- masyarakat
- Belajar
- Perpustakaan Alatan
- Masa lapang
Rumah > Soal Jawab > teks badan
根据网页所给的字符编码将其字节数据decode('gb2312')
用的是scrapy,从给出的url获取body
def parse(self, response):
body = response.body.decode('gb2312')
print(body)
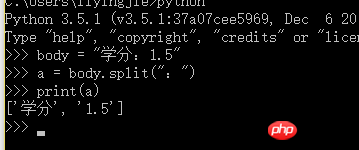
学分:1.5 # body就是这样之类的,中间的冒号是中文的冒号
# 想弄成的效果就是['学分','1.5']
body = body.split(':') # 就这样使用中文的冒号符来分割,但是出错
SyntaxError: (unicode error) 'utf-8' codec can't decode byte 0xa3 in position 0: invalid start byte
请问怎么解决?

大家讲道理2017-04-18 09:06:39
# Saya cuba melakukan ini
print(body.encode('gb2312'))
print(body.encode('utf-8'))
Outputnya adalah seperti berikut:
b'\xb3\xd0\xb5\xa3\xb5\xa5\xce\xbb\xa3\xba\xd5\xfe\xb7\xa8\xd1\xa7\xd4\xba'
b'\xe6\x89\xbf\xe6\x8b\x85\xe5\x8d\x95\xe4\xbd\x8d\xef\xbc\x9a\xe6\x94\xbf\xe6\xb3\x95\xe5\xad\xa6 \xe9\x99\xa2'
#Biar dua keputusan masing-masing ialah gb2312 dan utf8.
>>> gb2312.decode('utf-8')
Traceback (panggilan terbaharu terakhir):
Fail "<stdin>", baris 1, dalam <modul>
UnicodeDecodeError: codec 'utf-8' tidak boleh menyahkod bait 0xb3 dalam kedudukan 0: bait mula tidak sah
Melihat ralat di atas sekali lagi, ia ialah bait 0xa3
Jadi saya mencubanya beberapa kali pada terminal dan mendapati bahawa kolon ialah pengekodan gb2312
>>> b'\xa3\xba'.decode('gb2312')
':'
Jadi sepatutnya python menggunakan utf-8 lalai untuk menyahkod badan gb2312, jadi satu cara yang boleh saya fikirkan ialah mengubah suai nilai pengekodan lalai, iaitu pernyataan pada baris pertama: # -*- pengekodan: gb2312 -*-
Kemudian operasi itu berjaya.


伊谢尔伦2017-04-18 09:06:39
Selepas penyahkodan, badan hendaklah dikodkan unikod, gunakan kaedah berikut:
body = body.split(u':')
PHP中文网2017-04-18 09:06:39
Isu pengekodan lain, anda boleh merujuk kepada: Pengekodan Aksara untuk Interaksi Manusia-Komputer dan Kalahkan Pengekodan Aksara Python dalam Lima Minit.
#! /usr/bin/env python
# -*- pengekodan: utf-8 -*-
# Tiru data yang anda dapat daripada halaman web
data = "Kredit: 1.5".decode("utf-8").encode('gb2312')
# data = u"Kredit: 1.5".encode('gb2312')
jenis cetakan(data)
badan = data.decode('gb2312')
print type(body) #unicode type
# Dua penyelesaian
print body.split(u':') #unicode sepadan dengan unicode
print body.encode("utf-8").split(":") # utf-8 sepadan dengan utf-8