
- masyarakat
- Belajar
- Perpustakaan Alatan
- Masa lapang
Rumah > Soal Jawab > teks badan
目标url:
http://www.xiaopian.com/html/...
这个是chrome里显示的源代码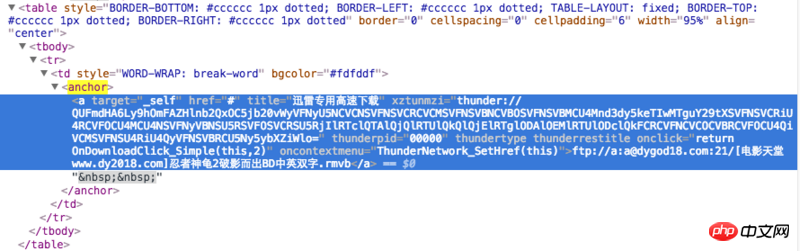
这个是scrapy shell url后用response.css().extract()显示东西
我想知道为何二者不一致?scrapy爬取到的信息并没有对应的thunder链接,而是明面上的ftp链接

黄舟2017-04-18 09:43:53
Untuk melihat kod sumber halaman web, perangkak harus mengklik kanan > daripada kod asal, dan kod yang diperolehi oleh perangkak bukan Diberikan oleh js, iaitu kod asal.
Saya melihat dan mendapati bahawa alamat muat turun Thunder telah dikira oleh js
Kod khusus adalah seperti berikut:
function ThunderEncode(t_url) {
var thunderPrefix = "AA";
var thunderPosix = "ZZ";
var thunderTitle = "thunder://";
var thunderUrl = thunderTitle + base64encode(utf16to8(thunderPrefix + t_url + thunderPosix));
return thunderUrl;
}Mengujinya:
Masukkan alamat ftp://a:a@dygod18.com:21/[电影天堂www.dy2018.com]忍者神龟2破影而出BD中英双字.rmvb sebagai parameter dan anda akan mendapat sambungan Thunder, tetapi ia tidak sama dengan yang terdapat pada halaman web Selepas penyahkodan, ia mengekodkan URL bahasa Cina aksara. Selagi pengekodan disatukan, Tiada masalah.
