10:20:51
Penanya, jika anda menggunakan Chrome F12 untuk melihatnya, akan ada kandungan yang dimuatkan secara dinamik dan anda tidak boleh mendapatkan kandungan ini dengan meminta terus URL halaman tersebut. Anda disyorkan untuk mengklik kanan untuk melihat kod sumber halaman web dan membandingkannya dengan kandungan dalam F12 Jika tiada kandungan dalam kod sumber, semak permintaan lain dalam Rangkaian untuk melihat jika terdapat sebarang data anda perlukan.
