
- masyarakat
- Belajar
- Perpustakaan Alatan
- Masa lapang
Rumah > Soal Jawab > teks badan
def save_file(boy,girl,count):
file_name_boy = 'boy' + str(count) + '.txt'
file_name_girl = 'girl' + str(count) + '.txt'
boy_file = open(file_name_boy, 'w')
girl_file = open(file_name_girl, 'w')
boy_file.writelines(boy)
girl_file.writelines(girl)
boy_file.close()
girl_file.close() #把两人的对话分别放到命名不同的文件里
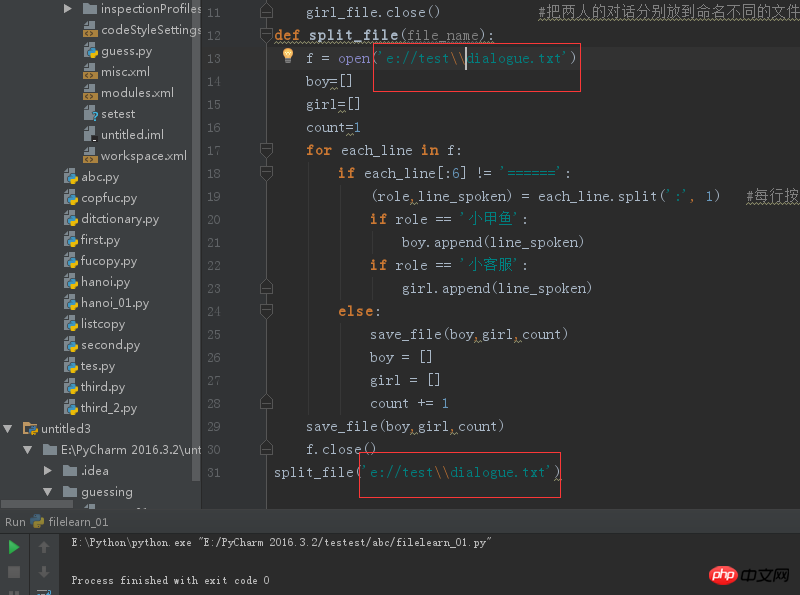
def split_file(file_name):
f = open('E:/test/dialogue.txt')
boy=[]
girl=[]
count=1
for each_line in f:
if each_line[:6] != '======':
(role,line_spoken) = each_line.split(':', 1) #每行按照:分割成1+1个子字符串,分别赋值给=前面的对象
if role == '小甲鱼':
boy.append(line_spoken)
if role == '小客服':
girl.append(line_spoken)
else:
save_file(boy,girl,count)
boy = []
girl = []
count += 1
save_file(boy,girl,count)
f.close()
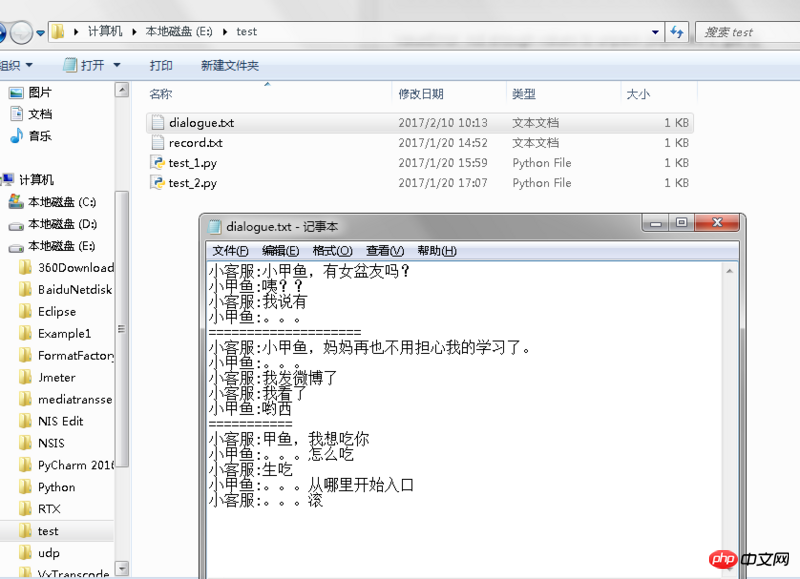
split_file('E:/test/dialogue.txt')E:\Python\python.exe "E:/PyCharm 2016.3.2/testest/abc/filelearn_01.py"
Process finished with exit code 0http://edu.csdn.net/course/de... 是这个视频里的

