python - scrapy无法抓取css选择器指定的内容
我在ubuntu14.04上工作,使用google chrome浏览器。想使用scrapy(1.0)把拉勾网上有关python的工作都爬一遍,但是得不到想要的结果。代码如下
#!/usr/bin/python
# -*- coding: utf-8 -*-
#Filename: dmoz_spider.py
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
start_urls = [
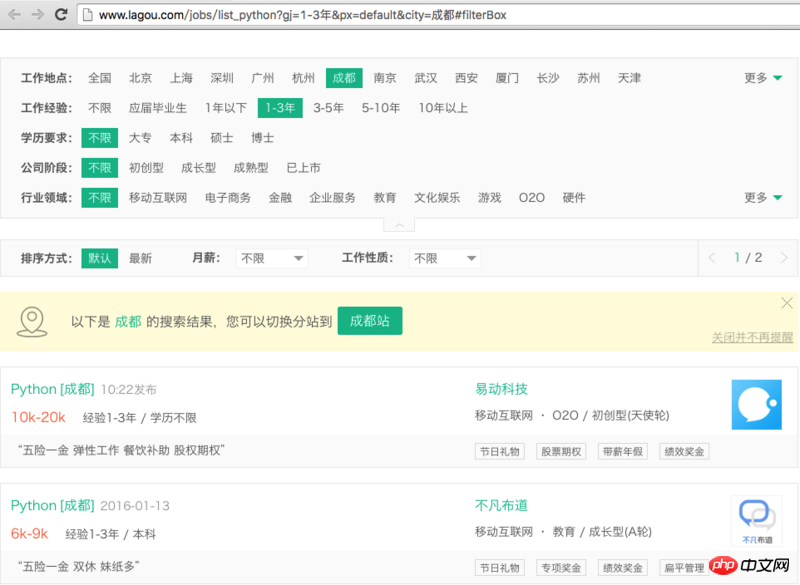
'http://www.lagou.com/jobs/list_python?gj=1-3%E5%B9%B4&px=default&city=%E6%88%90%E9%83%BD#filterBox'
]
def parse(self, response):
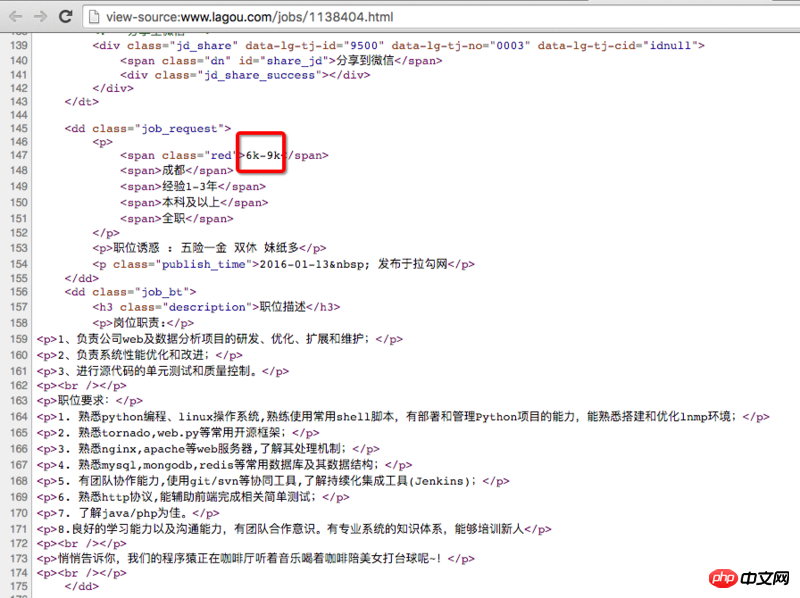
total = response.css('.money').extract()
print('note:', total)
for res in total:
print(res)这里是拉勾网的地址,地点成都,python相关
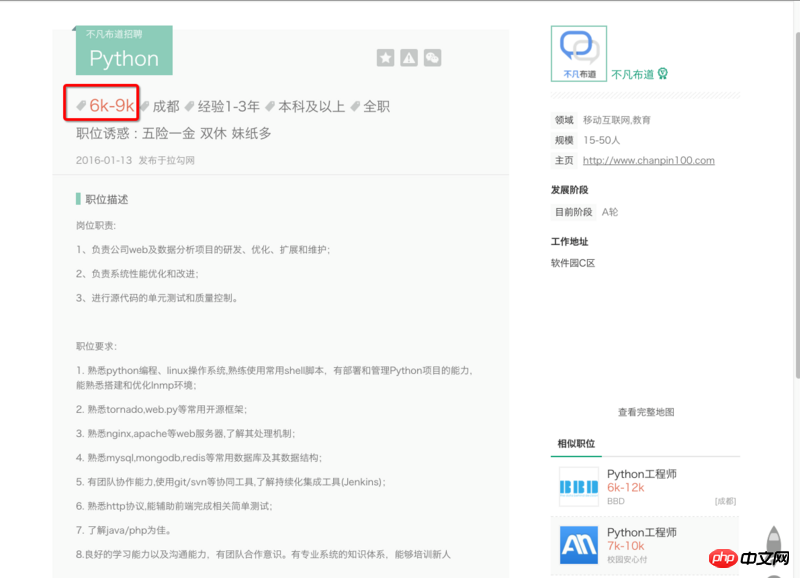
我想要获取的内容如下:"6k-9k" 即每个岗位的薪资
使用chrome的一个插件SelectorGadgets得到了要抓取的内容的css selector表达hi为.money。然后在终端用命令scrapy crawl dmoz开始启动爬虫,但是却没有得到任何结果,请教各位大神,这是怎么回事?
PS:该selector在chrome的F12工具里都可以正确地选出内容。