
- masyarakat
- Belajar
- Perpustakaan Alatan
- Masa lapang
Rumah > Soal Jawab > teks badan
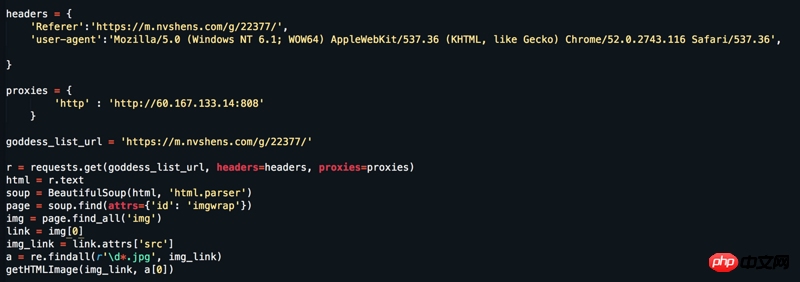
Laman web: https://www.nvshens.com/g/22377/ Buka laman web terus dengan penyemak imbas dan kemudian klik kanan pada imej untuk memuat turunnya kemudian saya Saya menukar tajuk dan menyediakan proksi IP, tetapi ia masih tidak berfungsi. Tetapi melihat pada tangkapan paket, ia bukan data yang dimuatkan secara dinamik! ! ! Sila jawab = =
过去多啦不再A梦2017-06-12 09:29:51
Gadis itu agak cantik.
Ia memang boleh dibuka dengan klik kanan, tetapi selepas disegarkan, ia menjadi gambar hotlink. Secara amnya, untuk mengelakkan hotlinking, pelayan akan menyemak sama ada Referer字段,这就是为什么刷新后就不是原图的原因(刷新后Referer dalam pengepala permintaan telah berubah). 
img_url = "https://t1.onvshen.com:85/gallery/21501/22377/s/003.jpg"
r = requests.get(img_url, headers={'Referer':"https://www.nvshens.com/g/22377/"}).content
with open("00.jpg",'wb') as f:
f.write(r)

欧阳克2017-06-12 09:29:51
Adakah anda terlepas sebarang parameter dengan menangkap paket semasa mendapatkan gambar?
我想大声告诉你2017-06-12 09:29:51
Saya hanya melihat kandungan laman web dan hampir terlupa bahawa ia adalah rasmi.
Anda boleh mengikuti semua maklumat yang anda minta

Kemudian cubalah
女神的闺蜜爱上我2017-06-12 09:29:51
Referer Mengikut reka bentuk laman web ini, setiap halaman harus lebih sesuai dengan tingkah laku berlagak seperti manusia, bukannya menggunakan satu Referer
Berikut adalah kod lengkap yang boleh dijalankan untuk menangkap semua gambar di muka surat 18
# Putting all together
def url_guess_src_large (u):
return ("https://www.nvshens.com/img.html?img=" + '/'.join(u.split('/s/')))
# 下载函数
def get_img_using_requests(url, fn ):
import shutil
headers ['Referer'] = url_guess_src_large(url) #"https://www.nvshens.com/g/22377/"
print (headers)
response = requests.get(url, headers = headers, stream=True)
with open(fn, 'wb') as out_file:
shutil.copyfileobj(response.raw, out_file)
del response
import requests
# 用xpath擷取內容
from lxml import etree
url_ = 'https://www.nvshens.com/g/22377/{p}.html'
headers = {
"Connection" : "close", # one way to cover tracks
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2900.1 Iron Safari/537.36}"
}
for i in range(1,18+1):
url = url_.format(p=i)
r = requests.get(url, headers=headers)
html = requests.get(url,headers=headers).content.decode('utf-8')
selector = etree.HTML(html)
xpaths = '//*[@id="hgallery"]/img/@src'
content = [x for x in selector.xpath(item)]
urls_2get = [url_guess_src_large(x) for x in content]
filenames = [os.path.split(x)[0].split('/gallery/')[1].replace("/","_") + "_" + os.path.split(x)[1] for x in urls_2get]
for i, x in enumerate(content):
get_img_using_requests (content[i], filenames[i])