
- masyarakat
- Belajar
- Perpustakaan Alatan
- Masa lapang
Rumah > Soal Jawab > teks badan
http://apk.hiapk.com/appinfo/...
我想要爬取这个网页中的用户评论
但是却发现使用urllib2.urlopen(request)获取的html页面不完整
代码如图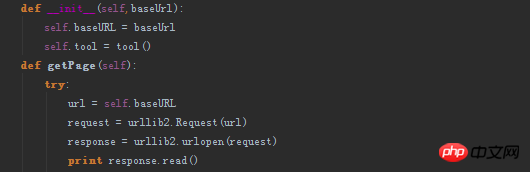

输出如图
但是实际上这个页面里面是有东西的
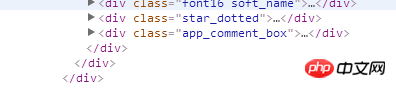
请问一下为什么获取到的html不全呢

PHP中文网2017-04-18 09:58:27
Bukannya perolehan tidak lengkap Komen pada halaman ini dijana melalui javascript post-loading html yang diminta dikembalikan dalam urllib2.urlopen dan javascript dalam halaman tidak akan dilaksanakan
.Anda boleh terus meminta http://apk.hiapk.com/web/api.... Alamat ini boleh mengembalikan semua komen, dan ia masih json, yang sangat mudah dikendalikan