天蓬老师2017-04-18 10:20:13
Kata kunci carian telah berjaya ditemui dalam persekitaran kerja
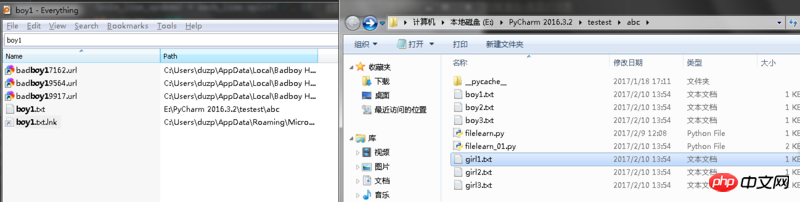
Selain itu, 'e:test/dialogue.txt' digunakan sebagai bekas//, yang terakhir boleh menjadi//atau atau/atau apabila bekas/; , yang terakhir hanya boleh digunakan secara bersendirian.
Jika anda berminat, anda boleh mencubanya dan beritahu saya mengapa

PHPz2017-04-18 10:20:13
Mesej ralat tidak disiarkan dengan baik Nampaknya ralat ini disebabkan oleh kod ini (peranan, line_spoken) = each_line.split(':', 1)
Apabila pembolehubah each_line tidak mengandungi:, an ralat akan berlaku

阿神2017-04-18 10:20:13
Isu pengekodan akan memberi impak yang lebih besar dalam python2, jadi beri perhatian khusus
Pengekodan lalai semasa menyimpan dalam Notepad di bawah Windows ialah GBK, manakala python2 memprosesnya mengikut unikod, jadi apabila membuka fail, disyorkan untuk menukar pengekodan kepada unikod terlebih dahulu untuk mengelakkan lebih banyak masalah;
Selain itu, aksara baris baru dalam Notepad ialah "n". watak baris baru
Langkah seterusnya ialah kes perbandingan peranan Cina == 'Penyu Kecil' Anda masih perlu memberitahu python bahawa anda menggunakan rentetan unicode, supaya anda boleh melakukan perbandingan dengan agak tepat.
def split_file(file_name):
f = open('E:/test/dialogue.txt')
boy=[]
girl=[]
count=1
for each_line in f:
each_line = each_line.strip().decode('gbk') # strip()方法用来去掉"\n";decode()方法用来把编码从gbk解码到unicode
if each_line[:6] != '======':
# (role,line_spoken) = each_line.split(':', 1) #每行按照:分割成1+1个子字符串,分别赋值给=前面的对象
(role,line_spoken) = each_line.split(u':', 1) #注意这里的冒号是中文的冒号,u是告诉python这是个unicode的字符串
# if role == '小甲鱼':
if role == u'小甲鱼':
boy.append(line_spoken)
# if role == '小客服':
if role == u'小客服':
girl.append(line_spoken)
else:
save_file(boy,girl,count)
boy = []
girl = []
count += 1
save_file(boy,girl,count)
f.close()
高洛峰2017-04-18 10:20:13
Saya rasa ini soal lebar penuh atau separuh lebar.
Tetapi kaedah anda tidak sesuai untuk toleransi kesalahan.
Cadangan saya ialah:
split_result = each_line.split(':', 1)
if len(split_result) < 2:
raise RuntimeError()
(role,line_spoken) = (split_result[0], split_result[1])